통계적 추론은 데이터를 기반으로 모집단에 대한 결론을 도출하는 통계학의 한 분야입니다. 표본을 사용하여 모집단에 대한 정보를 추정하거나 가설을 검증하는 데 사용됩니다. 통계적 추론은 크게 두 가지 방법으로 나눌 수 있습니다:
추정(Estimation): 추정은 표본을 기반으로 모집단의 모수를 추정하는 과정입니다. 이때 사용되는 기법은 점 추정과 구간 추정이 있습니다.
점 추정(Point Estimation): 모집단의 모수를 하나의 값으로 추정하는 방법입니다. 예를 들어, 표본 평균을 이용하여 모집단의 평균을 추정하는 것이 그 예시입니다.
구간 추정(Interval Estimation): 모수의 가능한 값의 범위를 추정하는 방법으로, 보통 신뢰구간을 사용합니다. 예를 들어, 95% 신뢰구간은 해당 구간에 모수가 포함될 확률이 95%라는 것을 의미합니다.
가설 검정(Hypothesis Testing): 가설 검정은 모집단에 대한 가설이 참인지 거짓인지를 결정하기 위해 표본 데이터를 사용하는 과정입니다.
귀무가설(Null Hypothesis, (H_0)): 가설 검정에서 검정하고자 하는 가설로, 보통 '모집단 간에 차이가 없다’는 것과 같은 보수적인 진술을 의미합니다.
대립가설(Alternative Hypothesis, (H_1)): 귀무가설이 거짓이라는 것을 보여주는 가설입니다.
유의수준(Significance Level): 귀무가설을 기각하는 기준이 되는 확률값으로, 보통 0.05나 0.01 등의 값을 사용합니다.
추가적으로, 통계적 추론은 파라메트릭 방법(모수적 방법)과 논파라메트릭 방법(비모수적 방법)으로 분류될 수 있습니다. 모수적 방법은 데이터의 분포에 대한 가정을 하며, 비모수적 방법은 가정을 최소화하면서 데이터를 분석하는 방식입니다.
통계적 추론은 다양한 분야에서 유용하게 활용됩니다. 예를 들어, 의학 연구에서 새로운 치료법의 효과를 검증하거나 마케팅 분야에서 고객 선호도를 분석하는 데 사용됩니다.
1최대가능도 추정¶
앞서 점 추정은 표본으로부터 모집단의 모수를 하나의 값으로 추정하는 것이라고 했습니다. 대표적인 점 추정 방법이 최대가능도 추정(maximum likelihood estimation, MLE) 입니다. 관측된 데이터가 나타날 가능성, 즉 우도(likelihood) 를 가장 크게 만드는 모수를 추정값으로 택하는 방법입니다.
100개의 씨앗을 심었을 때, 열 개 이하의 씨앗이 발아했습니다. 발아한 씨앗의 정확한 수는 알려지지 않았습니다. 이 경우, 씨앗의 발아 확률을 추정하고자 합니다.
관측된 결과(발아 10개 이하)가 나타날 확률을 발아 확률 의 함수로 본 것이 우도 함수(likelihood function) 입니다.
여기서 은 심은 씨앗 수, 는 발아 확률, 는 발아한 씨앗 수입니다.
import numpy as np
from scipy.special import comb
import matplotlib.pyplot as plt
L = lambda n, X, param: sum(comb(100, x) * (param ** x) * ((1 - param) ** (n - x)) for x in range(0, X + 1))
p = np.arange(0, 1, 0.01)
plt.plot(p, L(n=100, X=10, param=p))
plt.xlim(0, 0.3)
plt.show()
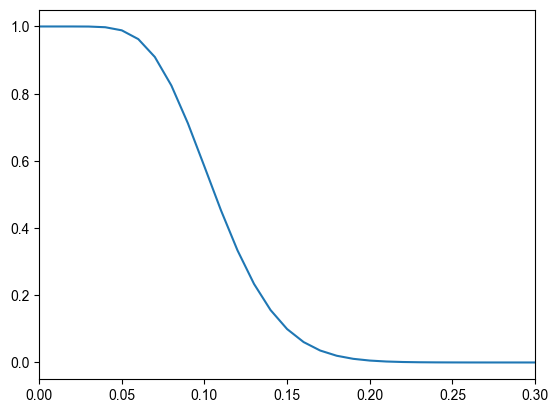
우도 함수를 모수 에 대해 그려 보면, 우도를 최대로 만드는 가 어디인지 확인할 수 있습니다. 그 값이 곧 최대가능도 추정값입니다. 이처럼 우도를 기준으로 모수를 추정하는 방식은 많은 기계학습 모델의 학습 원리와도 맞닿아 있습니다.