컴퓨터 프로그래밍은 논리의 세계라, 각 단위는 완벽하고 확정적입니다. 숫자 1은 1에 가까운 값이 아니라 논리적으로 완전한 1입니다. 그런데 이런 확정적인 부품으로 만든 기계학습 모델은 확률적입니다. 부품 하나하나는 확정적이지만, 그 조합이 만드는 결과는 확률적인 값이라는 점이 뜻밖일 수 있습니다.
그 이유는 기계학습이 다루는 현실의 문제가 불확실하기 때문입니다. 그래서 기계학습을 구성하고 그 결과를 해석하는 수학적 틀로 확률 이론을 사용합니다.
1불확실성의 출처¶
불확실성은 크게 세 가지 이유로 생깁니다.
대상 자체가 불확정적인 경우. 진정으로 무작위로 섞인 카드덱에서 뽑는 카드처럼, 결과를 원리적으로 예측할 수 없는 경우입니다.
불완전한 관찰. 시스템 자체는 확정적이어도, 우리가 가진 정보가 부족하면 결과는 불확실합니다. 닫힌 문 뒤의 상품 위치는 정해져 있지만, 고르는 사람에게는 불확실한 것과 같습니다.
불완전한 모델. 모델이 현실을 완벽하게 담지 못하면, 그 간극이 불확실성으로 나타납니다.
2도수 확률과 베이즈 확률¶
확률은 원래 사건의 빈도를 분석하기 위해 개발되었습니다. 주사위의 한 면이 나올 확률이 라는 것은, 던지기를 무한히 반복하면 그 면이 나오는 비율이 에 수렴한다는 뜻입니다. 이를 도수 확률이라 합니다.
그러나 반복할 수 없는 사건도 있습니다. 의사가 "감기일 확률이 60%"라고 할 때, 환자가 무한히 진료받는다는 뜻이 아니라 여러 증상을 고려한 자신감의 정도를 말합니다. 이런 확률은 베이즈 확률(조건부 확률)입니다. 기계학습에서는 이 두 종류의 확률을 같은 공식으로 다룹니다.
도수 확률이 반복으로 수렴하는 모습을 동전 던지기로 확인해 보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
난수 = np.random.RandomState(0)
던지기 = 난수.randint(0, 2, size=2000) # 0=뒷면, 1=앞면
누적비율 = np.cumsum(던지기) / np.arange(1, len(던지기) + 1)
plt.plot(누적비율)
plt.axhline(0.5, color='gray', linestyle='--')
plt.xlabel('던진 횟수'); plt.ylabel('앞면 비율')
plt.title('도수 확률: 반복할수록 0.5로 수렴')
plt.show()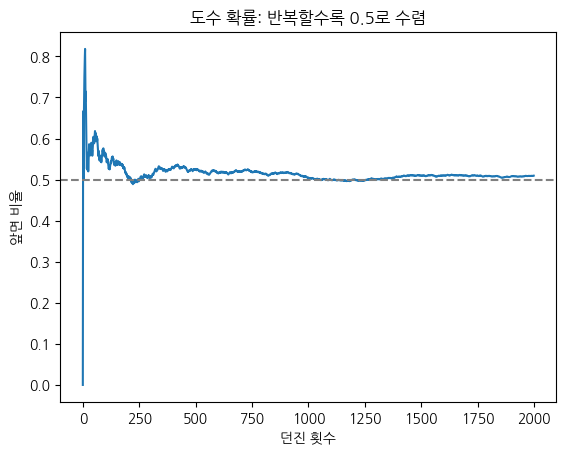
던진 횟수가 늘수록 앞면의 비율이 0.5로 수렴합니다. 이것이 도수 확률의 의미입니다.
3독립 동일 분포 가정 (I.I.D.)¶
기계학습 모델의 성능은 독립 동일 분포(Independent and Identically Distributed, I.I.D.) 가정 아래에서 유효합니다. 이 가정은 두 가지를 뜻합니다.
독립(Independent): 각 표본이 서로 영향을 주지 않습니다. 그래서 데이터의 순서를 섞거나 일부를 더하고 빼도 의미가 달라지지 않습니다.
동일 분포(Identically Distributed): 훈련 데이터와 시험 데이터가 같은 확률 분포에서 추출됩니다. 시험 데이터가 훈련 데이터와 다른 분포라면, 훈련에서 좋았던 모델도 제대로 동작하지 않습니다.
이 가정은 기계학습 모델을 훈련하고 평가하는 전제가 됩니다.