정보 이론은 20세기 초 전신과 전화의 발명 시점에서 정보 통신을 위해 개발된 이론입니다.
전신이 처음 발명되었을 때, 최초의 유용한 사례에 대한 일화는 1800년대 영국에서 발생했습니다. 당시 지역간 통신을 위해 글자당 하나의 전선을 할당해 연결했다고 합니다. 예를 들어, 영어 알파벳 A-Z와 숫자 0-9를 가정하면 알파벳 26자와 십진법 숫자 10개를 합쳐 지역간 통신에 36개의 전선을 활용하는 방식입니다.
이러한 통신으로 어떤 지역에서 도망친 살인자가 통신이 연결된 지역에 기차로 도착한다는 전신이 보내졌고, 그래서 살인자가 해당 지역의 기차역에 도착했을 때 전신으로 소식을 받은 경찰들이 미리 기다려 체포할 수 있었다고 합니다.
그런데 각 글자에 하나씩 전선을 연결하는 것은 금방 문제가 있다는 사실을 알 수 있고, 실제로 그런 문제들이 발생했습니다. 첫 번째 문제는, 비용입니다. 글자당 전선을 할당하기 때문에 알파벳과 숫자를 전송하기 위해서는 36가닥의 전선이 어느 두 지역 간 연결을 위해 필요합니다. 거리가 멀수록 비용이 곱하기로 증가합니다. 두 번째 문제는 전선이 어느 하나라도 문제가 생기면 지속적으로 해당 글자를 받을 수가 없게 됩니다. 세 번째 문제는, 많이 사용되는 글자와 그렇지 않은 글자가 있다는 것입니다. 예를 들어, 영문자 e 는 영어에서 가장 빈번하게 사용되는데 z는 가장 덜 사용됩니다. 그렇다면 각 글자에 전선을 하나씩 할당하면 빈도가 높은 글자의 전선은 많이 활용되는 반면 나머지 글자들을 덜 사용됩니다.
마지막으로, 글자 순서의 문제입니다. 전신을 보낼 때 마음이 바빠서 글자들을 빠르게 전송하고 싶다고 하겠습니다. 그래서 각 글자들을 보내는 시간 간격을 가능한 짧해서 시간을 줄이고자 할 것입니다. 그런데 받는 쪽에서 이것을 받았을 때 충분한 시간 간격이 없으면 한번에 여러 글자의 신호가 동시에 받아진 것처럼 느낄 것입니다. 글자는 순서가 중요한데, 이렇게 되면 글자집합을 받았지만 어떤 순서인지를 알기 어렵게 됩니다. 이 문제는 같은 글자가 연속되는 경우
이러한 문제들은 결국 하나의 질문으로 모입니다. 정보를 어떻게 측정할 것인가? 정보의 크기를 수치로 정의할 수 있다면, 통신 비용을 따지고 부호를 효율적으로 설계하며, 나아가 기계학습 모델의 예측 품질까지 같은 잣대로 평가할 수 있습니다.
1정보의 측정¶
정보 이론에서 정보의 크기는 어떤 값을 알아내기 위해 필요한 최소한의 예/아니오 질문 횟수로 정의합니다. 예/아니오 답은 0과 1로 표현할 수 있으므로, 질문 한 번에 해당하는 정보를 1 비트(bit) 라고 부릅니다.
동전 던지기의 결과(앞/뒤)는 한 번의 질문으로 결정되므로 1비트입니다. 가능한 결과가 개이고 모두 같은 확률이라면, 필요한 질문 횟수는
입니다. 예를 들어 네 가지 결과는 비트, 영문 알파벳 26자는 비트로 표현됩니다. 전체 정보량은 문자당 비트 수에 문자 개수를 곱해 얻습니다.
import numpy as np
def bits(n_outcomes):
"동일 확률 가정에서 결과 하나를 표현하는 비트 수"
return np.log2(n_outcomes)
print(f"동전(2가지): {bits(2):.0f} 비트")
print(f"ABCD(4가지): {bits(4):.0f} 비트")
print(f"알파벳(26자): {bits(26):.2f} 비트")
print(f"알파벳 10글자 전송: {10 * bits(26):.1f} 비트")동전(2가지): 1 비트
ABCD(4가지): 2 비트
알파벳(26자): 4.70 비트
알파벳 10글자 전송: 47.0 비트
여기에는 한 가지 중요한 가정이 숨어 있습니다. 가능한 선택이 모두 같은 확률이라는 것입니다. 동전은 앞뒤가 반반이라 문제가 없지만, 현실의 많은 경우는 그렇지 않습니다. 서로 다른 확률을 갖는 경우에도 정보의 크기를 일반적으로 측정하는 방법이 정보 엔트로피입니다.
2정보 엔트로피¶
선택마다 확률이 다르면, 결과마다 필요한 질문 횟수도 달라집니다. 가 각각 의 확률을 갖는다고 하겠습니다.
는 확률 50%이므로 한 번의 질문(“A인가?”)으로 결정됩니다 → 1비트
는 25%이므로 두 번 → 2비트
는 각각 1/8이므로 세 번 → 3비트
각 결과의 정보량 에 그 확률을 곱해 모두 더하면, 결과 하나당 정보량의 평균이 됩니다. 이 평균값이 정보 엔트로피입니다.
def entropy(p):
"정보 엔트로피 (bit). p는 확률 분포"
p = np.asarray(p, dtype=float)
p = p[p > 0] # 0 log 0 = 0 으로 처리
return -np.sum(p * np.log2(p))
abcd = [1/2, 1/4, 1/8, 1/8]
print(f"A,B,C,D 분포의 엔트로피: {entropy(abcd):.2f} 비트")
print(f"네 가지가 모두 동일 확률: {entropy([1/4]*4):.2f} 비트")A,B,C,D 분포의 엔트로피: 1.75 비트
네 가지가 모두 동일 확률: 2.00 비트
계산하면 위 분포의 엔트로피는 1.75비트입니다. 같은 네 가지 결과라도 모두 동일한 확률이면 엔트로피는 2비트로 더 큽니다. 즉, 확률이 한쪽으로 치우칠수록 엔트로피는 작아집니다. 1.75비트는 "이런 분포를 따르는 글자 100개를 알아맞히려면 평균 175번의 예/아니오 질문이 필요하다"는 뜻으로 읽을 수 있습니다.
3엔트로피와 불확실성¶
정보 엔트로피라는 이름은 열역학에서 빌려왔습니다. 열역학의 엔트로피가 무질서도, 즉 예측 불가능성의 정도이듯, 정보 엔트로피도 다음에 무엇이 올지 예측하기 어려운 정도 — 불확실성을 나타냅니다.
극단적인 두 경우를 생각하면 분명해집니다.
문서가
AAAA…한 글자로만 채워져 있으면, 다음 글자는 자명하게A입니다. 불확실성이 없고, 엔트로피는 0입니다.글자가 완전히 무작위로 선택되면, 다음 글자는 무엇이든 될 수 있습니다. 불확실성이 최대이고, 엔트로피도 최대입니다.
실제 언어는 이 둘 사이에 있습니다. 영어에서 e는 가장 흔하고 z는 드뭅니다. 그래서 모스 부호는 자주 쓰는 e를 짧은 신호(1비트)로, 드문 JQXZ를 긴 신호(4비트)로 표현합니다. 확률이 높은 글자에 짧은 부호를 주면 전체 전송이 더 효율적입니다. 이렇게 확률 구조가 있는 언어는 모든 글자가 동일 확률인 경우보다 엔트로피가 낮습니다.
이항(두 가지 결과) 분포에서 한쪽 확률 를 바꿔가며 엔트로피를 그리면, 불확실성이 어떻게 변하는지 한눈에 보입니다.
import matplotlib.pyplot as plt
p = np.linspace(1e-6, 1 - 1e-6, 500)
H = -(p * np.log2(p) + (1 - p) * np.log2(1 - p))
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(p, H)
ax.axvline(0.5, color='gray', ls='--', lw=1)
ax.set_xlabel('한쪽 결과의 확률 $p$')
ax.set_ylabel('엔트로피 $H$ (비트)')
ax.set_title('이항 분포의 정보 엔트로피')
ax.annotate('최대 1비트 (p=0.5)', xy=(0.5, 1.0), xytext=(0.55, 0.7),
arrowprops=dict(arrowstyle='->'))
plt.show()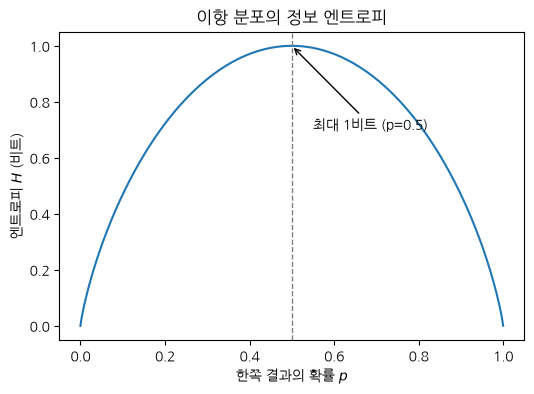
곡선은 , 즉 두 결과가 동일 확률일 때 최대(1비트)이고, 한쪽으로 치우칠수록 0에 가까워집니다. 불확실성이 클수록 정보 엔트로피가 큽니다.
4정보량과 가치¶
정보의 크기는 "네트워크로 이 정보를 전달하려면 얼마나 많은 노력이 필요한가"에서 출발했습니다. 그래서 무작위에 가까운 문서일수록 전송해야 할 정보가 많고, 엔트로피가 큽니다.
일기예보로 바꿔 생각해 보겠습니다. 어떤 지역은 맑음과 눈비가 반반입니다. 예보가 둘 중 하나를 알려주면 불확실성이 절반으로 줄고, 이때 예보의 정보량은 1비트입니다. 다른 지역은 4일에 하루만 눈비가 온다(25%). 두 지역 중 예보가 더 가치 있는 쪽은 50:50인 지역입니다 — 그곳 사람들은 외출 전 반드시 예보를 확인할 것입니다. 사막처럼 늘 맑은 곳이라면 엔트로피는 0에 가깝고, "오늘도 맑음"이라는 예보는 전달하는 정보가 거의 없습니다.
다만 정보량과 유용함은 다른 개념입니다. 일기예보는 공교롭게도 둘이 비례하지만(불확실성에 대한 정보가 곧 유용하므로), 무작위 문서처럼 엔트로피가 높다고 해서 늘 유용한 것은 아니다.
5최대 정보량¶
이제 맑음·흐림·눈·비 네 가지를 예보한다고 하겠습니다. 네 상태가 모두 25%로 동일하면 엔트로피는 2비트로, 두 가지만 예보할 때(1비트)의 정확히 두 배입니다.
엔트로피는 모든 결과가 동일 확률일 때 최대가 됩니다. 확률이 치우치면 그만큼 작아집니다. 예컨대 맑음 70%, 흐림 20%, 눈·비 각각 5%라면 엔트로피는 약 1.2비트에 그칩니다. 네 상태를 표현하려고 2비트(숫자 두 개)를 쓰지만 실제로 전달되는 정보는 1.2비트뿐이어서, 나머지는 낭비되는 셈입니다.
uniform4 = [1/4, 1/4, 1/4, 1/4]
skewed4 = [0.70, 0.20, 0.05, 0.05]
print(f"동일 확률 4가지: {entropy(uniform4):.2f} 비트 (최대)")
print(f"치우친 분포 : {entropy(skewed4):.2f} 비트")동일 확률 4가지: 2.00 비트 (최대)
치우친 분포 : 1.26 비트
6교차 엔트로피¶
엔트로피를 계산하려면 각 결과의 진짜 확률을 알아야 합니다. 그런데 일기예보나 주가처럼 진짜 확률을 알 수 없는 문제가 대부분입니다(동전은 예외적으로 50%가 확실합니다). 진짜 분포를 알 수 없으니, 우리는 분포를 예측할 수밖에 없습니다.
진짜 분포를 , 예측한 분포를 라 하겠습니다. 의 정보량을 를 기준으로 측정한 것이 교차 엔트로피입니다.
예측 가 진짜 와 정확히 일치하면 교차 엔트로피는 엔트로피와 같고, 가 에서 멀어질수록 교차 엔트로피는 엔트로피보다 커집니다. 그 차이를 상대 엔트로피 또는 쿨백-라이블러 발산(KL Divergence) 이라 하며,
의 관계가 성립합니다. 맑음·눈비의 진짜 확률이 7:3인데 예측을 5:5로 했을 때를 계산해 보겠습니다.
def cross_entropy(p, q):
p = np.asarray(p, float); q = np.asarray(q, float)
return -np.sum(p * np.log2(q))
p_true = [0.7, 0.3]
q_pred = [0.5, 0.5]
H_p = entropy(p_true)
H_pq = cross_entropy(p_true, q_pred)
print(f"엔트로피 H(p) : {H_p:.3f} 비트")
print(f"교차 엔트로피 H(p,q): {H_pq:.3f} 비트")
print(f"KL 발산 (차이) : {H_pq - H_p:.3f} 비트")엔트로피 H(p) : 0.881 비트
교차 엔트로피 H(p,q): 1.000 비트
KL 발산 (차이) : 0.119 비트
교차 엔트로피는 항상 엔트로피보다 크거나 같고, 예측이 진짜 분포에 가까울수록 작아집니다. 바로 이 성질 때문에 교차 엔트로피는 분류 모델의 손실 함수로 쓰입니다.
기계학습 분류 모델은 입력에 대해 각 범주의 확률, 즉 예측 분포 를 출력합니다. 지도학습에서는 정답이 주어지므로 진짜 분포 를 알 수 있습니다(정답 범주는 1, 나머지는 0인 분포). 모델의 예측 가 정답 에서 얼마나 떨어졌는지를 교차 엔트로피로 재고, 이 값을 줄이는 방향으로 모델을 학습시킵니다. 분류 문제의 손실로 교차 엔트로피를 쓰는 이유가 여기에 있습니다.