import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
print(f'numpy: {np.__version__}')
print(f'pandas: {pd.__version__}')
print(f'scikit-learn: {sklearn.__version__}')numpy: 2.2.6
pandas: 2.3.3
scikit-learn: 1.7.2
1선형 회귀¶
선형회귀는 1805년 라그랑제와 1809년 가우스가 천문학에서 행성 위치를 예상하기 위해 처음 사용되었습니다. 이후 여러 학문에서 이 기법을 활용하면서 유명해졌고, 현재까지도 널리 활용되고 있습니다. 다른 명칭으로는 ‘최소제곱법’, 영어 Ordinary Least Square, 줄여서 OLS라고도 부릅니다. 하지만 최소제곱법이 선형회귀에만 사용되는 것은 아니기 때문에 기술적으로는 두 가지가 동의어라고 하기는 어렵습니다. 하지만 많이들 그렇게 부르고 있습니다.
‘회귀’라는 단어는 Regression의 번역으로 사용되는데, 둘다 ‘돌아가다’라는 의미 정도입니다. 1875년 프란시스 갈톤의 연구에서, 키가 특별히 크거나 작은 부모의 자식이라도 전반적으로는 ‘평균으로 회귀’한다는 것을 보여주었는데, 이 연구에서 평균키 추세선을 형성하는데 선형 회귀가 사용되면서 그 이후 회귀라는 단어가 현재의 의미로 자리잡았습니다. 현재는 원래 의미보다는, 분류 유형과 대비되는 연속적인 출력 값을 예측한다는 뜻으로 사용되는 편입니다.
1.1예측 모형¶
선형 모델의 가장 간단한 예측 모형은 직선입니다. 입력이 1차원이면 그에 대응하는 기울기도 1차원이라 그렇습니다. 편향은 직선의 절편입니다. 선형 회귀는 예측 모형을 따라 입력에 대한 출력을 결정합니다. 선형 분류기는 예측 모형을 유형을 분류하는 결정 경계로 활용합니다.
특징이 두 개인 2차원 데이터는 대응되는 가중치가 두 개입니다. 이 경우, 예측 모형은 3차원 공간의 평면입니다. 이러한 평면을 기준으로 출력이 결정됩니다. 3차원 공간에서 그려진 평면은 직선은 아니지만 여전히 선형적입니다. 해당 평면의 기울기는 w1, w2로 결정되고, 평면의 절편은 b입니다.
3차원 이상의 데이터셋은 사차원 이상의 공간에서 초평면으로 표현됩니다. 초평면은 시각화하기 어렵지만, 직선과 평면은 그것의 하위 집합입니다. 초평면은 일반적인 선형 함수입니다.
N차원 선형 예측 모형은 선형대수의 내적을 활용하면 보다 간결하게 표기할 수 있습니다.
선형 모델을 보다 일반적으로 표기하면, 입력과 입력에 적용되는 가중치, 편향의 함수라고 할 수 있습니다. 가중치와 편향은 매개변수라고 합니다.
선형 모델의 출력은 매개변수로 결정됩니다. 그렇기 때문에 매개변수는 출력에 대한 해법이라고 할 수 있습니다. 따라서, 이것이 학습의 목표입니다. 즉, 주어진 데이터 집합에 대해 최적의 매개변수를 찾는 것이 곧 학습입니다.
이전과 마찬가지로 일 차원의 간단한 데이터를 생성해 살펴 보겠습니다. 가장 간단한 직선을 바탕으로 하면서 잡음을 추가합니다. 잡음을 추가 할 때, 난수 초기값을 설정하겠습니다. 생성된 데이터에 대해서 산포도 그래프를 그려 보겠습니다.
x = np.linspace(-5, 5, 100)
random = np.random.RandomState(1)
noise = random.randn(len(x))
y = x + noise
plt.scatter(x, y)
plt.plot(x, y - noise, 'k')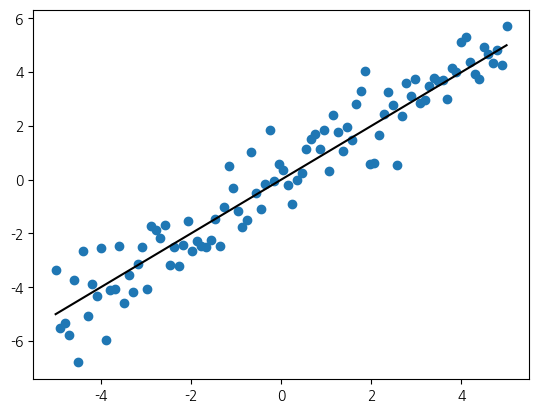
편의를 위해 모델 평가 함수를 좀더 개량하겠습니다. 입력 X는 디자인 행렬의 형상이 되어야 합니다. 가끔 우리가 개념을 확인할 때, 시각화를 위해 일 차원 데이터를 종종 형성합니다. 그래서 일 차원 데이터인 경우 디자인 행렬로 구성하는 부분을 추가 합니다. 그리고 지금으로써는 이 차원의 디자인 행렬 형상을 입력으로 가정합니다. 또한, 탐색적 데이터 분석을 위해 훈련과 시험 데이터 분리를 직접 하는 경우가 있습니다. 그래서 이제는 훈련 시험 데이터가 분리된 결과를 받아볼 수 있도록 설정하겠습니다. 기본적으로는 예전처럼 동작하도록 하면서 우리가 추가적으로 설정 하는 경우에만 데이터를 반환하도록 하겠습니다.
결과 함수는 예전과 완벽하게 동일하게 동작하면서 추가적인 기능이 포함되어 있습니다. 그래서 개량된 모델 평가 함수를 이전에 적용한다고 해도 이전 코드는 그대로 동작합니다.
from sklearn.model_selection import train_test_split
def 모델평가(model, X, y, return_split=False, print_scores=False, **설정):
if X.ndim == 1:
X = X.reshape(-1, 1)
assert X.ndim == 2
X_train, X_test, y_train, y_test = train_test_split(X, y, **설정)
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
if print_scores:
print(f'훈련: {train_score:.3f}, 시험: {test_score:.3f}')
if return_split:
return {'train': train_score, 'test': test_score}, (X_train, X_test, y_train, y_test)
return {'train': train_score, 'test': test_score}생성된 데이터셋에 선형회귀를 적용해 보겠습니다. 이번에는 싸이킷런의 linear_model 패키지에서 가져옵니다.
모델은 다르지만 모델 평가를 활용하는 방법은 동일합니다. 이번에는 시각화를 비롯한 탐색적 데이터 분석이 필요하기 때문에 모델 평가 함수의 추가 설정을 활용하겠습니다. 또한, 선형 모델의 예측 방식을 kNN과 비교 분석하기 위해 섞지 않고 훈련 시험 데이터를 생성하겠습니다.
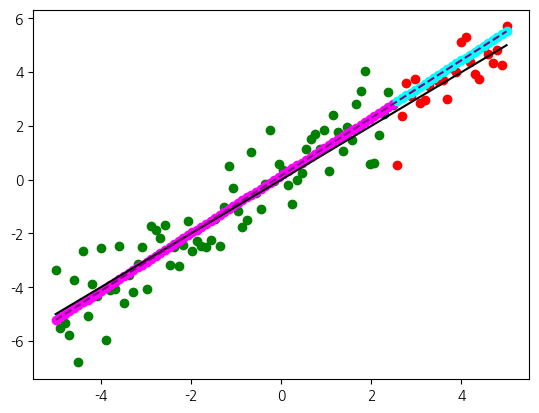
훈련 결과, 훈련 성능 0.87, 시험 성능0.48이고, 이 값은 회귀 성능 평가이기 때문에 R2 지표값입니다.
결과를 이해하기 위해서 예측을 그래프로 표현해 보겠습니다. 훈련과 시험 데이터의 정답과 예측을 산포도 그래프로 그립니다. 예측은 훈련된 선형 회귀 모형으로부터 획득합니다. 각각을 색상으로 구분하여 표시합니다.
훈련된 선형 모델은 기울기와 절편을 내부적으로 학습합니다. 기울기와 절편을 매개변수라고 부르겠습니다. 매개변수를 가져와서 직선을 그리고 원래의 직선과도 비교해보겠습니다. 두 직선을 비교하면 완벽하게는 아니지만 상당히 일치하는 것을 확인할 수 있습니다. 즉, 훈련 결과 선형 회귀는 이러한 직선을 예측 모형으로 형성했다고 할 수 있습니다. 그래서 훈련과 시험 데이터에 대한 예측이 이러한 직선의 모형 위에서 이루어집니다. 훈련 데이터로 학습한 결과 형성된 직선을 따라서 새로운 범위의 입력에 대해서도 예측을 수행합니다.
시각적으로 보기에는 예측이 원래의 직선에 대해서 상당히 유사하게 수행되는 것을 확인할 수 있고 그 결과 훈련 데이터에 대해서 높은 수준의 예측 성능을 보입니다. 물론 잡음이 섞여 있기 때문에 이 점수가 직선으로는 백점이 불가능합니다. 그런데 비교해서 시험 데이터의 양상도 비슷하고, 그렇기 때문에 그에 대한 예측 성능도 비슷해야 할 것 같지만 차이가 많아서 조금 의아합니다. 그 이유는 R2 지표의 계산 방식과 연관이 있습니다. 단위를 1.0 이내로 정규화 하기 위해서 정답과 평균의 차이 합계로 나누어 주는데 상대적으로 시험 데이터의 개수가 적어서 평균값 자체가 훈련 데이터에 대비해서 덜 안정적입니다.
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
result, (X_train, X_test, y_train, y_test) = 모델평가(linreg, x, y, return_split=True, print_scores=True, shuffle=False, test_size=0.25)
plt.scatter(X_train, y_train, c='green')
plt.scatter(X_test, y_test, c='red')
plt.scatter(X_train, linreg.predict(X_train), color='magenta')
plt.scatter(X_test, linreg.predict(X_test), color='cyan')
w = linreg.coef_
b = linreg.intercept_
print(f'w: {w[0]:.2f}, b: {b:.2f}')
f = lambda x: w * x + b
plt.plot(x, y - noise, 'black')
plt.plot(x, f(x), color='purple', linestyle='--')훈련: 0.863, 시험: 0.482
w: 1.07, b: 0.15
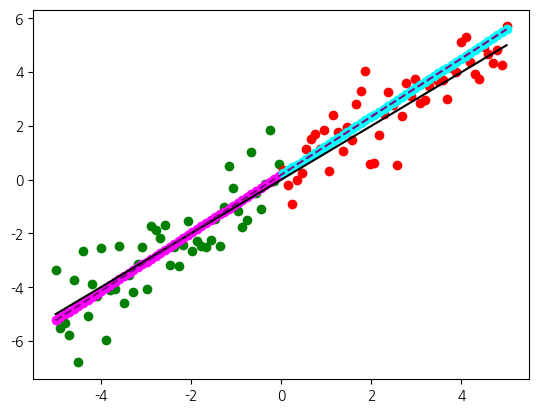
같은 코드를 훈련과 시험 데이터를 반반으로 해서 살펴보겠습니다. 이 경우 형성된 매개변수 값은 거의 비슷합니다. 거의 같은 매개변수로 예측 모형이 형성되었지만, 이번에는 훈련과 시험 데이터의 점수가 서로 매우 유사합니다. 물론 훈련 데이터의 점수가 상당히 하락했는데, 역시 그 이유는 상대적으로 데이터가 적어지면서 평균값 자체가 바뀌기 때문이기도 합니다. 즉, 예측 모형은 거의 동일하기 때문에 점수의 변화가 예측의 품질의 기인한 것이라고 보기 어렵습니다. 단지 데이터의 규모에 따라서 지표값이 달라졌습니다. 이런 분석을 통해서 성능을 평가할 때 데이터의 규모도 신중하게 고려해야 한다는 점을 염두에 두겠습니다.
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
result, (X_train, X_test, y_train, y_test) = 모델평가(
linreg, x, y, return_split=True, print_scores=True, shuffle=False, test_size=0.5)
plt.scatter(X_train, y_train, c='green')
plt.scatter(X_test, y_test, c='red')
plt.scatter(X_train, linreg.predict(X_train), color='magenta')
plt.scatter(X_test, linreg.predict(X_test), color='cyan')
w = linreg.coef_
b = linreg.intercept_
print(f'w: {w[0]:.2f}, b: {b:.2f}')
f = lambda x: w * x + b
plt.plot(x, y - noise, 'black')
plt.plot(x, f(x), color='purple', linestyle='--')훈련: 0.729, 시험: 0.738
w: 1.08, b: 0.18
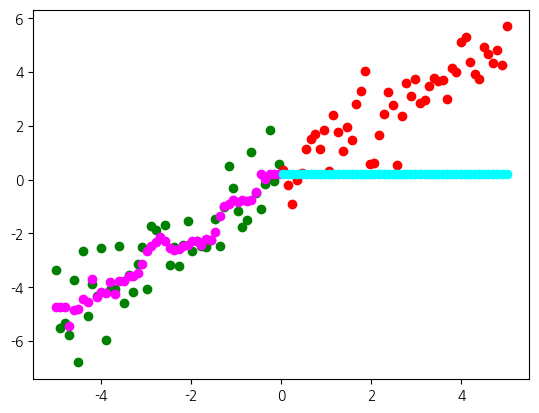
최근접 이웃 알고리즘을 같은 데이터에 대해서 훈련하고 예측을 비교하면서 살펴보겠습니다. 이웃수는 기본값 5로 하겠습니다. 모델 평가에서 같은 설정을 활용하겠습니다. 훈련 점수는 선형 모델과 유사한데, 시험 점수는 우리가 이전에 분석한 대로 마지막 훈련 데이터로 예측을 하기 때문에 결과가 매우 좋지 않습니다. 최근접 이웃 알고리즘은 훈련 데이터를 그냥 기억하기 때문에 선형 모델과 달리 매개변수가 없습니다. 보다시피, 훈련 데이터를 기억하는 방식은 새로운 범위의 데이터에 취약합니다. 훈련 데이터를 기억하는 방식의 알고리즘들은 매개변수를 활용하지 않기 때문에 비매개변수 유형으로 분류됩니다.
from sklearn.neighbors import KNeighborsRegressor
kreg = KNeighborsRegressor(n_neighbors=5)
result, (X_train, X_test, y_train, y_test) = 모델평가(kreg, x, y, return_split=True, print_scores=True, shuffle=False, test_size=0.5)
plt.scatter(X_train, y_train, c='green')
plt.scatter(X_test, y_test, c='red')
plt.scatter(X_train, kreg.predict(X_train), color='magenta')
plt.scatter(X_test, kreg.predict(X_test), color='cyan')훈련: 0.773, 시험: -2.264
1.2최적화¶
매개변수를 학습하기 위해서는 어떠한 모형이 다른 것보다 더 나은지 평가하는 기준이 필요합니다. 지도 학습의 목표는 정답에 가능한 가까운 예측을 하는 것입니다. 그래서 정답과 예측의 오차를 최소화하는 과정이 학습이라고 할 수 있습니다. 그렇다면 그러한 오차를 측정하는 방식을 정의해야 합니다. 선형 회귀는 평균 제곱 오차를 활용합니다.
오차는 정답과 예측의 차이로 간단하게 정의할 수 있습니다. 각 표본별로 측정된 오차는 전체적으로 취합될 필요가 있습니다. 즉, 종합 오차를 구해야 합니다. 오차가 양수 음수 모두 가능하기 때문에 취합하기 위해서는 최소한 절대값이 필요합니다. 미분을 활용해 최적화를 수행하는 방식을 선택할 수 있도록 오차를 제곱하여 합계를 구하는 종합 오차를 정의할 수 있습니다. 표본 개수로 정규화하기 위해 표본 수로 나누어 주면 평균제곱오차, Mean Squared Error가 됩니다. 종합 오차는 종종 손실이라고 부릅니다. 이렇게 정의한 손실함수의 매개변수에 대해 해를 구하면 최적의 매개변수를 구할 수 있습니다.
1.2.1손실¶
평균제곱오차를 함수로 정의하여 앞서 훈련한 선형회귀의 예측 손실을 구해보겠습니다. 평균제곱오차는 정답과 예측값의 차이를 구해 제곱한 다음, 그것의 평균을 구하면 됩니다.
선형회귀 모델에서 시험 데이터에 대한 예측을 구하고 정의한 함수를 활용해 그 결과에 대한 손실을 산출합니다. Scikit-Learn 알고리즘은 최적화 시점의 손실을 표시하지 않기 때문에 별도로 구해야 합니다.
그 결과 0에 가깝지만 완전히 0은 아닌 손실을 확인할 수 있습니다. 앞서 인위적으로 생성한 1차원 데이터셋은 직선을 바탕으로 하지만 난수로 잡음을 생성해 섞었기 때문에 직선으로는 완벽하게 최적화가 어렵기 때문입니다.
평균제곱오차산출 = lambda y, y_pred: np.mean((y - y_pred)**2)
y_pred = linreg.predict(X_test)
손실 = 평균제곱오차산출(y_test, y_pred)
손실np.float64(0.6930972097639553)1.2.1.1손실과 성능¶
그런데 이미 성능 평가 지표가 있습니다. 회귀에서는 R2를 사용하고 있습니다. 그런데 왜 또 다른 지표를 도입하는지 궁금할 수 있습니다. 실제로 같은 정답과 예측에 대해서 두 값이 다릅니다.
최적화를 위해서는 최소값이 0이고, 차이가 발생할 수록 값이 증가하는 양상을 보이는 지표가 필요합니다. R2 지표와 같은 성능 지표는 손실과 대략적으로 반대입니다. 최대값이 1.0이 되도록 하였고, 차이가 많이 발생하면 음수가 나올 수 있습니다. 평균제곱오차와 R2는 유사하지만, 학습을 수행할 때는 손실 함수로써 평균 제곱 오차를 활용하고, 학습 완료 후, 성능을 측정할 때는 R2를 활용하는 것입니다.
from sklearn.metrics import r2_score
r2_score(y_test, y_pred)0.73776789229044561.2.2매개변수와 손실¶
학습은 주어진 손실 함수의 출력인 손실을 최소화하기 위해서 노력하는 과정입니다. 현재 선형 회귀에서는 매개변수가 기울기와 절편입니다. 그래서 선형 모형의 학습은 기울기와 절편을 바꿔가면서 손실을 측정합니다. 이러한 과정을 일부 매개변수에 대해서 시각적으로 표현해 보겠습니다.
직선의 기울기는 삼각함수의 탄젠트로 구할 수 있습니다. 그래서 현재 데이터 분포 근처에서 기울기 몇 개를 선택하여 예측 모형을 형성합니다. 절편도 매개변수이지만 현재는 0으로 고정하겠습니다. 각 매개변수 조합에 대해서 평균 제곱 오차로 측정한 손실과 함께 예측 모형인 직선을 출력합니다. 손실을 살펴보니 기울기가 1.0일 때 손실이 가장 낮고 이러한 기울기와 차이가 크면 클수록 손실이 높은 것을 확인할 수 있습니다.
f = lambda x, w, b: w * x + b
b = 0
plt.scatter(x, y)
for w in np.tan((np.pi / 8) * np.arange(0, 4)):
y_pred = f(x, w, 0)
print(f'w: {w:.2f}, b: {b:.2f} --> Loss: {평균제곱오차산출(y, y_pred):.2f}')
plt.plot(x, y_pred)w: 0.00, b: 0.00 --> Loss: 9.85
w: 0.41, b: 0.00 --> Loss: 4.03
w: 1.00, b: 0.00 --> Loss: 0.79
w: 2.41, b: 0.00 --> Loss: 16.99
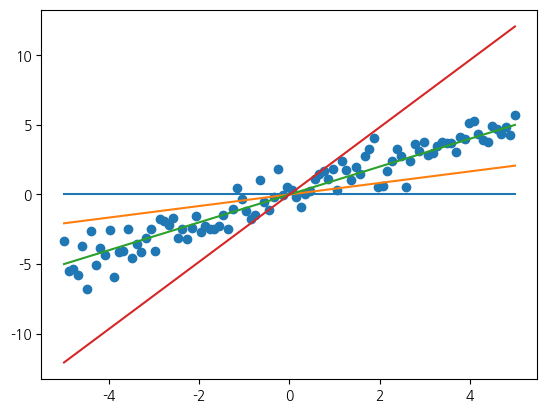
시각적으로 표현할 때는 너무 많은 직선을 그리면 통찰을 얻기가 어렵기 때문에 몇 개만 선별적으로 그렸습니다. 실제로는 가능한 매개 변수들 중에서 어떤 것이 될지 모르기 때문에 매개변수를 좀더 미세하게 조정하면서 손실값 변화 양상을 살펴보겠습니다.
기울기 값을 구할 때 탄젠트 값은 무한대로 발산해 버리는 경우가 있기 때문에 그런 경우를 피해서 그리도록 적절하게 값의 범위를 선택했습니다. 결과적으로 발생한 그래프는 매개변수 값에 따른 손실의 변화 양상이라고 할 수 있습니다. 우리가 원하는 것은 이러한 손실의 최소값을 발생하는 매개 변수를 찾는 것입니다.
분석 편의상, 손실변화를 시리즈 자료구조로 설정했습니다. 현재 구성된 시리즈 자료구조에서 최소값에 대응하는 색인이 곧 최적의 매개 변수입니다. 최적의 매개 변수와 값을 시리즈 자료 구조에서 선택하기 위해서 각각 idxmin과 min API를 활용합니다. 이렇게 획득한 값을 빨간색 점으로 표시했습니다. 앞서 우리가 살펴봤을 때, 알고리즘이 최적 지점에 가까운 매개 변수를 찾은 것을 이미 확인했습니다.
손실변화 = {}
for w in np.tan((np.pi / 8 ) * np.arange(-2.5, 3.4, 0.1)):
y_pred = f(x, w, 0)
손실변화[w] = 평균제곱오차산출(y, y_pred)
손실변화 = pd.Series(손실변화)
손실변화.plot()
plt.plot(손실변화.idxmin(), 손실변화.min(), 'ro')
plt.xlabel('w')
plt.ylabel('loss')
plt.show()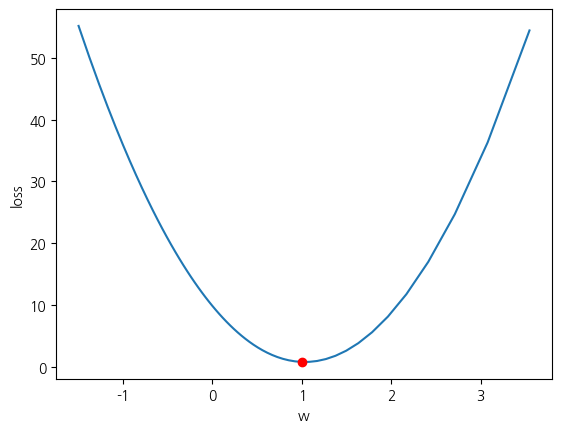
1.2.3최소제곱법¶
최적화를 수행할 때 가능한 모든 범위에 대해 매개변수의 값을 대입하는 방식은 비효율적입니다. 실제로는 선형대수적 연산으로 최적의 매개변수를 산출합니다.
그러한 연산은 정규 방정식의 해를 구하는 것인데, 그것은 scipy 패키지에서 정의가 되어 있습니다. 최소제곱법은 scipy 선형대수 패키지 linalg에서 함수를 가져와서 활용하겠습니다. scipy 패키지는 과학계산용 패키지인데, scikit-learn의 알고리즘들이 연산을 수행할 때 내부적으로 활용합니다.
디자인 행렬 X와 목표값 y를 인자로 전달하면, 최적화 결과를 반환합니다. 그 결과는 최적화된 매개변수를 비롯해 다양한 정보가 담겨있습니다. 최소제곱법 API는 방정식의 해, 즉 최적화된 매개변수를 비롯해 다양한 정보를 반환합니다. 최적화된 매개변수가 반환된 결과의 첫 번째 값인데, 그 나머지는 필요없기 때문에 버리는 변수로써 밑줄로 할당합니다. 나머지 값이 여러 개이기 때문에 별표(*)를 앞에 설정합니다.
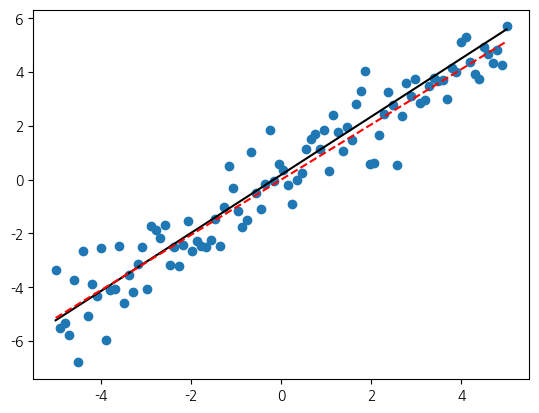
결과를 확인하기 위해 앞서 했던 것처럼 시각화하겠습니다.
선형회귀의 예측과 비교해 보면 거의 유사합니다. 완벽하게 동일하지 않은 이유는 미세한 설정들이 약간 달라서 그런 것인데, 지금은 크게 중요하지 않습니다.
from scipy.linalg import lstsq
w, *_ = lstsq(X_train, y_train)
print(f'y = {w[0]:.2f} * x + 0')
plt.scatter(x, y)
plt.plot(x, linreg.predict(x.reshape(-1, 1)), 'k')
plt.plot(x, f(x, w, 0), 'r--')y = 1.03 * x + 0
2선형 분류기¶
from sklearn.datasets import load_iris
iris = load_iris()y1 = iris.target[:100]
X1 = iris.data[:100]
np.unique(y1)array([0, 1])from sklearn.linear_model import Perceptron
model = Perceptron()
print('train={train:.2%}, test={test:.2%}'.format(**모델평가(model, X1, y1)))train=100.00%, test=100.00%
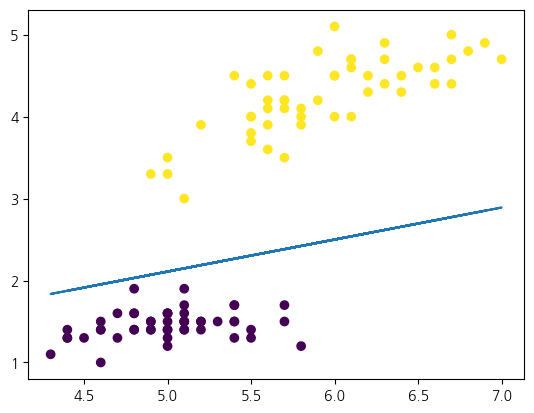
model = Perceptron()
훈련결과 = 모델평가(model, X1[:, [0, 2]], y1)
print('train={train:.2%}, test={test:.2%}'.format(**훈련결과))
w = model.coef_
b = model.intercept_
print(f'w={w}, b={b}')
f = lambda x, w, b: (w[0]/-w[1]) * x + (b/-w[1])
plt.scatter(X1[:, 0], X1[:, 2], c=y1)
plt.plot(X1[:, 0], f(X1[:, 0], w[0], b))train=100.00%, test=100.00%
w=[[-2.5 6.4]], b=[-1.]
y2 = iris.target[50:]
X2 = iris.data[50:]
np.unique(y2)array([1, 2])model = Perceptron()
훈련결과 = 모델평가(model, X2[:, [0, 2]], y2)
print('train={train:.2%}, test={test:.2%}'.format(**훈련결과))
w = model.coef_
b = model.intercept_
print(f'w={w}, b={b}')
f = lambda x, w, b: (w[0]/-w[1]) * x + (b/-w[1])
plt.scatter(X2[:, 0], X2[:, 2], c=y2)
plt.plot(X2[:, 0], f(X2[:, 0], w[0], b))train=89.33%, test=96.00%
w=[[-33.6 47. ]], b=[-19.]
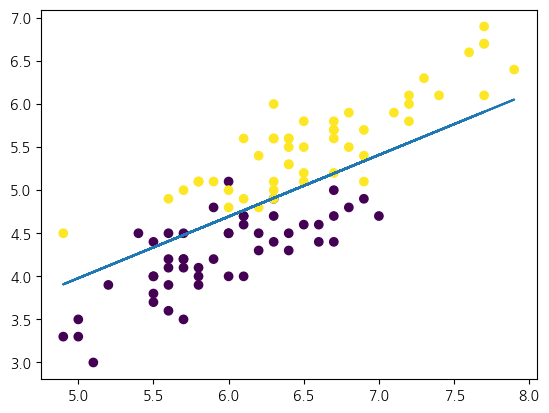
2.1이진 분류 데이터¶
로지스틱 회귀는 분류를 수행하는 선형 모델입니다. 두 범주로 나뉜 인위적 이진 분류 데이터로 살펴보겠습니다. 여러 특성으로 각 표본을 두 유형(0 또는 1) 중 하나로 분류하는 문제입니다.
from sklearn.datasets import make_classification
# 로지스틱 회귀를 살펴보기 위한 인위적 이진 분류 데이터
_X, _y = make_classification(n_samples=400, n_features=10, n_informative=6,
n_redundant=2, random_state=0)
X_분류 = pd.DataFrame(_X, columns=[f'특성{i+1}' for i in range(10)])
y_분류 = pd.Series(_y)인위적으로 생성한 데이터의 규모를 확인해 보겠습니다. 디자인 행렬 X의 형상과, X와 y의 표본 개수가 일치하는지 확인합니다.
print(X_분류.shape)
assert X_분류.shape[0] == y_분류.shape[0](400, 10)
이 데이터의 디자인 행렬은 10개의 특성으로 이루어져 있습니다. 인위적으로 만든 특성이라 각각의 구체적인 의미는 없지만, 두 유형을 구분하는 데 필요한 정보가 담겨 있습니다.
X_분류[:3]목표값은 두 유형 0과 1로 구분되며, 두 유형이 비슷한 개수로 구성됩니다.
y_분류.value_counts()1 201
0 199
Name: count, dtype: int64특성이 많을수록 탐색적 데이터 분석에서 통계적인 분포를 확인할 때 시각적인 표현이 더욱 중요해집니다. 상자 그림으로 살펴보겠습니다.
X_분류.plot(kind='box', figsize=(15, 5), rot=45)<Axes: >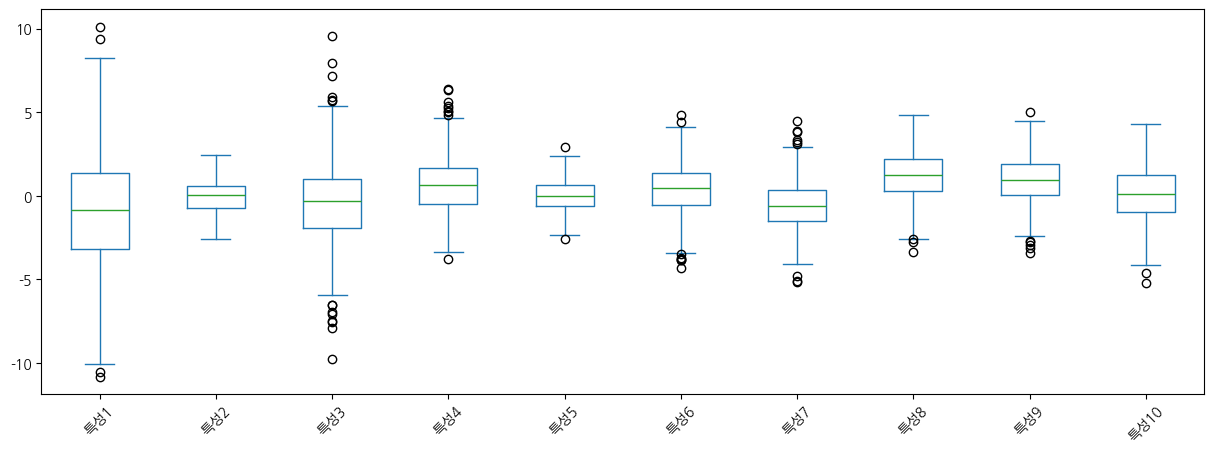
상자 그림에서 제대로 표시가 되지 않는 것 같습니다. 그 이유를 살펴보기 위해 열별 최대최소값을 확인해 보겠습니다.
확인해 보니, 각 열들의 단위가 아주 다릅니다. 소수점 단위부터 백단위 천단위인 특성들도 있습니다. 단위가 다르면 선형 모델의 매개변수 최적화 연산에 바람직하지 않습니다.
X_minmax = X_분류.apply(['min', 'max'])
X_minmaxX_분류_scaled = (X_분류 - X_minmax.loc['min']) / (X_minmax.loc['max'] - X_minmax.loc['min'])
X_분류_scaled.apply(['min', 'max'])X_분류_scaled.plot(kind='box', figsize=(15, 10), rot=45)<Axes: >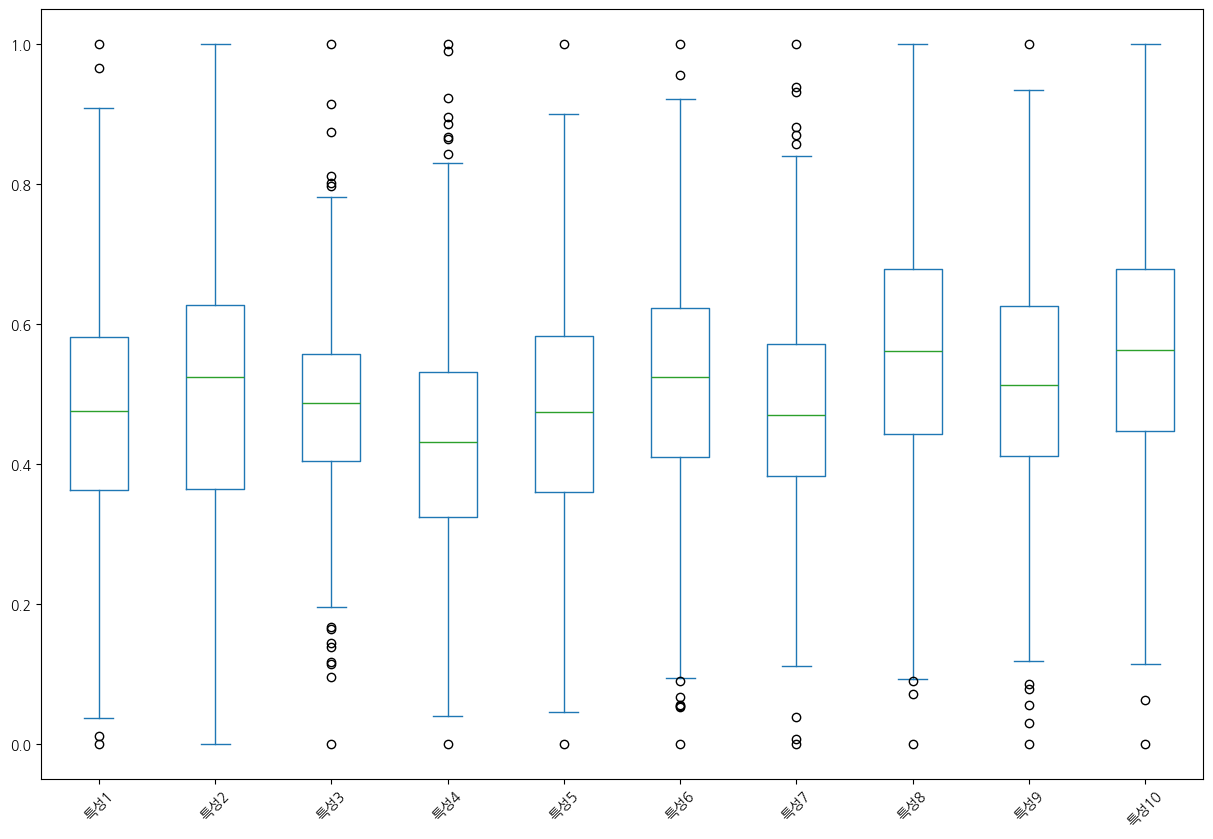
우리가 붓꽃 분류기를 높은 수준의 시험 성능을 발휘하도록 구성할 수 있었는데, 그 과정에서 우리가 붓꽃에 대해서 많이 알게 된 것은 아닙니다. 탐색적 데이터 분석을 통해서 간단한 통계적인 수치들은 살펴보았지만 그러한 과정이 붓꽃의 전문가라고 주장할 수 있는 것은 전혀 아닙니다. 그런데 이것이 우리가 바라는 점입니다. 바둑에 대해서 잘 몰라도 이세돌을 이길 수 있는 인공지능을 만드는 것과 붓꽃의 대해서 잘 몰라도 그것들의 유형을 높은 수준의 신뢰도로 분류할 수 있는 것은 기계 학습으로써 인공지능의 지향하는 것이 서로 다른 문제에도 유사하거나 동일한 알고리즘을 적용해서 문제를 해결하고자 하는 일반성임을 시사합니다.
2.21958 퍼셉트론¶
from sklearn.linear_model import Perceptron
perceptron = Perceptron()
모델평가(perceptron, X_분류, y_분류, random_state=0){'train': 0.7766666666666666, 'test': 0.79}2.3로지스틱 회귀¶
기계학습 모델의 학습과 예측은 확률적입니다. 확률적이라는 것은, 예측이 확정적인 예, 아니오가 아니라 자신감의 정도라는 것을 의미합니다. 어떤 사건이 발생하거나, 그렇지 않다고 예측을 하는 이진 분류의 경우를 가정하겠습니다. 스포츠 경기의 승패를 예측하는 것이 그러한 예시가 될 수 있습니다. 이 경우, 승산률, odd ratio는 다음과 같이 정의합니다.
이 때, 확률 p는 승리할 확률이라고 하겠습니다. 만약 승리할 확률이 0.5, 즉, 반반이라면, 승산률은 1입니다. 승리할 확률이 아예 없다면, 승산률은 0입니다. 무조건 승리한다면, 승산률은 무한대가 됩니다. 도박에서 승산률에 따라 돈을 걸었을 때, 기대되는 수익을 계산하는 방식이라고 생각할 수 있습니다. 승률이 0.5이면, 승산률이 1이고, 이러한 승산률에서 돈을 걸면, 최종적으로 자본은 베팅하기 전과 동일합니다. 즉, 본전입니다. 승률이 0일 때 승산률은 0이고, 이 때 베팅하면 자본은 0이 됩니다. 무조건 승리하는 경우, 승산률은 무한대이고, 이 때 베팅하면 자본은 무한히 증가하게 됩니다.
odd_ratio = lambda p: p / (1 - p + 1e-7)
for p in [0.0, 0.5, 1.0]:
print(f'odd ratio: {odd_ratio(p):.2f}')odd ratio: 0.00
odd ratio: 1.00
odd ratio: 10000000.00
승산률을 그래프로 표시하면 다음과 같습니다. 그런데, 승리할 확률이 0.5보다 커지는 경우, 승산률의 값이 급격하게 증가합니다. 이런 문제를 다루기 위해 로그로 값을 변환하는 방법이 종종 사용됩니다. 로그를 취하면 좀더 완만하고 일정하게 값이 변한다는 장점이 있습니다. 승산률에 로그를 취한 것은, ‘로짓(logit)’이라고 부릅니다.
p = np.arange(0.0, 1.0, 0.01)
_, subplots = plt.subplots(1, 2, figsize=(10, 4))
subplots[0].plot(p, odd_ratio(p))
subplots[1].plot(p, np.log(odd_ratio(p) + 1e-3))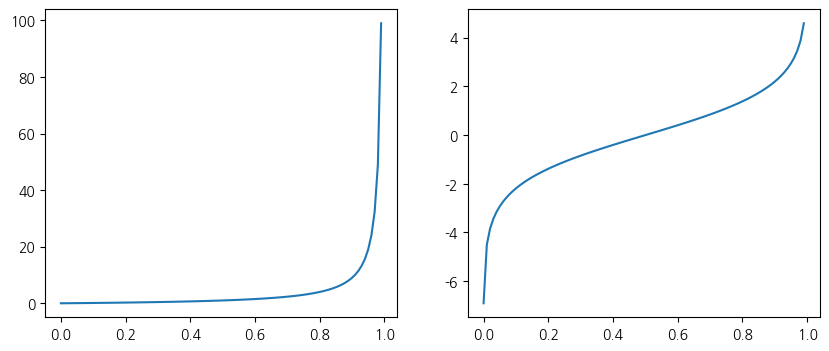
퍼셉트론에서 입력에 대해 가중치가 취합되어 발생한 값을 z라고 했을 때, 이 값은 궁극적으로는 1 또는 -1에 기여합니다. 주어진 입력 x에 대해 출력이 1일 확률을 발생하도록 구성하겠습니다. 이진 분류의 경우, 어느 한 쪽의 확률을 계산하면, 다른 쪽의 확률은 자동으로 결정되기 때문에 이렇게 할 수 있습니다.
결과적으로, 확률적 자신감으로 출력을 발생해야 한다면, z가 승산률로 해석될 수 있어야 합니다. 그렇게 해석하고자 한다면, 또한, z는 임의의 실수값이기 때문에 0 이상의 범위를 갖는 승산률 대신, 로그 승산률, 즉, 로짓이라고 해야 합니다. 로짓의 출력은 실수 전체 범위이기 때문입니다.
실제로 우리가 알고 싶은 것은, 입력 x가 주어졌을 때 출력 y가 1일 조건부 확률입니다. 그래서, 전체 공식을 p에 대해 정리합니다. 이렇게 정리하면, 퍼셉트론의 중간 출력 z가 발생했을 때, 정리된 함수로 변환하면, 주어진 입력 x에 대한 출력 y=1일 확률을 구할 수 있습니다.
이렇게 변환하는 함수를 그래프로 그리면 다음과 같은 s자 곡선이 그려집니다. 임의의 실수 범위에 대해, 값들은 0과 1 사이 확률적 자신감으로 변환합니다. 이러한 함수를 로지스틱 시그모이드 함수라고 하는데, 종종 줄여서 시그모이드 함수라고 부릅니다.
정리하자면, 퍼셉트로의 중간 출력을 시그모이드로 활성화하면, 그 값은 예측의 확률적 자신감으로 해석할 수 있습니다. 기계학습 모델은 주어진 입력에 대해 출력을 예측을 하는 확률 모델이라는 점을 적극적으로 반영하는 과정입니다.
이렇게 선형 출력 를 확률 로 정리하는 과정에서 자연스럽게 로지스틱 시그모이드 함수가 도출됩니다. 임의의 실수를 0과 1 사이의 값으로 변환하므로, 출력이 0.8이면 해당 예측을 80%의 자신감으로 했다고 해석할 수 있습니다. 선형 회귀의 출력은 임의의 실수라 그대로는 확률로 해석할 수 없지만, 시그모이드를 거치면 확률적 자신감이 됩니다.
역사적으로 로지스틱 함수는 1830년대 벨기에 수학자 베르허스트(Pierre François Verhulst)가 인구 성장 모델로 개발했고, 1950년대에 이르러 확률 예측 모형으로 여러 분야에 널리 도입되었습니다. 로지스틱 회귀는 이 시그모이드를 활성화 함수로 채택해, 퍼셉트론보다 안정적으로 학습하는 확률 모델이 되었습니다.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.linspace(-10, 10, 100)
y = sigmoid(x)
print(y.min(), '< y <', y.max())
plt.plot(x, y)4.5397868702434395e-05 < y < 0.9999546021312976
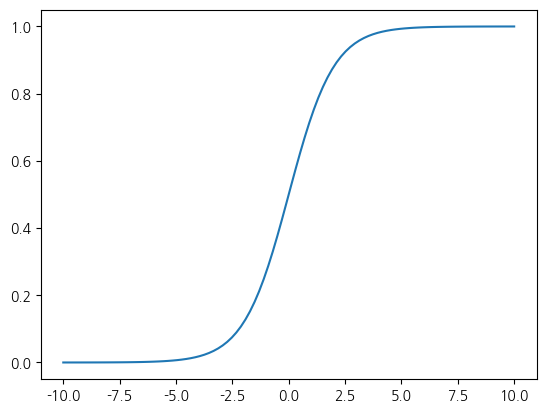
2.3.1확률 모델¶
로지스틱 회귀는 분류 출력을 확률적 자신감으로 하는 확률 모델입니다. 확률적인 모델로 만들기 위해 출력을 확률적 자신감으로 변환하는 시그모이드 함수를 활성화에 사용합니다. 항등 함수를 사용하는 경우와 대비됩니다. 로지스틱 회귀에서, "회귀"라는 용어가 사용된 이유는 선형 회귀와 방식을 대비하기 위한 것으로 보입니다. 그런데, 선형 회귀와는 달리 연속적인 확률적 자신감은 결과적으로는 퍼셉트론, 아델라인과 마찬가지로 이진 분류 출력으로 결정됩니다. 명칭과는 달리 분류만 수행할 수 있습니다.
아델라인이 퍼셉트론 학습 방식을 개선했다면, 로지스틱 회귀는 한걸음 더 나아가 퍼셉트론을 확률 모델로 간주될 수 있도록 만든 것이라고 평가할 수 있습니다.
2.3.2로그 손실과 교차 엔트로피¶
분류에서는 회귀와 손실 함수가 달라야 합니다. 출력의 확률 분포 가정이 다르기 때문입니다. 회귀는 정답과 예측의 차이인 잔차가 정규분포를 따른다고 보고 평균제곱오차를 손실로 씁니다. 그러나 분류 출력은 0과 1 사이의 확률이라, 그 차이가 정규분포를 따른다고 가정할 수 없습니다.
로지스틱 회귀는 출력이 베르누이 분포를 따른다고 보고 로그 손실(log loss) 을 사용합니다. 목표값이 1이면 예측 확률이 1에, 0이면 0에 가까워질수록 손실이 작아지도록 설계된 손실입니다.
이 로그 손실은 정보 이론에서 살펴본 교차 엔트로피와 같습니다. 교차 엔트로피는 두 확률 분포의 불일치를 재는 척도이고, 로지스틱 회귀의 학습은 모델이 출력한 확률 분포 를 정답 분포 에 최대한 가깝게 만드는 과정 — 즉 교차 엔트로피를 최소화하는 과정입니다.
from sklearn.linear_model import LogisticRegression
logit = LogisticRegression(C=1.0)
_ = 모델평가(logit, X_분류_scaled, y_분류, print_scores=True, random_state=0)훈련: 0.797, 시험: 0.790
from sklearn.linear_model import LogisticRegression
벡터크기산출 = lambda w, L=2: ((np.abs(w) ** L).sum()) ** (1 / L)
훈련결과 = {}
for C in [0.001, 0.01, 0.1, 1.0, 10., 100]:
logit = LogisticRegression(C=C, penalty='l2')
훈련결과[C] = 모델평가(logit, X_분류_scaled, y_분류, random_state=0)
훈련결과[C]['L2'] = 벡터크기산출(logit.coef_, L=2)
훈련결과[C]['활용특성수'] = (logit.coef_[0] != 0).sum()
훈련결과표 = pd.DataFrame(훈련결과).T
훈련결과표훈련결과표[['train', 'test']].plot(logx=True, style={'train': 'go--', 'test': 'ro--'})<Axes: >Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
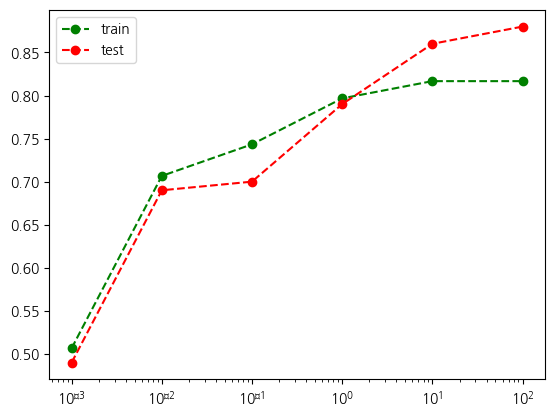
best_C =훈련결과표['test'].idxmax()
훈련결과표.loc[best_C]train 0.816667
test 0.880000
L2 14.526597
활용특성수 10.000000
Name: 100.0, dtype: float64logit = LogisticRegression(C=best_C, penalty='l2')
모델평가(logit, X_분류_scaled, y_분류, print_scores=True, random_state=0)
print(f'활용 특성수: {(logit.coef_[0] != 0).sum()}')
pd.Series(logit.coef_[0], index=X_분류.columns).sort_values(ascending=False).plot(kind='barh')훈련: 0.817, 시험: 0.880
활용 특성수: 10
<Axes: >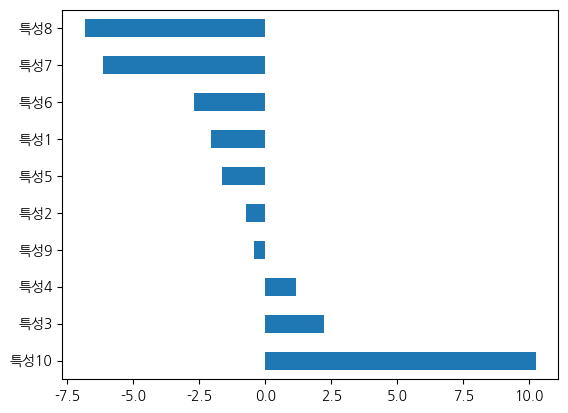
from sklearn.linear_model import LogisticRegression
훈련결과 = {}
for C in [0.001, 0.01, 0.1, 1.0, 10., 100]:
logit = LogisticRegression(C=C, penalty='l1', solver='liblinear')
훈련결과[C] = 모델평가(logit, X_분류_scaled, y_분류, random_state=0)
훈련결과[C]['L1'] = 벡터크기산출(logit.coef_, L=1)
훈련결과[C]['활용특성수'] = (logit.coef_[0] != 0).sum()
훈련결과표 = pd.DataFrame(훈련결과).T
훈련결과표/home/me/miniforge3/envs/pyml/lib/python3.10/site-packages/sklearn/svm/_base.py:1250: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
warnings.warn(
훈련결과표[['train', 'test']].plot(logx=True, style={'train': 'go--', 'test': 'ro--'})<Axes: >Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
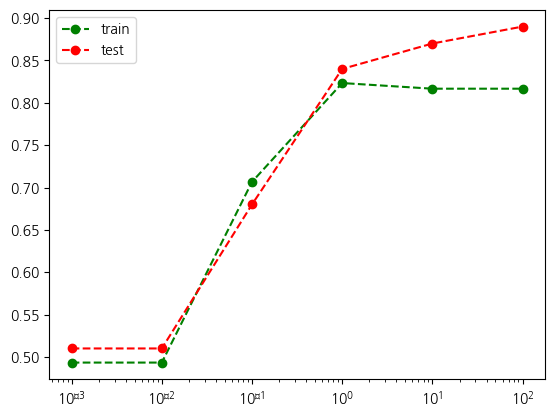
best_C =훈련결과표['test'].idxmax()
훈련결과표.loc[best_C]train 0.816667
test 0.890000
L1 33.786126
활용특성수 9.000000
Name: 100.0, dtype: float64logit = LogisticRegression(C=1.0, penalty='l1', solver='liblinear')
모델평가(logit, X_분류_scaled, y_분류, print_scores=True, random_state=0)
print(f'활용 특성수: {(logit.coef_[0] != 0).sum()}')
pd.Series(logit.coef_[0], index=X_분류.columns).sort_values(ascending=False).plot(kind='barh')훈련: 0.823, 시험: 0.840
활용 특성수: 9
<Axes: >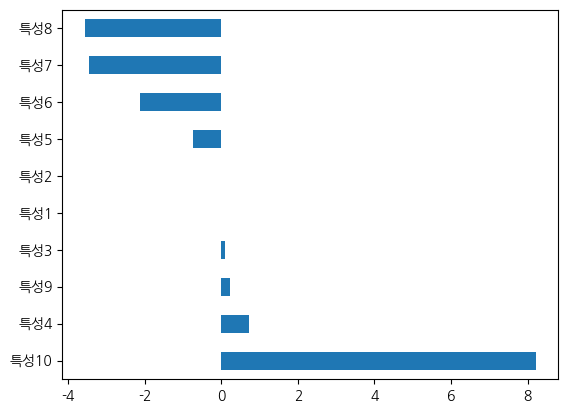
우리가 승산률에 대해 이야기를 하는 이유는, 확률 모델로써 기계학습을 논의하기 위해서입니다. 이진 분류를 수행하는 퍼셉트론의 경우에는, 1 또는 -1이라는 출력을 발생하는데, 이러한 출력은 완벽한 확정값이 아닌 확률적으로 받아들여야 합니다. 그런데, 퍼셉트론을 사용하면 예측의 최종 결과만을 보여줄 뿐, 확률적 자신감에 대해서는 알 수 없습니다. 그래서 승산률이라는 개념을 도입해, 확률적 자신감의 정도를 반영해 주고자 하였습니다.
logit = LogisticRegression(C=best_C, penalty='l2')
모델평가(logit, X_분류_scaled, y_분류, print_scores=True, random_state=0)
y_pred = logit.predict(X_분류_scaled)
예측확률 = logit.predict_proba(X_분류_scaled)
예측확률 = pd.DataFrame(예측확률, columns=['유형 0', '유형 1'], index=X_분류.index)
예측확률['예측'] = y_pred
예측확률['정답'] = y_분류
예측확률.sample(5)훈련: 0.817, 시험: 0.880
2.4다중 분류¶
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
X, y = make_blobs(random_state=42)
plt.scatter(X[:, 0], X[:, 1], c=y)
z = lambda x, w, b: (w[0]/-w[1]) * x + (b/-w[1])
linreg = LogisticRegression().fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y)
x1 = np.linspace(-15, 15)
for w, b in zip(linreg.coef_, linreg.intercept_):
plt.plot(x1, z(x1, w, b))
# plt.xticks([])
# plt.yticks([])
plt.ylim(-10, 15)
plt.xlabel('x1')
plt.ylabel('x2')
# plt.savefig('multi class.png', dpi=300)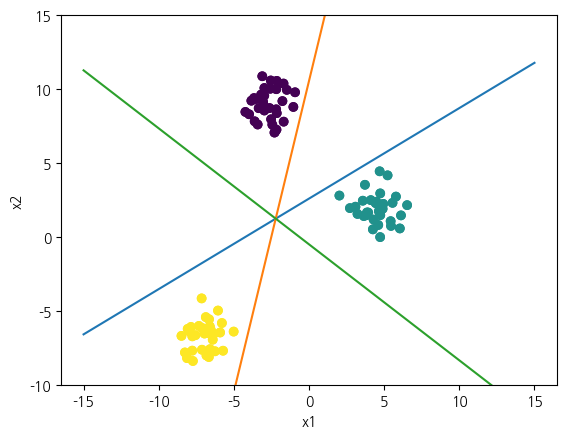
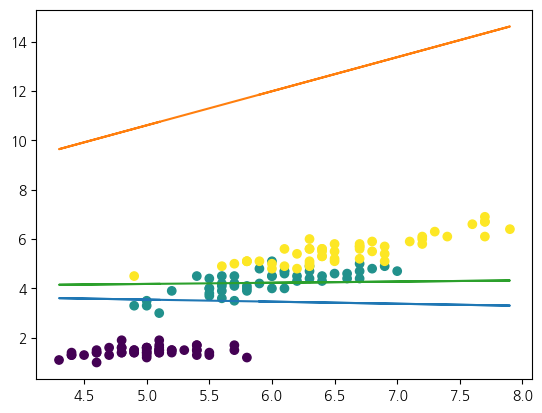
from sklearn.linear_model import LogisticRegression
X = iris.data
y = iris.target
model = LogisticRegression()
훈련결과 = 모델평가(model, X[:, [0, 2]], y)
print('train={train:.2%}, test={test:.2%}'.format(**훈련결과))
w = model.coef_
b = model.intercept_
print(f'w={w}, b={b}')
f = lambda x, w, b: (w[0]/-w[1]) * x + (b/-w[1])
plt.scatter(X[:, 0], X[:, 2], c=y)
# 유형별 결정 경계
x1 = X[:, 0]
for wi, bi in zip(w, b):
plt.plot(x1, z(x1, wi, bi))train=95.54%, test=97.37%
w=[[-0.24000636 -2.86806449]
[ 0.39098611 -0.28324413]
[-0.15097975 3.15130861]], b=[ 11.37204893 1.04917835 -12.42122729]
3표현력¶
선형 모형은 직선, 평면과 같은 초평면을 예측 모형으로 하기 때문에 저차원의 복잡한 데이터에 대해서는 최적화가 어렵습니다. 예를 들어, 다음과 같은 분포를 가정해 보겠습니다.
이전과 같은 x의 범위에 대해서, 이번에는 제곱값을 출력으로 하고 잡음을 섞었습니다. 추세선은 2차원 포물선입니다.
x = np.linspace(-5, 5, 100)
random = np.random.RandomState(1)
noise = random.normal(0, 5, len(x))
y2 = x ** 2 + noise
plt.scatter(x, y2)
plt.plot(x, y2 - noise, 'k--')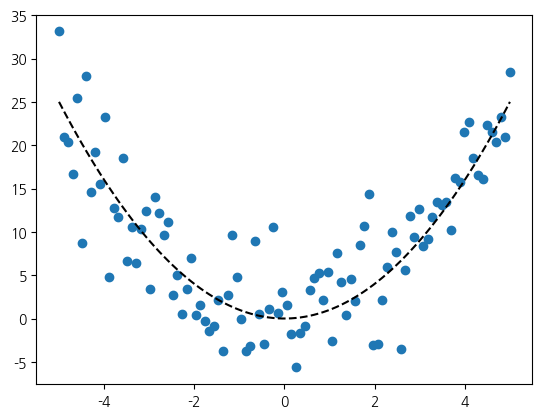
이런 분포의 데이터에 대해, 선형 회귀를 적용해 보겠습니다.
이전의 코드를 그대로 복사 붙여넣은 다음, y값만 y2로 바꾸면 됩니다. 기대한 대로, 포물선 형 분포에 대해서는 예측에 거의 완전히 실패합니다. 왜냐하면, 우리가 제시한 입력 하나에 대해 형성되는 예측 모형은 직선일 수 밖에 없기 때문입니다.
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
result, (X_train, X_test, y_train, y_test) = 모델평가(
linreg, x, y2, return_split=True, print_scores=True, random_state=0)
plt.scatter(X_train, y_train, c='green')
plt.scatter(X_test, y_test, c='red')
plt.scatter(X_train, linreg.predict(X_train), color='magenta')
plt.scatter(X_test, linreg.predict(X_test), color='cyan')
w = linreg.coef_
b = linreg.intercept_
print(f'w: {w[0]:.2f}, b: {b:.2f}')
f = lambda x: w * x + b
plt.plot(x, y2 - noise, 'k--')
plt.plot(x, f(x), color='purple', linestyle='--')
plt.xlabel('x1')
plt.ylabel('y')
plt.show()훈련: 0.013, 시험: -0.058
w: 0.35, b: 8.85
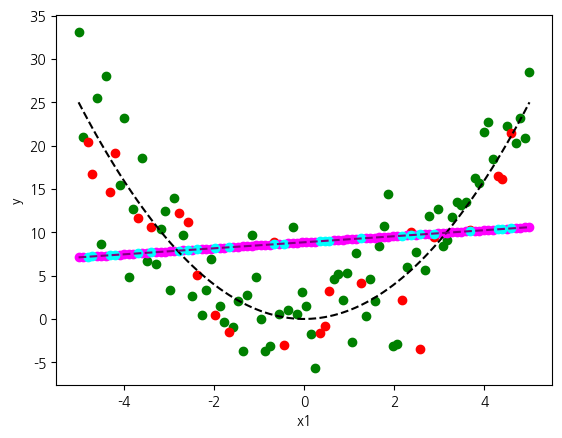
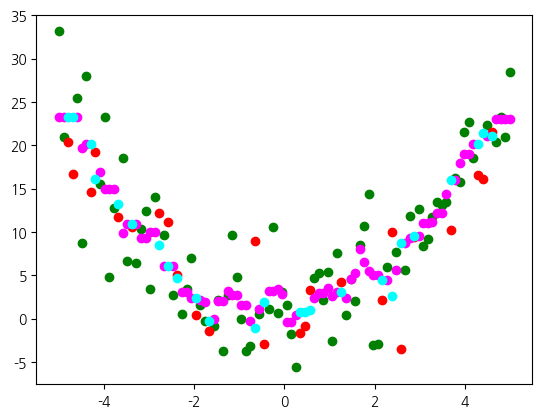
비교해서, KNN은 상대적으로 훨씬 좋은 결과를 얻었습니다. 포물선의 형태에 대략적으로 일치하는 예측을 한 것을 확인할 수 있습니다. kNN은 모형을 형성하지 않기 때문에 훈련 시점의 데이터와 유사한 분포를 갖는다면 어떤 분포든 상대할 수 있습니다. 그렇다면, 지금의 경우는 모형이 제한적인 선형 모델이 불리합니다.
from sklearn.neighbors import KNeighborsRegressor
kreg = KNeighborsRegressor(n_neighbors=5)
result, (X_train, X_test, y_train, y_test) = 모델평가(kreg, x, y2, return_split=True, print_scores=True, random_state=0)
print(result)
plt.scatter(X_train, y_train, c='green')
plt.scatter(X_test, y_test, c='red')
plt.scatter(X_train, kreg.predict(X_train), color='magenta')
plt.scatter(X_test, kreg.predict(X_test), color='cyan')훈련: 0.767, 시험: 0.604
{'train': 0.766511431245737, 'test': 0.6044227214244484}
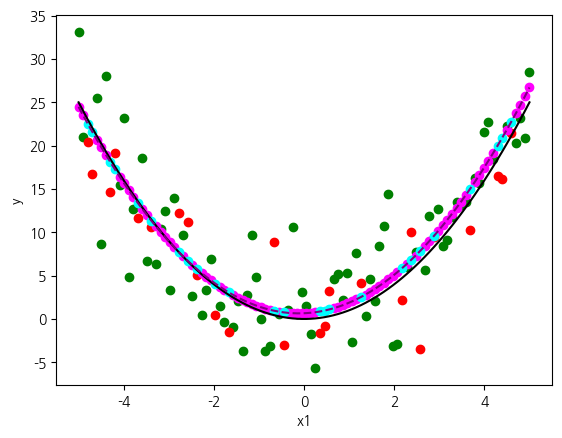
하지만 이것을 극복할 수 있는 방법이 있습니다. 예측 모형을 좀더 복잡하게 만들도록 유도하는 것입니다. 지금의 경우, 1차원 데이터를 제공했기 때문에 예측 모형은 직선만 가능합니다. 하지만, 2차원을 제공하면 보다 복잡한 모형을 형성할 수 있습니다. 지금의 경우, 원래의 특성에 대해 제곱을 한 것을 두 번째 특성으로 하여 디자인 행렬을 구성하겠습니다. 그 다음, 이러한 입력과 출력에 대해 선형 회귀를 훈련합니다.
2차원에 대해 훈련을 했기 때문에, 각 특성별 기울기, 또는 가중치가 총 2개입니다. 원래는 이러한 예측 모형은 3차원 공간의 평면으로 표현되어야 합니다. 그런데 지금의 경우, 두 번째 특성은 첫 번째 특성을 제곱하여 유도한 것입니다. 그래서 실제로는 x가 하나 밖에 없습니다. 따라서, 3차원 공간의 평면을 그리는 대신, 원래의 x1에 대해서 예측 모형을 시각화하는 것이 가능합니다. 이 때, 추세선은 추가된 특성을 반영해야 합니다.
그 결과, 선형 회귀는 포물선 형태의 예측 모형을 구성하였고, 이러한 예측 모형을 따라 예측이 수행된 것을 확인할 수 있습니다. 예측 모형이 실제 데이터에 부합하기 때문에 이전과 달리 훈련과 시험 점수가 상대적으로 훨씬 높습니다. 또한, kNN과 비교해서도 훨씬 높은 점수입니다.
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
X2 = np.vstack([x, x ** 2]).T
result, (X_train, X_test, y_train, y_test) = 모델평가(linreg, X2, y2, return_split=True, print_scores=True, random_state=0)
plt.scatter(X_train[:, 0], y_train, c='green')
plt.scatter(X_test[:, 0], y_test, c='red')
plt.scatter(X_train[:, 0], linreg.predict(X_train), color='magenta')
plt.scatter(X_test[:, 0], linreg.predict(X_test), color='cyan')
w = linreg.coef_
b = linreg.intercept_
print(f'w1: {w[0]:.2f}, w2: {w[1]:.2f} b: {b:.2f}')
f2 = lambda X: b + w[0] * X[:, 0] + w[1] * X[:, 1]
plt.plot(x, y2 - noise, 'black')
plt.plot(x, f2(X2), color='purple', linestyle='--')
plt.xlabel('x1')
plt.ylabel('y')
plt.show()훈련: 0.740, 시험: 0.699
w1: 0.22, w2: 1.00 b: 0.66
3.1선형 모델 표현력과 특징¶
선형 모델은 특징 차원에 따라 표현력이 증가합니다. 1차원 특징인 경우, 직선의 결정 경계를 생성합니다. 2차원인 경우, 원래는 평면을 그리게 되는데, 다차원을 2차원 평면에서 표현하기 위해 x2가 x1의 제곱이라고 하겠습니다. 그럼 2차 방정식으로 표현할 수 있고, 포물선이 그려집니다. 3차원인 경우에, 같은 방식으로 x2는 x1의 제곱, x3은 x1의 세제곱이라고 하면, 3차 방정식의 곡선을 그리게 됩니다. 이런 식으로 살펴보면, 선형 모델에서 특징 차원이 증가할 수록 보다 복잡한 모형 구성이 가능하다는 것을 이해할 수 있습니다.
4표현력 규제¶
4.1가중치 크기와 표현력¶
이제까지 우리는 특성의 수를 조정해서 모델의 표현력을 유도했습니다. 그런데 이런 방식은 선형 모델이 스스로 할 수 있는 일은 아니기 때문에 알고리즘의 능력은 아닙니다. 특성수와 더불어 모델의 표현력을 조절하는 또 다른 방향은 가중치 크기를 적절하게 설정하는 것입니다.
선형 모델의 표현력과 가중치의 관계를 이해하기 위해 3차 방정식을 기반으로 임의적인 데이터를 생성해 시각화해 보겠습니다.
x를 특정 범위로 생성하고, y값은 x에 대한 3차 방정식으로 합니다.
이전과 마찬가지로 난수로 잡음을 생성해 추가합니다.
산점도 그래프에서 원래의 3차 방정식을 추세선으로 그렸습니다.
x = np.linspace(-5, 5, 100)
y3 = x + x ** 2 + x ** 3
random = np.random.RandomState(1)
noise = random.normal(0, 30, len(x))
y3 += noise
plt.scatter(x, y3)
plt.plot(x, y3 - noise, 'k--')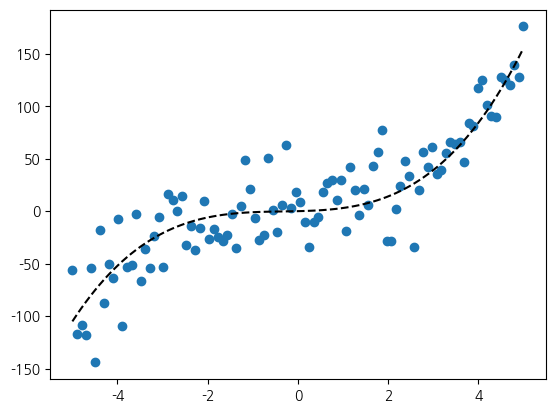
이런 데이터를 상대하기에 충분한 표현력을 가질 수 있도록 3차수까지 특성을 확장하고 선형 회귀 모델을 훈련하여 평가해 보겠습니다.
x와 x 제곱, x 세제곱을 새로운 디자인 행렬 X3으로 합니다. x를 numpy.ndarray로 생성했기 때문에 numpy에서 ndarray를 합치는 vstack API를 사용합니다. 합친 후, 행과 열을 바꾸는 전치 연산으로 디자인 행렬 형상을 적절하게 구성합니다.
지금은 표현력을 시각화하는 것이 목적이기 때문에 훈련 시험 데이터 분리 절차 없이 전체 데이터에 대해 하겠습니다.
R2 지표는 0.8로 높은 수준입니다.
가중치와 편향 값도 획득해서 출력하겠습니다.
선형 모델의 예측 모형은 특징 차원수와 관계 없이 동일한 방식으로 획득할 수 있습니다.
그 결과를 시각화하겠습니다. 원래의 그래프에 예측 모형 함수를 추가로 그립니다.
원래 추세선에 거의 일치하는 것을 확인할 수 있습니다. 그렇기 때문에 최적화 성능이 지금처럼 높은 수준임을 이해할 수 있습니다.
X3 = np.vstack([x, x ** 2, x ** 3]).T
linreg = LinearRegression().fit(X3, y3)
print(f'R2: {linreg.score(X3, y3)}')
w = linreg.coef_
b = linreg.intercept_
print(f'w: {w}, b: {b}')
f = lambda X, w, b: np.dot(X, w) + b
plt.scatter(x, y3)
plt.plot(x, y3 - noise, 'black')
plt.plot(x, f(X3, w, b), color='purple', linestyle='--')
plt.xlabel('x1')
plt.ylabel('y')
plt.show()R2: 0.8068836251301051
w: [3.5796984 0.75677472 0.89627047], b: 3.8853099431763285
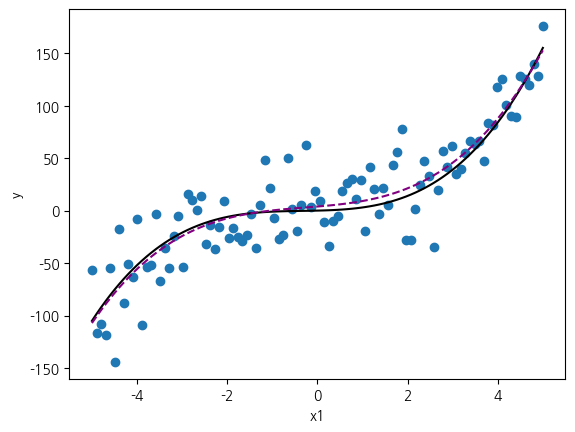
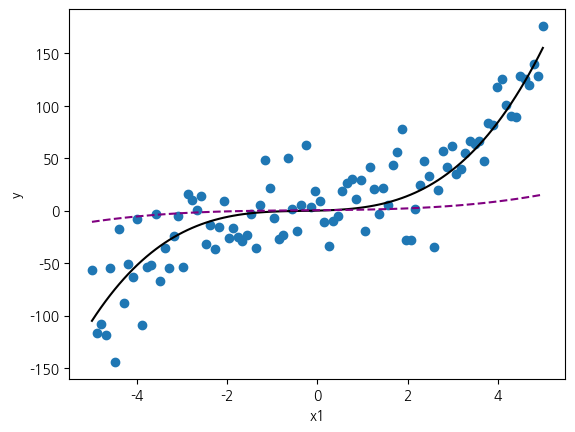
현재의 매개변수 값을 1/10 수준으로 줄였을 때 예측 모형을 관찰해 보겠습니다. 강제로 줄인 매개변수를 활용한 예측을 평가하기 위해서 R2 지표를 직접 산출합니다.
최적화 성능이 아주 안 좋은데, 예측 모형을 시각화한 결과 모형이 직선에 가까워서 너무 단순한 표현이 되었기 때문임을 이해할 수 있습니다.
현재의 실험은 매개변수의 크기를 통해서 모델의 표현력을 조절할 수 있다는 점을 살펴보는 것이 핵심입니다. 왜냐하면 특성수를 늘리는 방향만으로 표현력을 완전히 제어하는 것이 어렵기 때문입니다. 특성 차원을 늘려서 최적화 성능을 증가시킬 수 있지만, 그 과정에서 과적합이 발생할 정도로 표현력이 너무 지나칠 수 있습니다. 그래서 가중치의 크기를 조절하는 방법을 추가적으로 도입하여 적절한 수준의 표현력을 갖는 모형을 형성하는 데 도움을 받을 수 있습니다.
from sklearn.metrics import r2_score
y_pred = f(X3, w/10, b/10)
print(f'R2: {r2_score(y3, y_pred)}')
plt.scatter(x, y3)
plt.plot(x, y3 - noise, 'black')
plt.plot(x, y_pred, color='purple', linestyle='--')
plt.xlabel('x1')
plt.ylabel('y')
plt.show()R2: 0.12914228992537358
4.2Ridge¶
기계학습 알고리즘의 목표는 새로운 데이터에 대한 적응 능력 즉 일반화 입니다. 선형 모델에서 특성 차원을 조정하는 것은 모델이 스스로 할 수 없기 때문에 모델이 자체적으로 할 수 있는 일은 가중치에 크기를 적절하게 설정하는 것 뿐입니다. 그러한 점에 착안한 것이 1970년 릿지(Ridge) 회귀 모형입니다.
릿지의 규제 효과는 특성이 여럿일 때 잘 드러납니다. 규제가 의미를 갖도록, 특성이 여러 개인 인위적 회귀 데이터를 만들어 사용하겠습니다. 선형 회귀는 별다른 설정이 없지만, 릿지에는 규제 강도를 정하는 alpha 설정이 있으며 기본값은 1.0입니다. 같은 데이터에 두 모형을 적용해 가중치와 성능을 비교해 보겠습니다.
from sklearn.datasets import make_regression
# 규제(Ridge/Lasso) 효과를 살펴보기 위한 인위적 다특성 회귀 데이터
data, y = make_regression(n_samples=200, n_features=10, n_informative=5,
noise=15.0, random_state=0)
XX = pd.DataFrame(data, columns=[f'특성{i+1}' for i in range(10)])
X_scaled = (XX - XX.mean()) / XX.std()from sklearn.linear_model import Ridge
print('linreg')
linreg = LinearRegression()
_ = 모델평가(linreg, XX, y, print_scores=True, random_state=0)
print('ridge')
ridge = Ridge(alpha=1.0)
_ = 모델평가(ridge, XX, y, print_scores=True, random_state=0)linreg
훈련: 0.966, 시험: 0.955
ridge
훈련: 0.966, 시험: 0.956
같은 선형 모델에서 데이터가 동일하다면 성능 차이의 원인은 매개변수일 수 밖에 없습니다. 그래서 두 모형의 가중치를 비교해 보겠습니다.
같은 데이터로 훈련된 선형 회귀와 릿지의 가중치를 시리즈로 구성하고, 시리즈 이름을 설정합니다.
구성된 두 개의 시리즈를 pandas.concat으로 1축 방향으로 합친 다음, 결과 데이터프레임을 막대 그래프로 출력합니다. 두 모형의 매개변수가 하나의 그래프에서 표시됩니다.
그런데 매개변수가 많아지면 지금처럼 값을 출력을 하는 방식으로는 어떤 점이 차이가 나는지를 언뜻 이해하기 어렵습니다.
linreg_params = pd.Series(linreg.coef_, index=XX.columns)
linreg_params.name = 'Linear Regression'
ridge_params = pd.Series(ridge.coef_, index=XX.columns)
ridge_params.name = 'Ridge Regression'
pd.concat([linreg_params, ridge_params], axis=1).plot(kind='barh')<Axes: >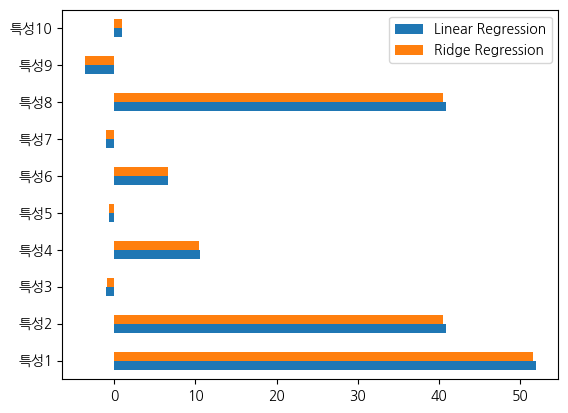
4.2.1벡터 크기¶
매개변수는 특성에 일대일로 대응되는 벡터입니다. 그래서 벡터의 크기로 비교하면 좀더 편리합니다. 벡터의 크기를 구하는 방식은 기본적으로 유클리드 거리입니다. 이런 방식을 좀더 일반적으로 표현할 수 있습니다. 이 공식에서 L값이 2인 경우, 유클리드 거리이고 이 값이 기본적으로 많이 사용됩니다. 이것을 기호로 표기하면 다음과 같습니다. 보통 유클리드 거리를 많이 사용하기 때문에 L값을 생략하여 표기하기도 합니다. 만약 L값이 다른 경우에는 명시합니다. L값이 1이면, 절대값 합계가 됩니다.
벡터 크기 공식을 간단한 함수로 구현하고, 훈련된 선형회귀와 릿지의 가중치 벡터 크기를 비교해 보겠습니다. 가중치 벡터와 L값을 함수 입력으로 하겠습니다. L의 기본값은 2로 하여 유클리드 거리를 기본으로 하겠습니다.
선형회귀와 비교해 릿지의 가중치 벡터 크기는 절반 이하입니다. 우리가 앞서 가중치에 크기를 줄일수록 표현력을 단순하게 만들 수 있다, 즉 규제할 수 있다는 점을 시각적으로 살펴봤습니다. 릿지의 경우 선형회귀 대비 절반 크기의 가중치를 사용해 좀더 단순한 모형을 만들었고, 그 결과 과적합이 약간 개선되었습니다. 그런데 이런 노력이 시험 점수까지 희생하는 것은 대체로 우리가 원하는 것이 아닙니다. 이것은 기본 설정인 alpha=1.0을 사용한 결과인데, 기본 설정이 좋다는 의미는 아닙니다. 설정할 수 있다면 현재 데이터셋에 대해서 어떠한 설정이 좋은지를 살펴보는 튜닝 과정이 필요합니다.
벡터크기산출 = lambda w, L=2: ((np.abs(w) ** L).sum()) ** (1 / L)
print(f'linreg: {벡터크기산출(linreg.coef_)}')
print(f'ridge: {벡터크기산출(ridge.coef_)}')linreg: 78.79959015988275
ridge: 78.2046620811982
4.2.2alpha 값에 따른 가중치 변화¶
릿지는 alpha 설정으로 가중치의 크기를 제어합니다. 이런 설정을 통해 모델의 표현력을 규제할 수 있습니다. 그 효과를 확인하기 위해서 알파 값에 에 대해서 튜닝하여 평가해 보겠습니다.
알파 값의 범위는 로그 스케일, 즉 10 단위로 바꿔가면서 평가했습니다. 이때 가중치 크기가 어떻게 바뀌는지를 관찰하기 위해서 가중치 벡터의 크기를 L2로 산출하고 결과에 추가했습니다.
from sklearn.linear_model import Ridge
훈련결과 = {}
for alpha in [0.001, 0.01, 0.1, 1.0, 10., 100]:
ridge = Ridge(alpha=alpha)
훈련결과[alpha] = 모델평가(ridge, XX, y, random_state=0)
훈련결과[alpha]['L2'] = 벡터크기산출(ridge.coef_, L=2)
훈련결과표 = pd.DataFrame(훈련결과).T
훈련결과표.index.name = 'alpha'
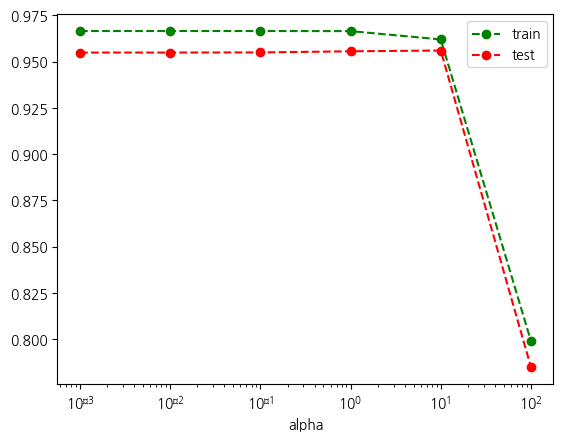
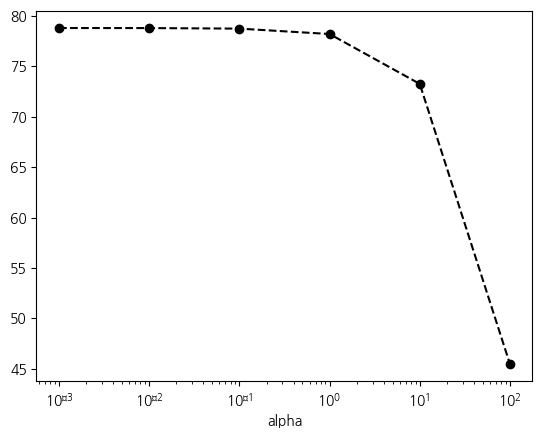
훈련결과표이 결과를 그래프로 출력하겠습니다. 그래프를 출력할 때, 알파값이 로그 스케일로 변하기 때문에 x 축을 로그 스케일로 그리는 것이 바람직합니다.
결과를 살펴보니 알파값과 성능이 반비례하는 경향을 확인할 수 있습니다. 알파값이 작을수록 성능이 높고, 알파 값이 커질수록 성능은 낮아집니다.
훈련결과표[['train', 'test']].plot(logx=True, style={'train': 'go--', 'test': 'ro--'})<Axes: xlabel='alpha'>Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
알파 값에 따른 가중치 크기도 살펴보겠습니다.
알파와 가중치 크기가 반비례하는 경향을 확인할 수 있습니다.
훈련결과표.L2.plot(logx=True, style='ko--')<Axes: xlabel='alpha'>Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
4.2.3가중치 감소¶
릿지는 선형 모델이기 때문에 선형 회귀와 예측 모형은 완벽하게 동일합니다. 다른 점은 매개변수의 크기를 조절해 표현력을 규제하는 능력입니다. 이런 방식을 가중치 감소 기법이라고 합니다. 예측 모형이 동일하지만, 손실을 측정할 때 원래의 평균 제곱 오차에 가중치 크기를 더해 그것이 일종의 벌칙처럼 동작하도록 합니다. 왜냐하면 학습은 손실을 가능한 낮추는 것인데, 손실에 무언가가 더해진다면 손실이 높아지기 때문에 그런 의미에서 벌칙입니다. 이때 가중치 크기는 L2 방식을 기본으로 하는데, 제곱근을 없애기 위해 L2에 제곱을 합니다. 그럼 제곱합이 됩니다. 평균 제곱 오차에서 제곱을 하는 것과 비슷한 이유인데, 대체로 수학적인 최적화 기법과 연관이 있습니다.
이렇게 하면 선형 회귀와 동일한 예측을 한 경우를 가정했을 때, 평균제곱오차값은 같지만 가중치 크기가 더해져서 선형회귀보다 손실이 높게 됩니다. 손실이 높은 것은 좋지 않기 때문에 이것을 낮추기 위해서 더 노력을 하게 됩니다. 그래서 같은 예측을 하더라도 가중치는 더 작은 값을 갖게 됩니다. 그래서 가중치 감소 기법이라고 부릅니다. 이러한 방식을 활용하는 이유는 우리가 앞서 살펴본 대로 가중치에 크기가 클수록 모형의 복잡해지기 때문입니다. 모형이 복잡할수록 과적합 위험이 증가합니다. 그래서 예측을 잘 하면서도 가능한 단순한 모형을 만들기 위해서 이런 기법을 활용합니다.
이러한 벌칙의 정도를 조절하기 위해서 알파 값을 가중치에 곱합니다. 알파가 1.0이면 가중치의 크기가 그대로 벌칙이 됩니다. 그래서 기본값이 1.0입니다. 알파 값을 작게 하면 가중치 크기가 커도 벌칙은 작아집니다. 극단적으로 알파 값이 영이면 벌칙이 없어지고 그럼 선형 회귀와 다를 바 없게 됩니다. 반대로 알파 값을 크게 하면 가중치 크기가 작아도 벌칙은 커집니다. 그래서 이렇게 하면 가중치 크기를 더욱 가파르게 감소시키도록 유도합니다.
실험 결과에서 확인해보면 알파 값이 작으면 가중치 크기가 크고 반대로 알파 값이 커질수록 가중치에 크기는 작아지고, 점수도 하락하는 것을 확인할 수 있습니다. 알파 값과 모델의 표현력이 반비례한다고 정리할 수 있습니다. 그런데 반비례하는 것은 생각하기 번잡합니다. 그래서 알파는 규제와 비례한다고 서술하는 것이 편리합니다. 규제가 클수록 표현력이 제한됩니다. 이런 모든 과정의 목표는 일반화 성능입니다. 즉, 높은 시험 점수입니다. 그래서 시험 점수가 가장 높은 알파 값을 찾아서 그때의 성능을 보겠습니다.
alpha=0.1에서 훈련과 시험 점수가 모두 0.87입니다. 두 점수의 간격이 거의 없으면서도 높은 수준의 성능입니다. 이 때 가중치 크기는 이전의 1.0보다는 크면서 선형회귀보다는 작습니다. alpha=1.0보다는 성능이 좋으면서, 선형회귀에 비해서는 일반화 성능이 좀더 나은 균형점이라고 평가할 수 있습니다. 그래서 현재 데이터에 대해서 좋은 표현이 결정되었다고 할 수 있습니다.
best_alpha =훈련결과표['test'].idxmax()
훈련결과표.loc[best_alpha]train 0.961957
test 0.955962
L2 73.257904
Name: 10.0, dtype: float64ridge = Ridge(alpha=best_alpha)
_ = 모델평가(ridge, XX, y, random_state=0)
pd.Series(ridge.coef_, index=XX.columns).plot(kind='barh', figsize=(10, 8))<Axes: >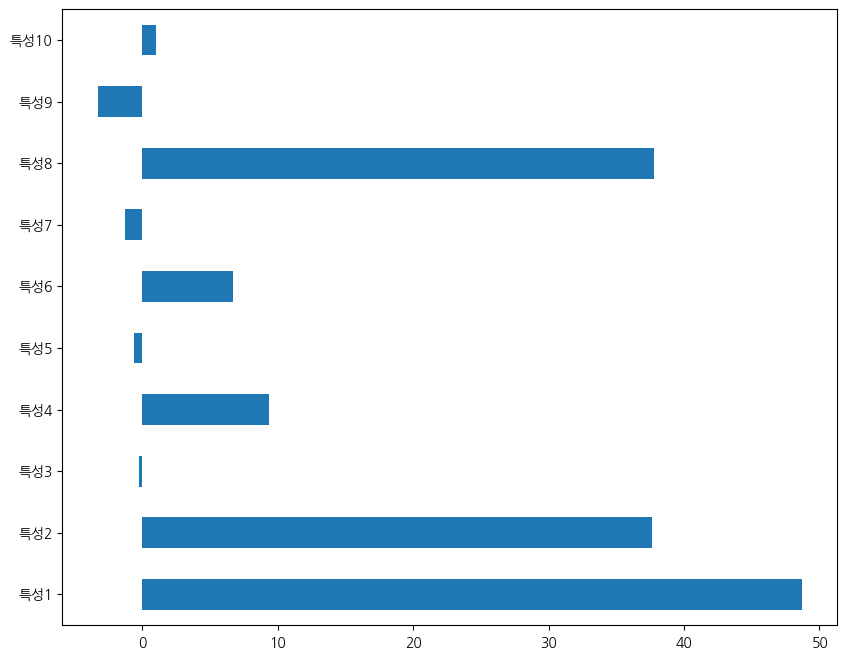
4.3Lasso¶
라쏘(Lasso)는 1980년대에서 90년대에 걸쳐서 개발된 또 다른 선형 회귀 모델입니다. 릿지와 마찬가지로 가중치 감소 기법을 사용합니다. 다른 부분은 리치와 사실상 동일합니다. 가중치에 크기를 측정하는 방식만 L2대신 L1으로 바꾼 것이 특징입니다. 릿지는 가중치 제곱합을 기준으로 하고, 라쏘는 절대값 합계를 가중치 크기로 사용합니다. 미세한 차이인데, 최적화를 하는 방식이 달라짐으로 인해서 가중치를 활용하는 것이 결과적으로 상당히 달라집니다.
라쏘의 가장 중요한 특징은 일부 가중치를 정확히 0으로 만든다는 점입니다. L1 페널티는 최적화 과정에서 불필요한 변수의 가중치를 0으로 밀어내므로, 해당 변수를 모델에서 완전히 제거하는 특성 선택(feature selection) 효과를 냅니다. 변수가 많은 데이터에서 라쏘는 모델을 단순화하고 해석을 쉽게 하며 과적합을 줄입니다.
다만 L1 페널티는 손실 함수에 미분이 불가능한 지점을 만들기 때문에, 릿지의 매끄러운 포물선형 손실에 비해 최적화가 까다롭습니다. 그래서 라쏘는 별도의 최적화 알고리즘을 필요로 합니다.
라쏘의 설정도 릿지와 같이 알파 값을 사용하고 의미는 동일합니다. 기본 설정으로 훈련하고 평가해 보겠습니다. 가중치 감소가 동작하는 것을 확인하기 위해서 가중치 평균값도 확인합니다. 가중치 감소로써 가중치 크기를 가급적 작게 만들지만 완전히 영이 되면 해당 특성이 제외됩니다. 그래서 0아닌 가중치가 몇 개나 되는지 같이 살펴보겠습니다.
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=1.0)
모델평가(lasso, XX, y, print_scores=True, random_state=0)
print(f'가중치 평균: {np.mean(lasso.coef_)}')
print(f'유효 특성수: {np.sum(lasso.coef_ != 0.0)}')훈련: 0.965, 시험: 0.958
가중치 평균: 14.324570649847356
유효 특성수: 6
훈련과 시험점수는 R2 0.5 정도로 좋지 않습니다. 같은 설정의 릿지를 훈련하여 비교하겠습니다.
훈련과 시험 점수는 alpha=1.0에서 R2 0.85로 상대적으로 훨씬 좋은 성능입니다. 그 이유로 짐작되는 것은 영이 아닌 가중치의 개수, 즉 유효 특성 수입니다. 릿지는 전체 특성을 모두 사용했습니다. 라쏘는 현재 alpha=1.0 설정에서 같은 데이터에 대해 세 개의 특성만 활용했습니다. 너무 적은 특성을 활용했기 때문에 과소 적합이 발생했습니다. 라쏘는 절대값 합을 가중치 크기로 함으로써 특성을 보다 적극적으로 선별하는 효과가 특징입니다. 이렇게 되는 이유는 최적화 그의 수학적인 기법과 연관이 있습니다. 절대값을 기준으로 하면 제곱으로 할 때와 달리 손실 최적화 시점에서 미분이 어렵습니다. 그러한 이유로 릿지의 손실 최적화와는 다른 기법들이 적용되어야 하는데, 그 과정에서 수학적인 이유로 어떤 특성에 대한 가중치는 0으로 되어 버리는 경향이 있습니다.
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0)
모델평가(ridge, XX, y, print_scores=True, random_state=0)
print(f'가중치 평균: {np.mean(ridge.coef_)}')
print(f'유효 특성수: {np.sum(ridge.coef_ != 0.0)}')훈련: 0.966, 시험: 0.956
가중치 평균: 14.458474192893444
유효 특성수: 10
같은 설정에서 라쏘가 너무 표현력이 제한되어서 릿지에 비해서 성능이 많이 안 좋습니다. 두 모델의 원리가 유사하지만 그렇다고 해서 동일한 설정이 유사한 효과를 낸다고 할 수 없습니다. 좋은 설정을 찾기 위해 역시 튜닝이 필요합니다.
튜닝을 하는 방법은 릿지와 동일합니다. 다만 벡터 크기를 산출할 때 L1을 반영합니다. 알파 값 설정에 따른 유효 특성 수도 같이 수집합니다. 알파는 규제이기 때문에 규제가 적을수록 표현력이 증가하고 표현력이 높은 모델은 더 많은 특성을 사용합니다. 그렇기 때문에 알파 값이 작을 때 활용된 특성 수도 많습니다. 알파 값이 커지면 어떤 경우에는 특성을 전혀 사용하지 않게 되는 경우가 생깁니다 특성을 전혀 사용하지 않는 것은 데이터를 아예 보지 않는 것이기 때문에 그 성능의 의미가 없습니다. 이런 시점에서는 더 이상 알파 값을 증가시키는 것이 의미가 없습니다.
from sklearn.linear_model import Lasso
훈련결과 = {}
for alpha in [0.001, 0.01, 0.1, 1.0, 10., 100]:
lasso = Lasso(alpha=alpha)
훈련결과[alpha] = 모델평가(lasso, XX, y, random_state=0)
훈련결과[alpha]['L1'] = 벡터크기산출(lasso.coef_, L=1)
훈련결과[alpha]['특성수'] = np.sum(lasso.coef_ != 0.0)
훈련결과표 = pd.DataFrame(훈련결과).T
훈련결과표.index.name = 'alpha'
훈련결과표그래프로 시각화해 보겠습니다.
알파 값에 따라서 모델 표현력의 변화를 잘 반영하는 그래프입니다.
훈련결과표[['train', 'test']].plot(logx=True, style={'train': 'go--', 'test': 'ro--'})<Axes: xlabel='alpha'>Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
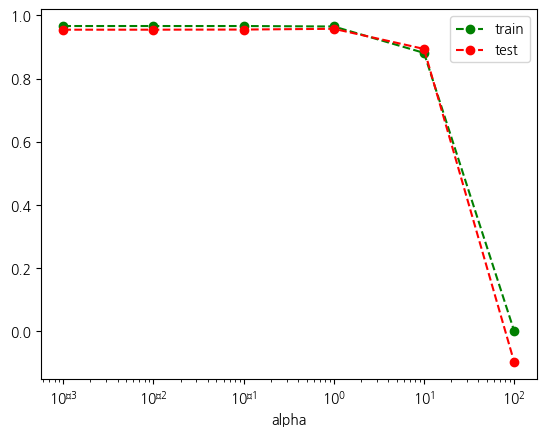
시험 점수가 가장 높은 알파 값의 경우 훈련 결과를 보겠습니다. 0.001일 때, 시험점수 R2 0.87로 릿지의 최고 점수와 동일한 수준입니다. 이때에 13개의 특성이 활용되었습니다. 여전히 전체 15 개보다는 적게 사용되었습니다.
best_alpha =훈련결과표['test'].idxmax()
훈련결과표.loc[best_alpha]train 0.964982
test 0.957692
L1 148.096592
특성수 6.000000
Name: 1.0, dtype: float64튜닝에서 가장 좋은 성능을 내는 알파 값에서 가중치 시각화도 살펴보겠습니다.
릿지와 유사한데, model year 등 몇 개의 특성에서 가중치가 완전히 영인 것을 확인할 수 있습니다.
lasso = Lasso(alpha=best_alpha)
_ = 모델평가(lasso, XX, y, random_state=0)
pd.Series(lasso.coef_, index=XX.columns).plot(kind='barh', figsize=(10, 8))<Axes: >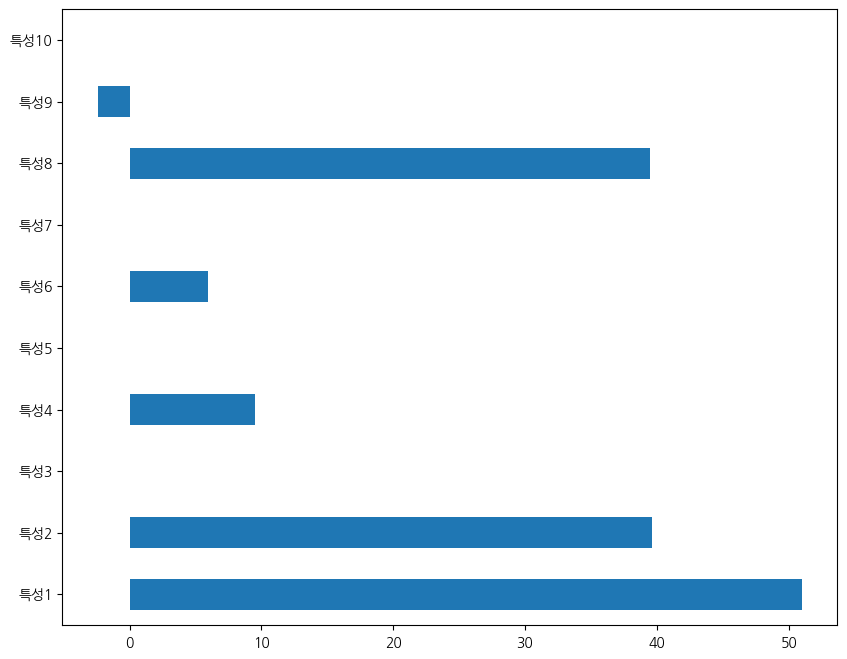
5Elastic Net¶
from sklearn.linear_model import ElasticNet
훈련결과 = {}
for alpha in [0.001, 0.01, 0.1, 1.0, 10., 100]:
for L1_ratio in np.arange(0.1, 1.0, 0.1):
elastic_net = ElasticNet(alpha=alpha, l1_ratio=L1_ratio)
훈련결과[(alpha, L1_ratio)] = 모델평가(elastic_net, XX, y, random_state=0)
훈련결과[(alpha, L1_ratio)]['특성수'] = np.sum(elastic_net.coef_ != 0.0)
훈련결과표 = pd.DataFrame(훈련결과).T
훈련결과표.index.names = ['alpha', 'L1_ratio']
훈련결과표best_alpha, best_L1_ratio = 훈련결과표['test'].idxmax()
훈련결과표.loc[(best_alpha, best_L1_ratio)]train 0.964619
test 0.957032
특성수 10.000000
Name: (0.1, 0.6), dtype: float64샘플 수에 따른 성능 변화, 학습 곡선
sample_sizes = np.round(np.arange(0.1, 1.1, 0.1) * len(y))
sample_sizes = sample_sizes.astype('int')
sample_sizesarray([ 20, 40, 60, 80, 100, 120, 140, 160, 180, 200])scores = {'linreg': {}, 'ridge': {}}
for n in sample_sizes:
X_batch = X_scaled[:n]
y_batch = y[:n]
scores['linreg'][n] = 모델평가(LinearRegression(), X_batch, y_batch, random_state=1)
scores['ridge'][n] = 모델평가(Ridge(), X_batch, y_batch, random_state=1)선형회귀_결과표 = pd.DataFrame(scores['linreg']).T
릿지_결과표 = pd.DataFrame(scores['ridge']).Tfig, subplots = plt.subplots(1, 2, figsize=(10, 5))
선형회귀_결과표.plot(ax=subplots[0], title='linreg', ylim=(0.7, 1.01))
릿지_결과표.plot(ax=subplots[1], title='ridge', ylim=(0.7, 1.01))
plt.show()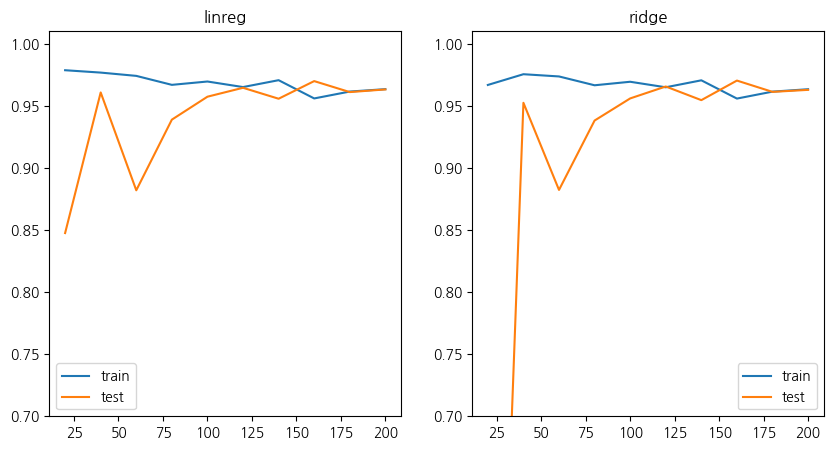
6가설 공간¶
모델이 표현할 수 있는 가능성의 영역을 가설 공간(hypothesis space) 이라 합니다. 선형 모델의 가설 공간은 직선·평면·초평면과 같은 선형적 표현으로 이루어집니다. 기계학습 모델을 고른다는 것은 결국 가설 공간을 고르는 일이고, 그 안에서 데이터에 맞는 특정한 설정(매개변수)을 찾는 것이 학습입니다.
만약 대상 데이터가 선택한 가설 공간 안에서 표현되기 어렵다면 최적화는 실패합니다. 그런 경우에는 더 넓거나 다른 형태의 가설 공간을 갖는 모델을 적용해 평가해야 합니다. 대부분의 데이터는 시각화가 어려워 어떤 모델이 적절한지 미리 알 수 없으므로, 여러 모델을 적용해 보며 찾는 수밖에 없습니다.
한편 기계학습이 데이터에 맞춰 가설 공간 자체를 무한히 넓히는 것은 불가능합니다. 입력과 출력을 잇는 적절한 함수는 무한한 가능성의 공간 어딘가에 있지만, 그 공간을 임의로 탐색할 방법이 없고 있더라도 무한한 시간이 듭니다. 그래서 어떤 데이터든 알아서 학습하는 만능의 단일 모델은 없습니다.
7선형 모델의 한계¶
선형 모델의 근본적인 한계는 비선형 데이터를 다루지 못한다는 것입니다. OR과 XOR 논리회로로 살펴보겠습니다. 입력이 두 개라 2차원 평면에서 표현되고, 출력이 0 또는 1이라 분류 문제입니다.
OR은 직선 하나로 0과 1을 나눌 수 있습니다. 그러나 XOR은 단일 선형 결정 경계로는 나눌 수 없습니다. 즉, 퍼셉트론과 같은 선형 모델은 모든 논리회로를 구현하지 못합니다. 선형 결정 경계만 표현할 수 있기 때문입니다.
우리가 관심을 두는 데이터는 OR처럼 선형적이기보다 대체로 비선형일 가능성이 훨씬 높습니다. 특성을 더 모으거나 다항식 차원 확장 같은 특성 공학으로 한계를 어느 정도 넘을 수 있지만, 그것은 선형 모델 자체의 능력은 아닙니다. 회귀에서도 사정은 같습니다. 데이터의 비선형성이 강하다면, 선형 모델의 가설 공간을 벗어날 수 있는 다른 형태의 알고리즘이 필요합니다.
import numpy as np
import matplotlib.pyplot as plt
# 논리회로의 입력(2차원)과 출력(0/1)
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y_or = np.array([0, 1, 1, 1])
y_xor = np.array([0, 1, 1, 0])
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
for ax, y, name in [(axes[0], y_or, 'OR'), (axes[1], y_xor, 'XOR')]:
for cls, marker, color in [(0, 'o', 'tab:blue'), (1, 's', 'tab:red')]:
pts = X[y == cls]
ax.scatter(pts[:, 0], pts[:, 1], c=color, marker=marker, s=200,
edgecolors='k', label=f'출력 {cls}', zorder=3)
ax.set(title=name, xlabel='$x_1$', ylabel='$x_2$',
xlim=(-0.4, 1.4), ylim=(-0.4, 1.4), xticks=[0, 1], yticks=[0, 1])
ax.legend(loc='upper left', fontsize=8)
# OR은 직선 하나로 분리 가능
xs = np.linspace(-0.4, 1.4, 10)
axes[0].plot(xs, 0.5 - xs, 'g--')
# XOR은 단일 직선으로 분리 불가
axes[1].text(0.5, -0.3, '단일 직선으로 분리 불가', ha='center', color='tab:red')
fig.suptitle('선형 분리: OR 가능, XOR 불가능')
plt.tight_layout()
plt.show()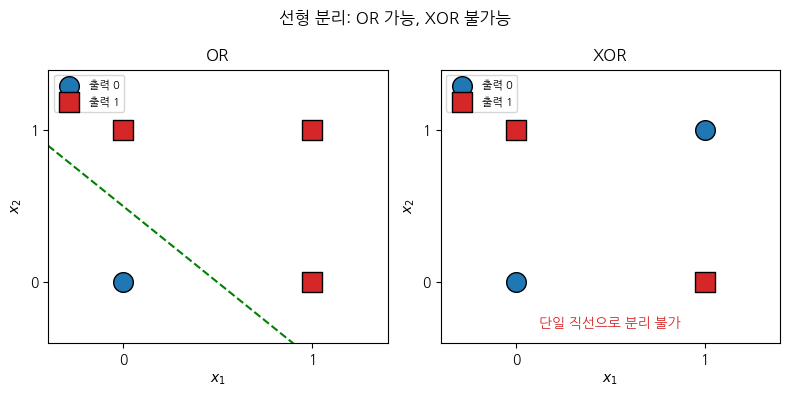
8선형 모델 정리¶
선형 모델은 회귀와 분류 문제의 기본 도구입니다.
회귀: 선형 회귀를 기본 틀로 하고, 표현력 규제를 위해 가중치 감소 기법인 릿지(L2)와 라쏘(L1)를 사용합니다. 오늘날 순수 선형 회귀보다 릿지·라쏘가 거의 언제나 낫고, 둘 중 고민이라면 L2와 L1을 함께 쓰는 Elastic Net을 고려할 수 있습니다.
분류: 퍼셉트론보다 로지스틱 회귀를 사용합니다. 로지스틱 회귀는 확률적 자신감을 바탕으로 분류하며, 여기에도 L1·L2 가중치 감소를 표현력 규제로 적용합니다.
한편 퍼셉트론의 궁극적 목표는 단일 선형 분류기가 아니라 전자 두뇌였습니다. 단일 뉴런으로 두뇌가 이루어지지 않듯, 단일 퍼셉트론은 그 기본 단위일 뿐입니다. 여러 퍼셉트론을 쌓아 비선형 문제를 넘어서려는 시도가 다층 퍼셉트론, 곧 신경망이며, 이는 선형 모델의 가설 공간을 넘어 임의의 비선형 문제를 다룹니다. 신경망과 딥러닝은 별도로 다룹니다.