1활용 소프트웨어¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
# print version
print('numpy version:', np.__version__)
print('pandas version:', pd.__version__)
print('sklearn version:', sklearn.__version__)numpy version: 2.2.6
pandas version: 2.3.3
sklearn version: 1.7.2
모델 평가용 유틸리티 함수 정의
from sklearn.model_selection import train_test_split
def 모델평가(model, X, y, print_scores=True, **설정):
X_train, X_test, y_train, y_test = train_test_split(X, y, **설정)
model.fit(X_train, y_train)
훈련성능 = model.score(X_train, y_train)
시험성능 = model.score(X_test, y_test)
if print_scores:
print(f'[성능] 훈련: {훈련성능:.3f}, 시험: {시험성능:.3f}')
else:
return {'train': 훈련성능, 'test': 시험성능}2서포트 벡터 머신의 발전¶
서포트 벡터 머신(Support Vector Machine, SVM)은 기계 학습 분야에서 널리 사용되는 강력한 분류 및 회귀 알고리즘입니다. SVM은 커널 트릭을 사용하여 비선형 문제를 해결할 수 있으며, 데이터를 분류하기 위해 결정 경계를 찾는 데 주로 사용됩니다.
SVM의 발전은 다음과 같은 주요 단계로 나눌 수 있습니다:
기본 SVM: 처음에는 선형 SVM이 개발되었습니다. 이는 선형적으로 분리 가능한 데이터에 대해 사용됩니다. 선형 SVM은 데이터를 가장 잘 분류할 수 있는 초평면을 찾아내는 것이 주요 목표입니다.
비선형 SVM: 실제 데이터는 종종 선형적으로 분리되지 않기 때문에, 비선형 데이터를 분류하기 위해 커널 트릭이 도입되었습니다. 커널 트릭은 데이터를 고차원 공간으로 매핑하여 선형 분리가 가능하도록 만듭니다. 이로써 비선형 데이터를 선형 SVM으로 분류할 수 있게 되었습니다.
다양한 커널 함수: SVM에서 사용되는 커널 함수는 데이터를 고차원 공간으로 매핑하는 데 사용됩니다. 초기에는 선형 및 다항식 커널이 널리 사용되었지만, 후에 가우시안 RBF(Radial Basis Function) 커널과 같은 다른 커널 함수들이 도입되었습니다. 이러한 다양한 커널 함수는 더 복잡한 패턴을 분류할 수 있도록 도와줍니다.
정규화 및 최적화: SVM은 이상치에 민감할 수 있으므로, 정규화 및 최적화 기술이 개발되었습니다. 이러한 기술은 모델의 일반화 성능을 향상시키고 과적합을 방지하는 데 도움이 됩니다.
대규모 및 다중 클래스 분류: SVM은 대규모 데이터셋 및 다중 클래스 분류에도 적용될 수 있도록 발전되었습니다. 이를 위해 효율적인 최적화 알고리즘과 다중 클래스 분류 기법이 개발되었습니다.
임의의 커널: 최근에는 SVM에서 임의의 커널을 사용하는 방법이 연구되고 있습니다. 이는 데이터에 맞게 커널을 설계하는 데 도움이 됩니다.
이러한 발전으로 인해 SVM은 다양한 분야에서 널리 사용되며, 기계 학습 및 패턴 인식 분야에서 중요한 역할을 하고 있습니다.
3서포트 벡터 머신의 원리¶
SVM(Support Vector Machine)은 분류(classification)와 회귀(regression) 문제를 해결하기 위해 사용되는 강력한 머신러닝 모델입니다. SVM의 기본 원리는 데이터를 범주에 따라 분리하는 최적의 결정 경계(하이퍼플레인)를 찾는 것입니다. 이 결정 경계는 두 범주의 데이터 사이에 최대 마진을 갖도록 설계됩니다.
3.1SVM의 주요 개념¶
하이퍼플레인(Hyperplane):
하이퍼플레인은 고차원 공간에서 데이터를 분리하는 경계선입니다. 예를 들어, 2차원 공간에서는 선이고, 3차원에서는 평면입니다.
마진(Margin):
마진은 하이퍼플레인과 가장 가까운 훈련 데이터 포인트(서포트 벡터) 사이의 거리입니다. SVM은 이 마진을 최대화하는 하이퍼플레인을 찾으려고 합니다.
서포트 벡터(Support Vectors):
서포트 벡터는 결정 경계에 가장 가까이 있는 각 범주의 데이터 포인트입니다. 이 포인트들은 마진 경계에 위치하며, 하이퍼플레인의 위치와 방향을 결정하는 데 중요한 역할을 합니다.
3.2SVM의 학습 방법¶
SVM 모델을 학습시키는 과정은 주어진 훈련 데이터에서 최적의 하이퍼플레인을 찾는 최적화 문제로 구성됩니다. 이 최적화 문제는 다음과 같은 제약 조건을 가지며 해결됩니다:
각 데이터 포인트가 올바른 범주에 속하도록 하이퍼플레인의 방정식을 조정합니다.
데이터 포인트와 하이퍼플레인 사이의 마진을 최대화합니다.
3.3커널 트릭(Kernel Trick)¶
비선형 분류 문제의 경우, 원래 특성 공간에서는 선형적으로 분리할 수 없을 때가 많습니다. SVM은 커널 트릭을 사용하여 이 문제를 해결합니다. 커널 함수는 원래 데이터를 더 높은 차원으로 매핑하여, 높은 차원에서는 선형적으로 분리가 가능하게 합니다. 이 방식으로 비선형 패턴도 학습할 수 있습니다.
3.4SVM의 사용 사례¶
SVM은 이미지 분류, 의료 분석, 텍스트 분류 등 다양한 영역에서 뛰어난 성능을 보여줍니다. 하지만, 매개변수 선택(커널 선택, C값 설정 등)과 큰 데이터 세트에 대한 계산 비용이 높다는 단점도 있습니다.
SVM은 그 강력한 성능 덕분에 여전히 많은 분야에서 활용되며, 특히 복잡한 분류 문제에서 그 장점이 두드러집니다.
4선형 모형으로서의 SVM¶
SVM의 기본 틀은 선형 모형이라고 할 수 있다. SVM(Support Vector Machine)의 기본적인 틀은 선형 모형을 기반으로 합니다. 기본적으로 SVM은 입력 데이터를 선형 결정 경계(하이퍼플레인)를 사용하여 두 범주로 분리하려고 시도합니다. 이 선형 결정 경계는 데이터 포인트 사이에서 가능한 가장 큰 마진을 가지는 방향으로 설정됩니다.
4.1선형 SVM¶
선형 SVM에서는 데이터가 선형적으로 분리 가능한 경우, 즉 두 범주를 직선(또는 고차원에서의 평면)으로 분리할 수 있는 경우에 사용됩니다. 선형 SVM의 목적은 다음과 같은 최적화 문제를 해결하는 것입니다:
결정 경계(하이퍼플레인)와 가장 가까운 데이터 포인트(서포트 벡터) 간의 거리, 즉 마진을 최대화합니다.
모든 데이터 샘플이 올바른 범주에 분류되도록 합니다.
이를 수학적으로 표현하면, 하이퍼플레인의 방정식 을 만족시키는 (가중치 벡터)와 (편향)를 찾는 것이 목표입니다. 여기서 는 벡터의 내적을 의미합니다.
4.2비선형 SVM과 커널 트릭¶
현실의 많은 문제는 선형적으로 분리가 가능하지 않기 때문에, SVM은 커널 트릭을 사용하여 이를 해결합니다. 커널 트릭은 데이터를 고차원 공간으로 매핑하여 선형 분리가 가능하게 하는 기법입니다. 이 과정은 여전히 선형 모형의 원리를 활용하지만, 변환된 고차원 공간에서 수행됩니다.
따라서 SVM은 근본적으로 선형 모형이지만, 커널 트릭을 통해 비선형 문제에도 유연하게 적용할 수 있는 강력한 도구로 활용됩니다.
5결정 경계의 일반화 품질¶
SVM은 결정 경계의 일반화 품질에 초점을 맞춘 모델로 평가할 수 있다. SVM(Support Vector Machine)은 특히 결정 경계의 일반화 능력을 향상시키기 위해 설계된 모델입니다. 이는 결정 경계와 가장 가까운 훈련 샘플들(서포트 벡터) 사이의 마진을 최대화함으로써 달성됩니다. 이러한 접근 방식은 결정 경계 주변의 작은 변동이나 노이즈에 대한 모델의 민감도를 줄이는 데 도움을 주어, 새로운 데이터에 대한 모델의 예측 성능을 향상시키는 결과를 가져옵니다.
5.1일반화 품질에 초점을 맞춘 이유¶
마진 최대화: SVM에서는 분류 오류를 최소화하는 것과 함께, 마진(결정 경계와 서포트 벡터 사이의 거리)을 최대화하는 것이 주요 목표입니다. 마진을 크게 하는 것은 훈련 데이터에 대한 작은 변화에도 모델이 견고하게 반응하도록 하여, 테스트 데이터에 대한 일반화 성능을 향상시킵니다.
오버피팅 방지: 큰 마진은 모델이 훈련 데이터의 개별적인 특징보다는 데이터의 전반적인 패턴을 학습하도록 유도합니다. 이는 훈련 데이터에 대해 과도하게 최적화되는 것(오버피팅)을 방지하는 데 도움이 됩니다.
구조적 위험 최소화(SRM): SVM은 구조적 위험 최소화 원칙을 따르는 알고리즘으로 분류됩니다. 이 원칙은 모델 복잡성과 훈련 데이터에 대한 오류율 사이의 균형을 고려하여, 실제 운영 환경에서의 성능 저하를 최소화합니다.
5.2실제 적용¶
SVM의 이러한 특성은 특히 불확실한 데이터나 노이즈가 많은 환경에서 그 가치가 드러납니다. 예를 들어, 생물학적 데이터 분석, 음성 인식, 손글씨 인식 등의 분야에서 SVM은 데이터의 기본 구조를 잘 파악하고 일반화하는 데 효과적인 것으로 평가받고 있습니다.
결국, SVM은 훈련 데이터의 특이 케이스에 대해 덜 민감하고, 일반적인 케이스에 대해 보다 견고한 예측을 제공하는 방식으로 설계되었습니다. 이는 실제 세계의 복잡하고 동적인 문제에 매우 적합한 접근법입니다.
6결정 경계 품질¶
같은 데이터 분포에 대해 분류를 수행하는 서로 다른 결정 경계를 가정해 보겠습니다. 여기서 제시되는 결정 경계들은 모두 훈련 데이터를 완벽하게 분류하는 최적화를 수행합니다. 하지만 일부 결정 경계는 다른 결정 경계에 비해 아슬아슬하게 보일 수 있습니다. 왜냐하면 최적화적으로는 완벽하지만, 새로운 데이터 포인트가 주어졌을 때 첫 번째 결정 경계는 분류를 실패하는 반면, 두 번째 결정 경계는 여유롭게 성공하기 때문입니다.
이후를 평가해 보면, 결정 경계가 특정 데이터 포인트에 너무 가깝게 형성되어 있는 것이 문제로 보입니다. 아슬아슬하게 최적화에 성공하거나 여유롭게 성공하는 경우에도, 기존의 선형 모델 방법들은 최적화적인 측면에서 문제가 없다면 수렴을 성공적으로 달성할 수 있습니다. 그러나 1980년대의 통계적 기계 학습을 통해 기계 학습이 달성해야 하는 중요한 목표가 일반화라는 점을 고려한다면, 최적화 과정에서 수렴하는 것만으로는 부족할 수 있다는 것을 이해할 수 있습니다.
이를 뒷받침하기 위해, 데이터 분포를 기반으로 서로 다른 결정 경계를 가진 모델을 비교하는 파이썬 시각화 코드를 작성할 수 있습니다. 이를 위해서는 데이터를 생성하고, 선형 모델 또는 커널 기반 SVM 모델을 사용하여 다른 결정 경계를 구성해야 합니다. 그리고 각 결정 경계를 시각화하여 새로운 데이터 포인트가 주어졌을 때 모델의 일반화 성능을 평가합니다.
아래는 파이썬을 사용하여 데이터 분포와 모델의 결정 경계를 시각화하는 예시 코드입니다. 여기서는 sklearn 라이브러리를 사용하여 데이터를 생성하고, SVM 모델을 훈련시킨 다음 결정 경계를 시각화합니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
# 데이터 생성
np.random.seed(0)
X, y = datasets.make_blobs(n_samples=100, centers=2, cluster_std=1.0, random_state=0)
# 두 가지 다른 결정 경계를 가진 두 모델 설정
model1 = SVC(kernel='linear', C=1.0) # 첫 번째 결정 경계 (아슬아슬한 분류)
model2 = SVC(kernel='linear', C=100.0) # 두 번째 결정 경계 (여유로운 분류)
# 모델 훈련
model1.fit(X, y)
model2.fit(X, y)
# 그리드 설정
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
# 모델의 결정 경계 시각화
plt.figure(figsize=(10, 5))
# 첫 번째 결정 경계 시각화
Z1 = model1.predict(np.c_[xx.ravel(), yy.ravel()])
Z1 = Z1.reshape(xx.shape)
plt.subplot(1, 2, 1)
plt.contourf(xx, yy, Z1, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, edgecolor='k', alpha=0.8)
plt.title('Model with C=1.0 (Tight Margin)')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 두 번째 결정 경계 시각화
Z2 = model2.predict(np.c_[xx.ravel(), yy.ravel()])
Z2 = Z2.reshape(xx.shape)
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, Z2, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, edgecolor='k', alpha=0.8)
plt.title('Model with C=100.0 (Wide Margin)')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.tight_layout()
plt.show()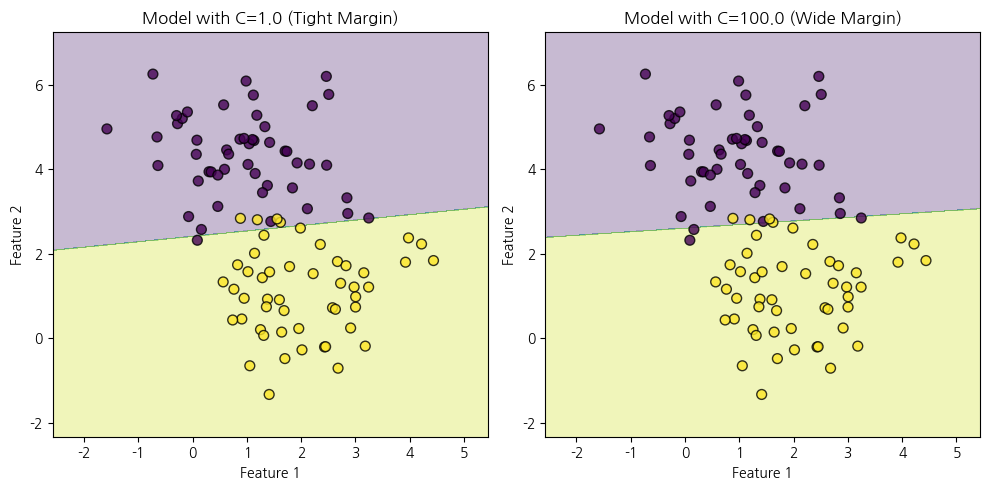
이 예제에서는
sklearn.datasets에서 제공하는make_blobs함수를 사용하여 2개의 중심을 가진 데이터 분포를 생성합니다.SVC모델을 두 번 생성하여 다른C값(1.0과 100.0)을 사용해 각 모델을 훈련시킵니다.C값은 SVM 모델의 하이퍼파라미터로, 결정 경계의 폭을 제어합니다. 작은C값은 모델이 폭넓은 마진을 가지도록 하고, 큰C값은 모델이 데이터에 더 민감하도록 합니다.각 모델의 결정 경계를 시각화하여 서로 다른 결정 경계를 비교합니다.
이 코드를 실행하면, 아슬아슬한 분류(C=1.0)를 가진 모델과 여유로운 분류(C=100.0)를 가진 모델의 결정 경계를 시각화하여 비교할 수 있습니다.
6.1C 매개변수의 역할과 연산 방식¶
sklearn.svm.SVC(C=1.0)는 C 값이 1.0인 SVM(Support Vector Classification) 모델을 생성합니다. C는 SVM 모델의 하이퍼파라미터로, 모델의 규제(regularization) 강도를 제어합니다.
6.2C의 역할¶
C는 오차에 대한 벌점의 정도를 결정하는 매개변수입니다. 이를 통해 결정 경계의 폭과 유연성을 조정할 수 있습니다.C값이 작으면 모델이 폭넓은 마진을 가지면서 약간의 오차를 허용합니다. 즉, 일부 데이터 포인트가 결정 경계에서 벗어날 수 있습니다. 이는 모델이 데이터에 덜 민감해지며 일반화 능력이 높아질 수 있습니다.C값이 크면 모델이 데이터에 매우 민감해져, 결정 경계가 데이터 포인트에 밀접하게 맞춰집니다. 이는 훈련 데이터에 매우 정확할 수 있지만, 과적합(overfitting)의 위험이 있습니다.
6.3연산 방식¶
SVM은 주어진 데이터와 레이블을 기반으로 결정 경계를 찾는 데 초점을 맞춥니다. 이때 C는 모델의 목적 함수를 구성하는 데 영향을 미치는 매개변수입니다.
SVM의 목적 함수는 다음과 같습니다:
여기서:
: 모델의 가중치 벡터
w의 제곱합으로, 이 항목을 최소화하여 마진을 최대화합니다.: 는 오차(슬랙 변수 )에 대한 벌점을 부여합니다.
n: 훈련 데이터의 수입니다.: 슬랙 변수로, 데이터 포인트가 결정 경계에서 벗어나는 정도를 나타냅니다.
C값이 크면 오차에 대한 벌점이 높아지기 때문에 모델이 데이터에 더 정확히 맞추려고 합니다. 이로 인해 결정 경계가 데이터에 더 가깝게 위치하게 됩니다.반대로
C값이 작으면 오차에 대한 벌점이 낮아지기 때문에 모델이 데이터에 약간의 유연성을 허용합니다. 이는 결정 경계가 데이터 포인트에서 더 떨어져 위치하도록 유도합니다.
요약하자면, C는 SVM 모델의 규제 강도를 조절하여 마진의 폭과 모델의 유연성을 결정합니다. 이 값은 과소적합과 과적합을 조절하는 중요한 하이퍼파라미터로, 모델의 일반화 성능에 큰 영향을 미칩니다.
6.4서포트 벡터 범위¶
SVM 모델의 C 매개변수가 결정 경계에 미치는 영향을 시각화하기 위해 Python의 matplotlib과 sklearn 라이브러리를 사용할 수 있습니다. 아래 예시 코드는 두 개의 서로 다른 C 값에 대해 SVM 분류기의 결정 경계를 시각화하여 보여줍니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
# 데이터셋 생성
X, y = make_blobs(n_samples=100, centers=2, random_state=6)
# SVM 모델 설정: C 값이 다른 두 모델
clf1 = svm.SVC(kernel='linear', C=0.1)
clf2 = svm.SVC(kernel='linear', C=1000)
# 모델 학습
clf1.fit(X, y)
clf2.fit(X, y)
# 데이터와 결정 경계 시각화를 위한 함수
def plot_decision_boundary(clf, X, y, C, ax):
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired, edgecolors='k')
ax.axis('tight')
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 결정 경계 그리기
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50),
np.linspace(ylim[0], ylim[1], 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 마진과 결정 경계 시각화
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
ax.set_title(f'결정경계: C = {C}')
# 플롯 설정
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
plot_decision_boundary(clf1, X, y, clf1.get_params()['C'], ax[0])
plot_decision_boundary(clf2, X, y, clf2.get_params()['C'], ax[1])
plt.show()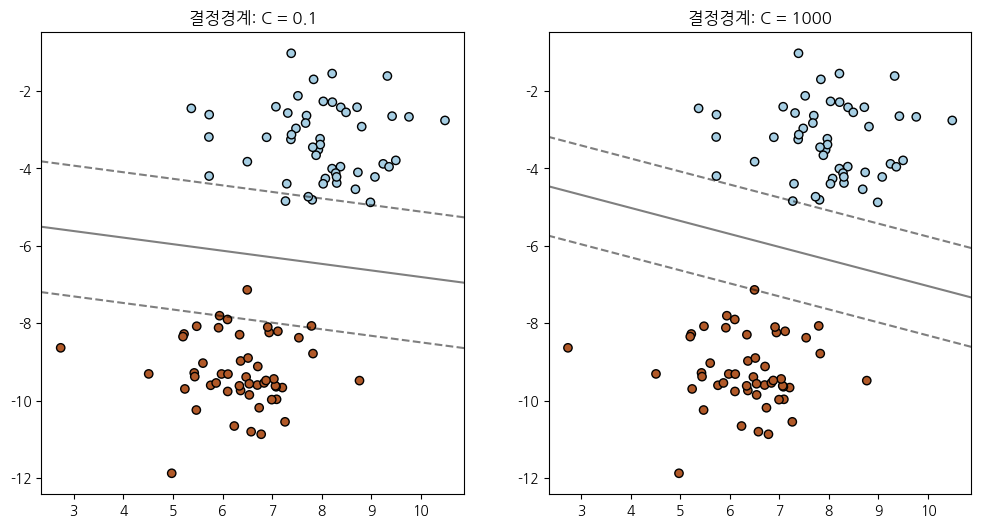
이 코드는:
가상의 이진 분류 데이터셋을 생성합니다.
두 개의 SVM 모델을 각각 다른
C값 (1과 100)으로 학습시킵니다.각 모델의 결정 경계와 마진을 시각화하여,
C값에 따른 마진 크기와 결정 경계의 변화를 보여줍니다.
선형 커널을 활용한 SVM 분류기 훈련과 결과 시각화
from sklearn.svm import SVC
model = SVC(kernel='linear', C=1.0).fit(X, y)
y_pred = model.predict(X)
f = lambda x0, w, b: -(w[0]/w[1]) * x0 + b/-w[1]
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.plot(X[:, 0], f(X[:, 0], model.coef_[0], model.intercept_), 'k--')
# Support Vectors
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], marker='x', color='red', s=80)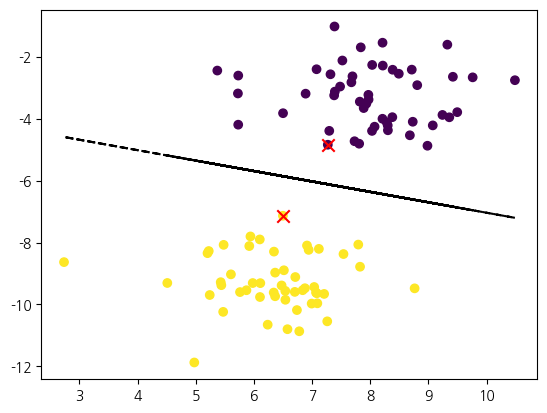
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
# 데이터 정의
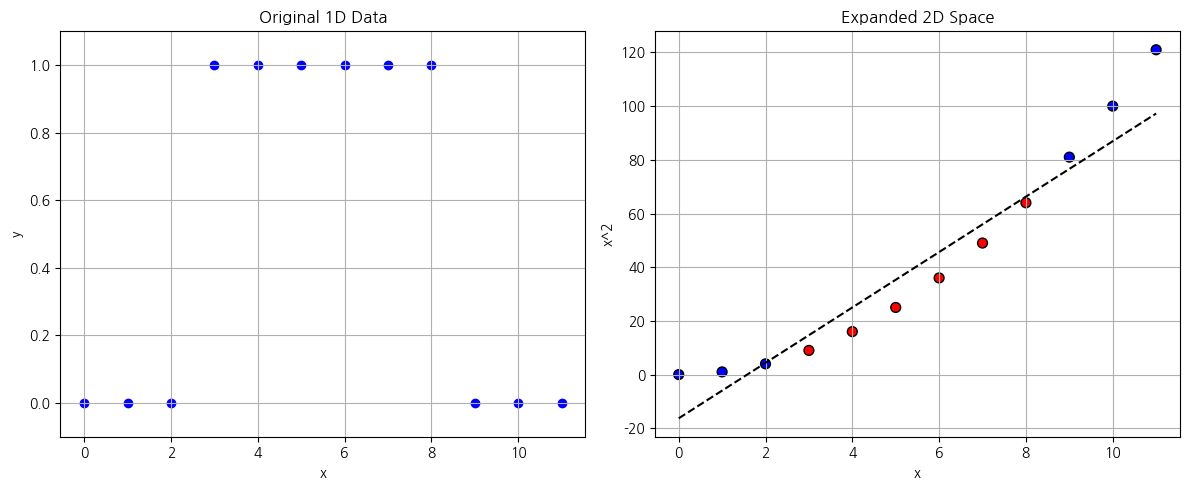
x = np.array(range(12))
y = np.array([0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0])
logreg = SVC(kernel='linear').fit(x.reshape(-1, 1), y)
print(f'정확도: {logreg.score(x.reshape(-1, 1), y):.0%}')
# 원본 데이터 시각화
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(x, y, color='blue', label='Original Data')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Original 1D Data')
plt.ylim(-0.1, 1.1)
plt.grid(True)
# 2차원 확장: x와 x^2
x_expanded = np.vstack([x, x**2]).T
logreg = SVC(kernel='linear').fit(x_expanded, y)
print(f'정확도: {logreg.score(x_expanded, y):.0%}')
결정경계 = lambda x, w, b: -(w[0] * x + b) / w[1]
# 확장된 데이터 시각화
plt.subplot(1, 2, 2)
plt.scatter(x_expanded[:, 0], x_expanded[:, 1], c=y, cmap='bwr', edgecolor='k', s=50)
plt.plot(x, 결정경계(x, logreg.coef_[0], logreg.intercept_[0]), 'k--')
plt.xlabel('x')
plt.ylabel('x^2')
plt.title('Expanded 2D Space')
plt.grid(True)
plt.tight_layout()
plt.show()정확도: 50%
정확도: 92%
7응용¶
from sklearn.datasets import make_classification
from sklearn.utils import Bunch
_X, _y = make_classification(n_samples=400, n_features=10, n_informative=6,
n_redundant=2, random_state=0)
분류 = Bunch(data=_X, target=_y,
feature_names=[f'특성{i+1}' for i in range(10)],
target_names=['유형0', '유형1'])from sklearn.svm import LinearSVCfrom sklearn.preprocessing import MinMaxScaler
X_분류 = MinMaxScaler().fit_transform(분류.data)
모델평가(LinearSVC(C=1.0), X_분류, 분류.target, random_state=0)[성능] 훈련: 0.820, 시험: 0.880
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
X_분류 = MinMaxScaler().fit_transform(분류.data)
모델평가(LogisticRegression(C=1.0), X_분류, 분류.target, random_state=0)[성능] 훈련: 0.797, 시험: 0.790
비선형 커널
from sklearn.datasets import make_blobs
from sklearn.svm import LinearSVC, SVC
X, y = make_blobs(centers=4, random_state=8)
y = y % 2
lsvc = LinearSVC(C=1.0).fit(X, y)
print(f'선형 커널 최적화: {lsvc.score(X, y)}')
svc = SVC(kernel='poly', degree=2, C=1.0).fit(X, y)
print(f'비선형 커널 최적화: {svc.score(X, y)}')
# 선형 커널 결정경계
w = lsvc.coef_[0]
b = lsvc.intercept_
z = lambda x: (w[0] / -w[1]) * x + (b / -w[1])
plt.plot(X[:, 0], z(X[:, 0]))
# 비선형 커널 SV
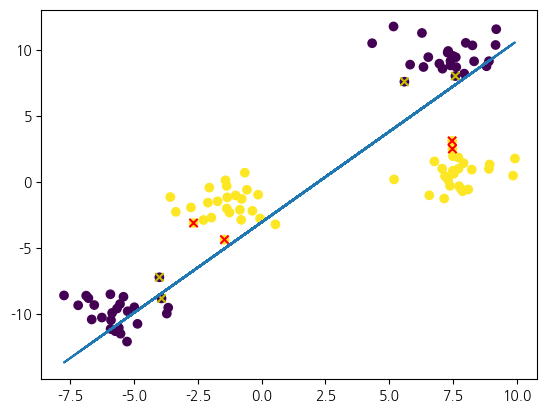
plt.scatter(X[:, 0], X[:, 1], c=svc.predict(X))
sv_labels = np.where(svc.dual_coef_.ravel() > 0, 'r', 'y')
plt.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], c=sv_labels, marker='x')
plt.show()선형 커널 최적화: 0.66
비선형 커널 최적화: 1.0