하나의 모델보다 여러 모델의 예측을 모으면 더 정확하고 안정적인 결과를 얻을 수 있습니다 — 집단 지성과 비슷한 원리입니다. 이렇게 여러 모델을 결합하는 방법을 앙상블(ensemble) 학습 또는 조합 학습이라 합니다.
결정 트리는 앙상블의 기본 단위로 널리 쓰입니다. 대표적인 앙상블 기법으로, 독립적인 트리들을 병렬로 만들어 결합하는 랜덤 포레스트와, 약한 모델을 순차적으로 보완하며 쌓는 부스팅이 있습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.utils import Bunch
from sklearn.model_selection import train_test_split
# 결정 트리 장에서 쓴 데이터/평가 함수를 그대로 사용합니다.
_X, _y = make_classification(n_samples=400, n_features=10, n_informative=6,
n_redundant=2, random_state=0)
분류 = Bunch(data=_X, target=_y,
feature_names=[f'특성{i+1}' for i in range(10)],
target_names=['유형0', '유형1'])
def 모델평가(model, data, target, **설정):
train_data, test_data, train_target, test_target = train_test_split(
data, target, **설정)
model.fit(train_data, train_target)
scores = {'train': model.score(train_data, train_target),
'test': model.score(test_data, test_target)}
return pd.Series(scores)1랜덤 포레스트¶
랜덤 포레스트(random forest) 는 다수의 결정 트리를 결합해 과적합을 개선하는 알고리즘입니다. 효과를 보려면 각 트리가 서로 다른 데이터를 학습해야 합니다. 부트스트랩 샘플링으로 원래 데이터에서 무작위 부분집합을 뽑아 트리마다 다른 데이터를 주고, 분기마다 특성도 일부만 무작위로 골라 다양성을 높입니다. 서로 다른 트리들의 예측을 모으면 노이즈에 덜 민감하고 일반화가 향상됩니다. 각 트리는 독립적이라 병렬로 학습할 수 있습니다.
from sklearn.ensemble import RandomForestClassifier분류_forest = RandomForestClassifier(n_estimators=100)
모델평가(분류_forest, 분류.data, 분류.target, stratify=분류.target)train 1.0
test 0.9
dtype: float64특성 중요도
pd.Series(분류_forest.feature_importances_,
index=분류.feature_names).plot(kind='barh')<Axes: >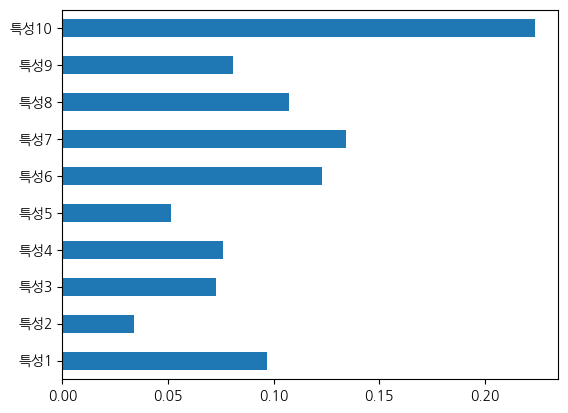
from sklearn.ensemble import RandomForestRegressor2Gradient Boosting Regression Tree (GBRT)¶
부스팅은 여러 약한 학습기를 순차적으로 학습시키는 앙상블 방법입니다. 랜덤 포레스트가 독립적인 트리들을 병렬로 만들어 결합하는 것과 달리, 부스팅은 앞선 트리가 틀린 부분을 다음 트리가 보완하도록 차례로 학습합니다. GBRT는 결정 트리를 약한 학습기로 사용해 이 방식을 구현한 대표적인 알고리즘입니다.
그래디언트 부스팅의 학습률을 이해하기 위한 간단한 의사 코드를 작성해보겠습니다. 이 의사 코드는 그래디언트 부스팅의 핵심 원리를 단순화하여 설명한 것입니다.
이 의사 코드는 다음 단계를 반복합니다:
초기 예측을 0으로 초기화합니다.
주어진 반복 횟수(예를 들어, 100번) 동안 다음을 수행합니다:
현재 예측과 실제 레이블 간의 잔차를 계산합니다.
이 잔차에 학습률을 곱하여 새로운 결정 트리 모델을 학습합니다.
새로운 모델의 예측 값을 가져옵니다.
학습률을 적용하여 새로운 모델의 예측 값을 현재 예측에 누적합니다.
그래디언트 부스팅이 완료되면 최종 예측을 사용하여 모델의 예측 성능을 평가합니다.
이 코드는 그래디언트 부스팅의 핵심 아이디어를 단순히 설명하기 위한 의사 코드이며, 실제 구현에서는 더 다양한 최적화 및 복잡한 모델이 사용됩니다.
그래디언트 부스팅의 학습률을 이해하기 위한 간단한 의사 코드를 작성해보겠습니다. 이 의사 코드는 그래디언트 부스팅의 핵심 원리를 단순화하여 설명한 것입니다.
이 의사 코드는 다음 단계를 반복합니다:
초기 예측을 0으로 초기화합니다.
주어진 반복 횟수(예를 들어, 100번) 동안 다음을 수행합니다:
현재 예측과 실제 레이블 간의 잔차를 계산합니다.
이 잔차에 학습률을 곱하여 새로운 결정 트리 모델을 학습합니다.
새로운 모델의 예측 값을 가져옵니다.
학습률을 적용하여 새로운 모델의 예측 값을 현재 예측에 누적합니다.
그래디언트 부스팅이 완료되면 최종 예측을 사용하여 모델의 예측 성능을 평가합니다.
이 코드는 그래디언트 부스팅의 핵심 아이디어를 단순히 설명하기 위한 의사 코드이며, 실제 구현에서는 더 다양한 최적화 및 복잡한 모델이 사용됩니다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import accuracy_score
# XOR 패턴 데이터 생성 (200개)
np.random.seed(0)
X_xor = np.random.randint(2, size=(200, 2))
y_xor = np.logical_xor(X_xor[:, 0], X_xor[:, 1]).astype(int)
# 데이터를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X_xor, y_xor, random_state=0)
# 그래디언트 부스팅 모델에서 학습된 결정 트리들을 저장할 리스트
trained_trees = []
# 초기 예측을 0으로 초기화
predictions = np.zeros(len(X_train))
learning_rate = 0.1
# 그래디언트 부스팅 루프 시작
for i in range(8):
# 현재 예측과 실제 레이블 간의 잔차 계산
residuals = y_train - predictions
# 잔차에 결정 트리 모델을 학습
tree = DecisionTreeRegressor(max_depth=3)
tree.fit(X_train, residuals)
# 학습된 결정 트리를 리스트에 추가
trained_trees.append(tree)
# 새로운 모델의 예측 값을 가져옴
new_predictions = tree.predict(X_train)
# 학습률을 적용하여 새로운 모델의 예측 값을 현재 예측에 누적
predictions = predictions + learning_rate * new_predictions
# 테스트 데이터에 대한 예측 수행
test_predictions = np.zeros(len(X_test))
for tree in trained_trees:
new_predictions = tree.predict(X_test) # 테스트 데이터에 대한 각 결정 트리의 예측
test_predictions = test_predictions + learning_rate * new_predictions # 학습률을 적용하여 현재 예측에 누적
# 테스트 데이터에 대한 예측 성능 평가 (이진 분류의 경우 정확도 사용)
test_accuracy = accuracy_score(y_test, np.round(test_predictions))
print("Test Accuracy:", test_accuracy)Test Accuracy: 1.0
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor분류_gbrt = GradientBoostingClassifier(n_estimators=100, max_depth=3, learning_rate=0.1)
모델평가(분류_gbrt, 분류.data, 분류.target, random_state=0)train 1.00
test 0.88
dtype: float64