이 장에서는 기계학습 모델로 예측을 수행하고, 모델을 훈련하고 평가하는 과정을 다룹니다. 데이터 적재와 탐색적 데이터 분석은 탐색적 데이터 분석 장에서 살펴본 붓꽃 데이터를 그대로 사용합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 붓꽃 데이터 — 탐색적 데이터 분석 장에서 적재한 데이터를 그대로 사용합니다.
iris = pd.read_csv('../data/iris.csv')
y = iris['유형']
X = iris.drop(columns='유형')1예측¶
(0:00) 기계 학습의 목표는 대체로 예측입니다. 새로운 데이터에 대한 예측일 수도 있고, 미래 시점에 대한 예측일 수도 있습니다. 붓꽃 데이터의 경우 새로운 붓꽃이 있을 때, 그것의 유형을 맞추는 것이 유형 예측이라고 할 수 있습니다.
(0:17) 예를 들어, 새로운 붓꽃을 구해 왔다고 하겠습니다. 그리고 같은 방식으로 특성을 수집했다고 가정하겠습니다. 새로운 벡터들을 2차원 산점도에서 표시해 보겠습니다. 이전과 동일한 그래프에서 이전과 같은 방식으로 산포도 그래프로 추가하면 됩니다. 새로운 벡터들을 잘 볼 수 있도록 색상을 검은색으로 설정하고 x 표로 표기하겠습니다.
(0:43) 어떠한 알고리즘의 도움없이 우리가 이런 붓꽃들을 실제로 보지 않고, 산점도 분포만으로 예측을 해보겠습니다. 대부분의 새로운 데이터 포인트에 대해 예측을 수월하게 수행할 수 있을 것 같은 느낌입니다. 붉은색과 초록색의 중간쯤에 있는 데이터는 어떤 것이 되어야 할지 고민스럽지만 파란색 유형은 확실히 아닐 것 같다는 생각이 듭니다. 이런 방식의 예측은 각 특징 벡터가 기존 표본 분포의 어떤 것에 더 가깝거나, 혹은 어떠한 영역에 속하는지 여부로 수행됩니다.
(1:19) 기본적인 방법이지만 실제 기계학습 알고리즘이 동작하는 원리에 가깝습니다. 우리가 느낌으로 수행하는 것을 수학적인 방법론으로 수행하고, 또한 지금 우리는 이 차원 평면의 분포를 가지고서 하지만, 실제로는 사 차원 이상 그리고 수십만 수백만 차원에서 이런 것들을 하려면 우리가 눈으로 보고 느낌을 가질 수는 없습니다. 그래서 만약 지금과 같은 기본적인 방법을 사용하더라도 대부분 우리가 관심 있는 데이터에 대해서는 기계 학습의 방법론을 사용해야 합니다.
특성목록 = X.columns
x1 = 특성목록[0]
x3 = 특성목록[2]
유형별_색상 = y.replace(np.unique(y), ['red', 'green', 'blue'])
X_new = np.array([(5.0, 1.0), (5.0, 2.5), (6.0, 3.5), (7.5, 5.5)])
plt.scatter(X[x1], X[x3], c=유형별_색상)
plt.scatter(X_new[:, 0], X_new[:, 1], marker='x', s=80, color='black')
# 유형 경계
plt.hlines(2.5, xmin=4, xmax=8, colors='magenta', linestyle='--')
plt.hlines(5.0, xmin=4, xmax=8, colors='cyan', linestyle='--')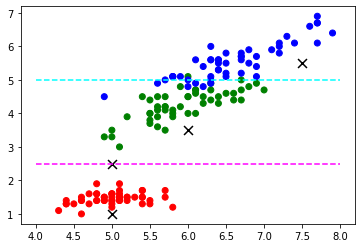
1.1기계학습 알고리즘¶
(0:00) 기계학습 알고리즘의 유형은 다양합니다. 그중 우리가 앞서 예측을 수행한 방식과 유사한 것을 활용해 보겠습니다.
(0:08) 직관적으로, 표본의 분포를 살펴봤을 때 해당 표본과 근접한 유형이 새로운 표본의 유형일 것이라고 예측하는 것은 너무나 자연스럽습니다. 이런 방법을 사용하는 알고리즘은 최근접 이웃 알고리즘이라고 합니다. 그리고 이것은 가장 기본적인 알고리즘입니다. 지금의 경우 우리도 눈으로 보고 할 수 있으니까 알고리즘도 수월하게 예측을 할 수 있을 것 같습니다. 그래서 한번 해보겠습니다.
(0:38) 최근접 이웃이 그러한 기계학습 알고리즘입니다. 예측을 할 때 기존의 표본들과 거리를 측정해서 가장 가까운 표본, 즉 최근접 이웃의 유형으로 예측을 수행합니다. 싸이킷런의 알고리즘은 각각 종류별로 구분되어 있습니다. 그래서 특정한 알고리즘을 가져오고자 할 때는 해당 알고리즘이 속한 하위 패키지에서 선택해야 합니다. neighbors 패키지에 있습니다. 알고리즘은 같은 원리라도 출력에 따라 다르게 구현되어 있습니다. 현재 우리는 유형 분류를 수행하려고 하는 것이기 때문에 “classifier”, 즉 “분류기”로 끝나는 것을 선택합니다.
(1:21) 알고리즘을 선택하면 해당 알고리즘을 사용할 수 있도록 설정해야 합니다. 최근접 이웃 알고리즘은 가까운 이웃의 수가 중요한 설정입니다. 현재는 가장 가까운 이웃 하나를 선택해서 그것을 유형으로 분류하도록 하겠습니다. 가장 간단한 방식입니다.
(1:41) 설정한 모델은 데이터로 훈련해야 합니다. 훈련할 때 앞서 우리가 산점도로 분석한 방식으로 동일하게 수행하기 위해서는, 우리가 사용했던 특성 두개만을 가지고서 훈련을 하는 것이 필요합니다. 이때 XY를 각각 전달합니다. 또한 훈련 대상 데이터는 보통 numpy ndarray 형식이 좋습니다. 싸이킷런은 pandas 자료구조를 상대할 수 있지만 그것은 편의 기능이고 또한 모델이 훈련할 때는 특성의 명칭 같은 것은 사용되지 않기 때문입니다 그래서 사용되지 않는 정보는 가급적 제거해주는 것이 좋습니다.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=1)
model.fit(X[[x1, x3]].to_numpy(), y.to_numpy())(2:21) 훈련이 완료되면 이제 새로운 데이터에 대해 예측이 가능합니다. 우리가 준비한 네 개의 새로운 데이터 포인트가 있고 훈련된 알고리즘은 순식간에 예측을 수행합니다. 그 결과 다음과 같이 예측합니다.
y_pred = model.predict(X_new)
y_predarray(['setosa', 'versicolor', 'versicolor', 'virginica'], dtype=object)(2:37) 예측 결과를 이전의 그래프를 바탕으로 해서 시각화 해보겠습니다. 전체적으로 틀은 동일한데 새로운 데이터 포인트 이들의 유형을 색상으로 표현해 줄 수 있는 부분을 살짝 수정하고 이것을 활용해 예측 결과를 다음과 같이 시각화 할 수 있습니다. 그 결과 우리가 이전에 알고리즘의 도움없이 마음속으로 했을 법한 그런 결과가 동일하게 나온 것을 확인할 수 있습니다. 빨간색과 초록색의 경계선 위에 위치한 표본의 경우는 눈으로 보면 어느 쪽인지 분간하기가 어려워서 빨간색이나 초록색 어느 것이든 괜찮다고 생각하지만 현재 우리가 사용한 최근접 이웃 알고리즘은 초록색으로 분류를 했습니다. 이러한 결과는 충분히 받아들일 수 있다고 생각합니다.
특성목록 = X.columns
유형별_색상사전 = dict(zip(np.unique(y), ['red', 'green', 'blue']))
y_pred = pd.Series(y_pred)
y_pred.name ='예측'
plt.scatter(X[x1], X[x3], c=y.replace(유형별_색상사전))
plt.scatter(X_new[:, 0], X_new[:, 1], marker='x', s=80, color=y_pred.replace(유형별_색상사전))
# 유형 경계
plt.hlines(2.5, xmin=4, xmax=8, colors='magenta', linestyle='--')
plt.hlines(5.0, xmin=4, xmax=8, colors='cyan', linestyle='--')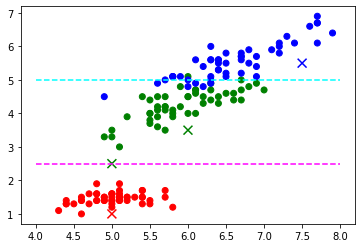
(3:24) 최근접 이웃 알고리즘은 훈련 시점에 경험한 데이터들을 기억하고 있다가 예측 요청이 발생하면 대상 벡터들과 기억해 둔 표본과 거리를 구해서 예측을 수행합니다. 거리를 측정하는 방식은 간단합니다. 기본적으로 유클리드 거리를 사용합니다. 유클리드 거리는 다음과 같이 간단하게 함수로 정의할 수 있습니다. 원칙적으로는 전체 결과에 대해 제곱근을 수행하는 것이 맞는데 제곱근을 안 해도 값의 대소 관계는 차이가 없기 때문에 편의를 위해서 생략하겠습니다. 그런 다음 예측하고자 하는 표본들과, 모델이 기억하고 있는 표본들의 거리를 다음과 같이 측정합니다. 그 결과를 내림차순으로 정렬하여 첫번째 표본을 선택하면 그것이 최근접 이웃입니다. 이렇게 선별된 이웃들을 다시 데이터프레임으로 만들어 취합하고, 마지막으로 모델이 예측한 값을 데이터프레임의 새로운 열로 추가하여 결과를 확인합니다. 그 결과 최근접 이웃의 유형과 예측이 일치하는 것을 확인할 수 있습니다. 지금 우리가 이렇게 구현한 것이 사실상 최근접 이웃 알고리즘입니다.
벡터거리측정 = lambda xi, xj: np.sum((xi - xj)**2)
이웃수 = 1
최근접_이웃들 = []
for xi in X_new:
표본과의_거리 = pd.Series(벡터거리측정(xi, xj) for xj in iris[[x1, x3]].to_numpy())
표본과의_거리.name = '거리'
최근접_이웃들.append(pd.concat([iris[[x1, x3, '유형']], 표본과의_거리], axis=1).sort_values(by='거리')[:이웃수])
최근접이웃표 = pd.concat(최근접_이웃들, ignore_index=True)
pd.concat([최근접이웃표, y_pred], axis=1)(4:37) 이제까지는 우리가 제시한 모든 표본에 대한 알고리즘의 예측이 우리 마음에 듭니다. 그런데 실제로 이 알고리즘이 진짜로 잘 동작할 찌는 좀 더 평가가 필요합니다. 지금의 유형이 세 가지인데 세 가지 중 하나를 맞출 확률은 3분의 1입니다. 그럼 네 개 정도의 표본에 대해서 정답을 맞출 확률은 찍어서 맞혀도 꽤 높은 편입니다. 물론 이것은 찍어서 맞춘 것은 아닙니다. 우리가 실제로 알고리즘을 대략적으로 구현해서 확인했을 때 이러한 방식이 우리가 기본적인 데이터 분석을 수행할 때 직관적으로 수행했을 법한 그런 방식이 맞기 때문입니다. 그런데 이러한 방식이 보다 더 많은 데이터에 대해서도 성공적으로 수행할 지를 평가하는 효과적인 방법이 필요합니다. 왜냐하면 네댓 개 정도의 표본을 예측하는 것은 굳이 기계학습 알고리즘이 필요하지 않기 때문입니다. 수천, 수만, 수십만, 수백만 개의 표본에 대해서 아마도 수행하고 싶을 겁니다. 그렇다면 보다 많은 새로운 표본에 대해 성공적으로 수행할지 어떻게 기대할 수 있을까요?
2훈련/시험 데이터¶
(0:00) 기계학습 모델을 훈련하고 평가하기 위해 전체 데이터를 훈련과 시험 데이터로 나누는 과정이 일반적입니다. 훈련 데이터는 모델의 훈련 시점에서 사용합니다. 시험 데이터는 훈련된 모델을 최종적으로 평가할 때 사용합니다. 이렇게 하는 이유는, 훈련한 데이터를 평가에 활용하는 것은 바람직하지 않기 때문입니다. 비유하자면, 훈련 데이터를 모의고사라고 했을 때, 시험 데이터는 수능 문제라고 할 수 있습니다. 모의고사 문제가 그대로 수능에 나오는 것은 바람직하지 않습니다. 모의고사 문제를 외워버릴 수 있기 때문입니다. 모의고사로 훈련을 하지만, 새로운 문제를 해결할 수 있을 때 학습이 제대로 되었다고 할 수 있습니다. 기계학습 모델의 경우도 마찬가지입니다. 기계학습 모델은 궁극적으로 새로운 데이터에 대해 예측을 할 때 사용할 목적으로 훈련합니다. 따라서, 훈련 시점에 보지 못한 새로운 데이터로 평가를 하는 것이 바람직하고, 그러한 새로운 데이터를 대표하는 것이 시험 데이터입니다.
(1:05) 훈련 시험 데이터를 나눌 때는, 전체에서 일부를 시험 데이터로 남겨두는 방식입니다. 시험 데이터를 어느 정도의 비율로 남겨둘 것인지는 원래 데이터의 양에 따라 적절하게 조절해야 합니다. 너무 적은 훈련 데이터는 훈련을 제대로 수행하기 어렵고, 반대로 너무 적은 시험 데이터는 제대로 성능을 평가하기 어렵습니다. 적절한 비율이 어느 정도인지는 데이터의 규모와 모델에 따라 다릅니다. 그래서 이것은 기계학습 모델을 훈련하고 평가하면서 조절해야 할 수 있습니다. 대체로 8대2 정도의 비율이 권장됩니다.
(1:42) 또한, 훈련 시험 데이터를 나누기 전에는 무작위로 데이터를 섞는 것이 대체로 바람직합니다. 섞지 않으면, 훈련 또는 시험 데이터에 특정 유형의 데이터만 쏠려 있는 상태에서 나누어지는 문제가 발생할 수 있기 때문입니다.
(1:58) 이제부터는 일부 특성을 선별하지 않고, 전체 특성을 모두 사용하겠습니다. 특정한 비율로 데이터를 나눠 보겠습니다. 시험 비율을 25%로 설정하겠습니다. 해당 비율에 대해 훈련 데이터의 표본수를 구합니다. 시험 데이터가 아닌 것은 모두 훈련 데이터로 하겠습니다. 따라서 75%가 됩니다. 이것을 훈련 데이터의 크기에 곱해 주고 그리고 난 다음 정수 로 변환하면 이것이 훈련 데이터의 표본 수가 됩니다. 이 값을 바탕으로 훈련과 시험 데이터를 나누어 획득합니다. 현재의 경우에 훈련 데이터가 아닌 것은 모두 시험 데이터 이기 때문에 훈련 데이터 표본수만 구하면 그 나머지 부분은 그것을 기준으로 선택하여 시험 데이터를 확보할 수 있습니다. XY 모두 같은 방식으로 나눠줍니다. 나눈 결과 X의 형상을 확인하는 것이 중요합니다. 전체 표본수가 150이고, 훈련 데이터 수는 75% 인 112, 시험 데이터 수는 25%에 해당하는 38입니다. 또한 XY 표본 수는 당연히 일치해야 합니다. 이 부분도 역시 확인합니다. 일치하지 않으면 예외가 발생하도록 했는데 예외가 발생하지 않기 때문에 일치하는 것을 효과적으로 확인할 수 있습니다.
시험_비율 = 0.25
훈련크기 = int(X.shape[0] * (1 - 0.25))
X_train = X[:훈련크기]
X_test = X[훈련크기:]
y_train = y[:훈련크기]
y_test = y[훈련크기:]
print(X.shape, X_train.shape, X_test.shape)
assert X_train.shape[0] == y_train.shape[0]
assert X_test.shape[0] == y_test.shape[0](150, 4) (112, 4) (38, 4)
(3:21) 나누고 나서 유형의 분포를 살펴보겠습니다. 그 결과 시험 데이터는 마지막 유형만 포함된 것을 확인할 수 있습니다. 그 이유는 현재 데이터가 유형별로 정렬이 되어 있기 때문입니다. 그래서 원래는 50 개씩 준비가 되어 있는데 지금처럼 시험 데이터의 수가 50개 이하인 경우 마지막 50개 범위만 시험 데이터에 포함되기 때문에 이런 문제가 생기는 것입니다. 당연히 이런 방식은 바람직하지 않습니다.
y_train.value_counts()setosa 50
versicolor 50
virginica 12
Name: 유형, dtype: int64y_test.value_counts()virginica 38
Name: 유형, dtype: int64(3:49) 데이터를 분리할 때, 어느 한쪽으로 쏠림이 발생하지 않았는지 확인하는 것이 중요합니다. 붓꽃의 경우 세 가지 유형이 있는데 어느 한 유형으로 치우쳐서 선택되고 나머지 유형들이 선택되지 않으면 제대로 학습과 평가가 이뤄지기 어렵습니다. 유형 데이터의 경우 원본의 도수 집계 결과와 훈련과 시험 데이터의 그것이 비슷한 양상을 보이는지 확인하는 것이 필요합니다. 확인 결과 원래의 분포는 세 가지 유형이 모두 균일하게 준비되어 있습니다. 이러한 균일성은 실제 붓꽃 유형들의 분포를 반영하기 보다는 데이터를 수집하는 사람이 결정한 것입니다. 대체로 유형의 경우는 이런 식으로 유형의 비율이 균일한 것이 바람직합니다. 그래야 훈련과 평가가 한쪽 유형으로 치우치지 않습니다.
(4:42) 그런데 지금 현재 상태를 살펴보면 훈련과 시험 데이터로 나눠진 것들의 도수 분포에서 어느 한쪽으로 쏠린 것을 확인할 수 있습니다. 이런 문제를 해결하는 기본적인 방법은 전체를 섞은 다음에 나누는 것입니다. 섞을 때 유의할 점이 하나 있습니다. x 와 y는 서로 쌍이 맞아야 합니다. 그렇기 때문에 섞을 때 XY 를 각각 따로 섞으면 안 됩니다. 그래서 섞인 순서를 무작위로 준비하고, 그 순서 자체를 XY 에 동시에 적용하여 최종적으로 섞은 효과를 내면서도 XY 쌍이 흐트러지지 않도록 해야 합니다. 그 다음 절차는 이전과 동일합니다.
섞인색인 = np.random.permutation(len(X))
X_random = X.loc[섞인색인]
y_random = y.loc[섞인색인]
시험_비율 = 0.25
훈련크기 = int(X.shape[0] * (1 - 0.25))
X_train = X_random[:훈련크기]
X_test = X_random[훈련크기:]
y_train = y_random[:훈련크기]
y_test = y_random[훈련크기:]
print(X.shape, X_train.shape, X_test.shape)
assert X_train.shape[0] == y_train.shape[0]
assert X_test.shape[0] == y_test.shape[0](150, 4) (112, 4) (38, 4)
(5:25) 원래의 x 와 훈련 데이터로 나눠진 데이터를 확인해 보면 훈련 데이터의 색인 번호가 x 와 다른 것을 확인할 수 있습니다. 무작위로 섞인 상태로 나누어진 것을 짐작할 수 있는 부분입니다. 이것은 매번 할 때마다 달라집니다. 그게 바로 무작위성입니다. 그래서 당연히 다를 수밖에 없습니다.
X_random[:3](5:46) 이전과 비교해서 유형의 분포를 살펴보면 대체로 훈련과 시험 데이터에 세가지 유형이 모두 포함됩니다. 물론 이것은 무작위로 수행하는 것이기 때문에 드물게 운이 없는 경우 2개 또는 하나의 유형만 섞일 확률이 없지는 않습니다. 하지만 대체로는 세 가지 유형이 훈련과 시험 데이터에 모두 포함됩니다. 그래서 섞지 않은 상태로 나눌 때 유형 분포의 불균형을 어느 정도 극복할 수 있습니다.
y_train.value_counts()virginica 39
setosa 37
versicolor 36
Name: 유형, dtype: int64y_test.value_counts()versicolor 14
setosa 13
virginica 11
Name: 유형, dtype: int642.1scikit learn API¶
싸이킷런은 훈련 시험 데이터 분리를 편리하게 수행할 수 있는 api를 제공합니다. XY를 각각 훈련과 시험 데이터로 나눌 수 있습니다. 이 때 무작위로 섞는 셔플과 시험 데이터 비율을 설정할 수 있습니다. 섞기는 기본적으로 설정되어 있고 시험 데이터 비율은 1/4, 즉25%가 기본입니다. 우리가 앞서 살펴본 대로 직접 구현하는 것이 가능합니다. 하지만 번거롭기 때문에 앞으로는 싸이킷런의 api 를 활용하겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=True, test_size=0.25)
print(X.shape, X_train.shape, X_test.shape)
assert X_train.shape[0] == y_train.shape[0]
assert X_test.shape[0] == y_test.shape[0](150, 4) (112, 4) (38, 4)
분리 결과를 확인해 보겠습니다. 훈련/시험 데이터 분리 결과, 우리가 지정한 25%가 시험 데이터로 남겨진 것을 확인할 수 있습니다. x 와 y는 서로 일대일로 대응해야 합니다. 그렇기 때문에 훈련과 시험 데이터를 나눌 때 x 와 y를 동시에 제공해서 분리해야 합니다. 확인할 때 XY의 개수가 서로 맞는지 확인하는 것이 필요합니다. 또한, XY는 서로 쌍이 맞아야 합니다. 기본적으로 무작위로 섞는 과정이 있기 때문에 동시에 나누지 않으면 개수가 맞아도 서로 쌍이 맞지 않을 수 있습니다. 그래서 동시에 나눠야 합니다.
2.1.1난수 초기값¶
그런데 경우에 따라서는 섞이는 순서가 동일하도록 우리가 통제할 필요가 있는 경우가 있습니다. 컴퓨터에서 난수는 유사 난수 알고리즘을 통해 생성됩니다. 이름에서 짐작할 수 있다시피 유사한 것이기 때문에 진정한 난수는 아닙니다. 그래서 우리가 통제할 수 있습니다 난수 초기값을 설정하여 섞는 순서가 결정적이도록 할 수 있습니다. random_state 인자에서, 영 이상의 정수를 난수 초기값으로 설정할 수 있습니다. 이 값은 무엇이든 상관없습니다. 어떤 의미가 있는 것도 아닙니다. 다만 같은 값으로 설정하면 같은 데이터에 대해서 섞는 순서가 언제나 고정됩니다. 그러면 애초에 섞지 않는 것과 마찬가지라고 혹시 생각한다면 그것과는 다릅니다. 예를 들어, 카드게임에 비유를 하면 새 카드덱을 꺼냈을 때는 모양과 숫자별로 정렬이 되어 있습니다. 만약에 이 상태를 가정하면 어떤 카드를 뽑은 다음에 다른 카드가 무엇일지 상당한 확신을 가지고 짐작할 수 있고 대체로 맞을 겁니다. 이것이 섞지 않은 상태입니다. 당연히 카드게임 에서는 카드를 섞어서 그 다음 카드가 무엇인지 예측할 수 없어야 재미가 있는 것입니다. 그런데 난수 초기값을 고정한다는 것은, 마치 타짜처럼 카드를 섞지만, 그 섞인 순서가 무엇인지를 직접 결정하는 것입니다. 그래서 우리가 경험을 통일하기 위해서 이번에는 난수 초기값을 고정하겠습니다. 어떤 값이든 상관없지만 같은 값으로 설정되었을 때 훈련과 시험 데이터의 차이가 발생하지 않으니까 모델을 훈련하고 평가하기에 좋을 것 같습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=True, test_size=0.25, random_state=0)
print(X.shape, X_train.shape, X_test.shape)
assert X_train.shape[0] == y_train.shape[0]
assert X_test.shape[0] == y_test.shape[0](150, 4) (112, 4) (38, 4)
난수 초기값을 고정하면 이제는 훈련 시험 데이터 분리를 여러 번 수행해도 매번 훈련 데이터가 동일한 순서로 표시되는 것을 확인할 수 있습니다.
X_train[:3]그런데 난수 초기값을 여러 번 바꿔도 유형들이 고르게 분포되도록 하는 것이 쉽지 않습니다. 그리고 설령 그런 값을 찾는다고 해도 이것은 데이터마다 다르기 때문에 이런 식으로 진행하는 것은 시행착오의 의존하는 것이라서 효과적인 방법이라고 하기 어렵습니다. 난수 초기값을 활용하는 이유가 이런 문제를 해결하기 위한 것은 아니기 때문입니다.
y_train.value_counts()virginica 41
setosa 37
versicolor 34
Name: 유형, dtype: int64y_test.value_counts()versicolor 16
setosa 13
virginica 9
Name: 유형, dtype: int642.1.2구간별 분리¶
유형이 있는 데이터의 경우, 각 유형별로 나눠지는 것이 바람직합니다. 같은 유형들끼리 서로 섞인 상태에서 지정된 비율로 각각 나눠지는 것입니다. 이렇게 하면 설령 각 유형들이 같은 비율이 아니더라도 결과적으로 나누어진 훈련과 시험 데이터는 원래의 분포를 최대한 그대로 반영하면서 나눠지게 됩니다. 이렇게 나누기 위해서 train_test_split API의 stratify 인자에 y 값을 전달합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=True, test_size=0.25, stratify=y, random_state=0)그 결과 훈련과 시험 데이터에서 각 유형의 분포가 원래 분포와 유사하게 나눠진 것을 확인할 수 있습니다. 이 결과는 어떤 난수 초기값을 설정하거나 또는 설정하지 않아도 이렇게 나눠지는 것을 보장합니다.
y_train.value_counts()virginica 38
versicolor 37
setosa 37
Name: 유형, dtype: int64y_test.value_counts()setosa 13
versicolor 13
virginica 12
Name: 유형, dtype: int64stratify는 구간화, 계층화 정도로 번역됩니다. 통계에서는 구간별로 무언가를 수행하는 것이 굉장히 중요합니다. 예를 들어, 선거의 출구조사를 가정하면, 표본수 절대값도 중요하지만 여러 인구학적 분포나 지역별 쏠림이 발생하지 않도록 해야 그 결과를 신뢰할 수 있게 됩니다. 만약 남성한테만 물어본 결과, 또는 특정 지역 사람들에게만 집중적으로 설문한 결과는 전체를 대표한다고 하기 어렵습니다. 그렇기 때문에 성별, 연령대별, 지역별 이런 식으로 여러 구간별로 같거나 유사한 수의 표본을 수집한 결과를 활용하는 것이 바람직합니다.
그런데 이것을 설정하면 무작위로 섞는 과정이 불필요한 것일까요? 애초에 섞는 이유가 우리가 앞서 살펴본 대로 섞지 않고 나누게 되면 어느 한쪽으로 쏠림이 발생합니다. 하지만 구간별로 잘 분리가 수행되는 경우에도 섞는 것이 바람직합니다. 왜냐하면 보통 데이터를 수집할 때는 수집의 편의상 유사한 것들끼리 수집이 되는 편입니다. 붓꽃의 경우 수집하는 시점에서 어느 한 종류의 대해서 전체적으로 특성을 측정한 다음, 다른 종류에 대해 수행하는 방식이 대체로 우리가 실제로 데이터를 수집할 때 기대할 만한 방식입니다. 또는, 병원에서 어떤 측정을 수행할 때는 병동이나 분과 등과 같은 유형들끼리 데이터가 모여서 수집되는 편입니다 무작위로 바꿔가면서 수집을 하는 것은 수집 시점에서는 불편하고 불필요합니다. 따라서, 설령 구간별로 분리를 수행함으로써 지금처럼 유형들이 어느 한쪽으로 쏠리지 않는다고 해도, 여전히 훈련 데이터와 시험 데이터가 각 구간 내에서 쏠림이 발생할 가능성이 있습니다. 따라서 각 구간 내에서도 섞은 다음에 나누는 것이 바람직합니다. 즉 예전에는 전체를 하나의 통에 넣고 흔들어서 섞은 상황에 비유할 수 있다면, 구간별로 섞는 것은 각 구간이 격벽으로 구분되어서 있는 상태로 통을 흔들어서 섞는다고 할 수 있습니다.
이러한 논의를 굉장히 상세하게 하고 있는데, 왜 그런가 하면 우리가 기계학습 알고리즘을 사용할 때는 훈련된 모델을 얼마나 신뢰할 수 있는지가 관건이기 때문입니다. 마치 선거에서 출구조사를 신뢰할 수 없으면 가치가 없는 것과 마찬가지입니다. 그래서 데이터 자체에 문제가 있으면 훈련과 평가 과정 전체를 신뢰할 수 없습니다. 설령 점수가 높아도 그것은 쉬운 데이터만을 받아서 그렇게 된 것일 수도 있고, 점수가 낮음에도 불구하고 실제로는 좋은 성능을 낼 수도 있습니다. 훈련 시점에서 어려운 데이터들을 상대하고 실제로는 쉬운 데이터를 받게 되면 그렇게 될 수 있습니다. 이 두 가지 모두 바람직한 상황이 아닙니다. 왜냐하면 우리는 기계학습을 훈련하고 나서 그 결과가 실제의 결과에 유사할 것이라는 기대를 할 수 있어야 안정적으로 활용할 수 있기 때문입니다. 그래서 지금처럼 처음 시작부터 데이터에 대해서 신경을 쓰는 것은 무척 중요합니다.
2.2평가¶
앞서 논의한 부분을 반영해 훈련과 시험 데이터를 나누겠습니다. 그런 다음 최근접 이웃 분류기를 훈련 데이터로 훈련합니다. 훈련한 모델의 성능을 평가하기 위해서 시험 데이터로 예측을 수행합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=True, test_size=0.25, stratify=y, random_state=0)
X_train = X_train.to_numpy()
X_test = X_test.to_numpy()
assert X_train.shape[0] == y_train.shape[0]
assert X_test.shape[0] == y_test.shape[0]model = KNeighborsClassifier(n_neighbors=1)
model.fit(X_train, y_train)y_pred = model.predict(X_test)예측 결과는 시험 데이터의 정답과 비교합니다. 일치하면 참이고 틀리면 거짓입니다. 참과 거짓은 숫자형이기 때문에 이것을 평균 내면 0과 1 사이 값으로 성능을 측정할 수 있습니다. 모두 다 완벽하게 예측을 했다면 1.0 이고 반대로 모두 다 틀렸다면 0.0입니다. 현재는 0.97을 얻었는데, 이것은 97 퍼센트의 정확도라고 할 수 있습니다. 높은 수준의 정확도입니다.
np.mean(y_pred == y_test)0.9736842105263158모델을 평가하는 일은 훈련된 모델에 대해서는 언제나 필요합니다. 그래서 예측 후에 성능을 측정하는 두 가지 절차를 내부적으로 수행하는 score 메소드를 사용하면 평가 절차가 간소해 편리합니다. 위의 결과와 당연히 동일한 값을 얻을 수 있습니다.
model.score(X_test, y_test)0.9736842105263158여기까지 올바르게 수행하기 위해서 논의해야 하는 사안들은 많았지만 결과적으로 봤을 때는 어떤 데이터에 대해서 기계학습 알고리즘을 훈련하고 평가한다는 것은 아주 적은 수의 코드로도 가능하다는 점을 살펴보았습니다.