탐색적 데이터 분석(Exploratory Data Analysis, EDA)은 데이터 세트의 특성을 이해하고 패턴을 발견하며 기본적인 통계를 통해 통찰력을 얻는 과정을 의미합니다. EDA의 목표는 데이터에 내재된 구조를 파악하고, 변수 간의 관계를 이해하며, 데이터의 이상치나 누락된 값 등을 식별하여 데이터 분석에 대한 전략을 수립하는 것입니다.
EDA의 주요 구성 요소는 다음과 같습니다:
데이터 요약: 데이터의 기본적인 통계량(평균, 중앙값, 분산, 표준편차 등)을 파악합니다.
데이터 시각화: 변수 간의 관계와 패턴을 쉽게 파악하기 위해 그래프나 플롯을 활용합니다. 주로 사용되는 시각화 기법은 히스토그램, 상자 그림, 산점도 등이 있습니다.
이상치 탐지: 데이터에 존재하는 이상치(outlier)를 식별하고 분석의 영향을 고려합니다.
상관관계 분석: 변수 간의 관계를 파악하고 예측에 영향을 줄 수 있는 요인을 찾습니다.
데이터 분포 이해: 데이터가 정규분포를 따르는지, 왜도나 첨도가 있는지 파악하여 통계적 가정을 검토합니다.
EDA는 분석의 첫 단계에서 매우 중요한 역할을 하며, 머신 러닝이나 통계 모델링을 수행하기 전에 데이터를 보다 잘 이해할 수 있도록 도와줍니다. 이를 통해 최종 모델의 성능을 향상시키는 데도 도움이 됩니다.
1통계 발전사 속의 탐색적 데이터 분석¶
탐색적 데이터 분석(Exploratory Data Analysis, EDA)은 통계의 발전 역사에서 고전적인 확증적 접근과 비교해 혁신적인 분석 방법론으로 평가됩니다. EDA는 데이터에 대한 열린 마음으로 접근하는 것의 중요성을 강조하며, 다음과 같은 발전사적 배경을 가지고 있습니다.
고전 통계학: 19세기 말부터 20세기 중반까지 고전 통계학의 발전은 가설 검정, 신뢰 구간, 추정 등 확증적 통계 분석에 중점을 두었습니다. 이때의 접근법은 먼저 가설을 세우고 데이터를 수집하여 가설 검증에 활용하는 것이 주류였습니다.
컴퓨터의 도입: 20세기 중반부터 통계학에 컴퓨터가 도입되면서 대규모 데이터를 처리하고 시각화하는 것이 점차 가능해졌습니다. 이는 통계 분석의 새로운 가능성을 열어주었고 데이터 분석에서 시각화의 중요성을 강조하게 되었습니다.
EDA의 등장: 1970년대에 통계학자 존 튜키(John Tukey)가 **탐색적 데이터 분석(EDA)**이라는 개념을 제시하면서 데이터 분석에 대한 시각이 변화하기 시작했습니다. 튜키는 데이터에 접근할 때 열린 마음으로 다양한 시각화 도구와 간단한 통계 기법을 사용해 데이터를 탐색하는 것이 중요하다고 주장했습니다. 확증적 분석과 대비되는 접근 방식인 EDA는 데이터의 본질과 구조를 더 잘 이해하고 통찰을 얻는 데 주안점을 두었습니다.
EDA의 주요 기법: EDA에서 강조된 기법에는 히스토그램, 상자 그림, 산점도, 수치적 요약 등이 있습니다. 이러한 시각화 및 요약 도구는 데이터의 패턴을 직관적으로 파악하고 예기치 못한 패턴이나 이상치(outlier)를 발견하는 데 유용합니다.
현대 데이터 분석: 오늘날 데이터 분석은 EDA와 확증적 분석의 요소를 함께 활용하여 데이터 기반 의사결정에 적용됩니다. 특히, 머신 러닝 및 데이터 과학에서 데이터의 잠재력을 극대화하기 위해 EDA의 원칙을 적극 활용하고 있습니다.
EDA의 역사는 통계학의 변화를 보여주는 대표적인 사례로, 분석 과정에서 데이터 탐색과 시각화의 중요성을 부각시켰습니다. EDA는 데이터를 이해하고 효과적인 예측 모델을 구축하는 데 있어 핵심적인 단계로 여겨집니다.
2데이터¶
기계학습은 데이터로부터 출발합니다. 해결하고자 하는 문제가 데이터로 표현되어 있고, 데이터가 해답의 규칙을 내재하고 있다고 가정합니다. 기계학습 패키지 싸이킷런은 잘 알려진 예시 데이터 집합을 읽어올 수 있는 API가 있습니다. 예시 데이터 집합 중, 간단한 것을 먼저 살펴보겠습니다. 이 데이터셋은 통계와 기계학습의 “헬로 월드” 정도로 여겨지는 것으로, 1930년대 통계학자 피셔(Fisher, R.A.) 가 작성한 것입니다.
from sklearn.datasets import load_iris
iris = load_iris()load_iris API로 읽어온 결과, 싸이킷런의 유틸리티 자료구조 Bunch 객체로 데이터셋이 표현됩니다. Bunch는 우리말로 ‘뭉치’ 또는 ‘뭉텅이’ 쯤입니다. 데이터의 여러 정보를 한데 묶어 놓은 것이라고 할 수 있습니다.
Bunch는 파이썬의 기본 자료구조인 사전에 가깝습니다. 그래서 사전 구조와 같이 각 항목은 색인이 부여된 값으로 구성됩니다. 사전과 같은 방식으로 항목을 읽어올 수 있습니다.
type(iris)sklearn.utils._bunch.Bunch데이터셋에서 가장 중요한 정보는 data와 target 색인에 반영되어 있습니다.
iris.keys()dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])각 항목에 접근할 때, 사전과 같이 선택 연산자를 활용할 수 있습니다. 그런데 선택 연산자 활용 시, 색인이 문자열인 경우 작성이 번거로울 수 있습니다. 그래서 Bunch에서는 점 연산자로 각 항목을 접근할 수 있도록 하였습니다.
print(iris['data'] is iris.data)
print(iris['target'] is iris.target)True
True
3numpy¶
data와 target은 numpy 자료구조 ndarray로 되어 있습니다. ndarray는 텐서를 효과적으로 표현하는 자료구조로 데이터 과학에서 널리 활용됩니다(자료구조 자체는 numpy 장에서 다룹니다). 여기서는 적재한 붓꽃 데이터가 어떤 형태인지 살펴보겠습니다.
print(type(iris.data))
print(type(iris.target))<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
(0:12) ndarray의 shape과 dtype 속성으로 텐서의 형상과 원소 자료형을 살펴볼 수 있습니다.
print(f'형상: {iris.data.shape}\t 자료형: {iris.data.dtype}')
print(f'형상: {iris.target.shape}\t 자료형: {iris.target.dtype}')형상: (150, 4) 자료형: float64
형상: (150,) 자료형: int64
(0:20) data와 target의 처음 몇 개를 살펴보면서, 어떤 값들이 담겨있는지 확인해 보겠습니다. 모두 수치로 기록된 자료들입니다. iris는 여러 붓꽃의 특징을 수치로 표현한 데이터 집합입니다. 붓꽃은 유형이 있고, 유형은 target에 수치 형식으로 기록되어 있습니다. 어떤 유형들이 있는지를 확인하려면, numpy.unique로 집합을 구해서 볼 수 있습니다. 각 유형의 명칭은 target_names 속성에 기록되어 있습니다.
iris.data[:5]array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])iris.target[:5]array([0, 0, 0, 0, 0])np.unique(iris.target)array([0, 1, 2])iris.target_namesarray(['setosa', 'versicolor', 'virginica'], dtype='<U10')4pandas¶
data는 2차원 텐서라 표 형식으로 표현이 가능합니다. 표 형식으로 표현할 때는, pandas 패키지의 DataFrame 자료구조가 좋습니다. feature_names 속성 값을 표의 열 제목으로 설정하면 각 항목의 의미를 살펴보기 편리합니다. 각 붓꽃의 데이터에 대해 명칭이 대응하기 때문에 target 값을 열로 표에 추가하여 하나의 표로 만들 수 있습니다. target 값이 0, 1, 2와 같은 수치형으로 되어 있기 때문에 이것을 각각 실제 명칭으로 변환하는 것이 보기 편리합니다.
표를 만들고 행·열을 선택하는 다양한 방법은 pandas 장에서 자세히 다룹니다. 여기서는 붓꽃 데이터를 표로 구성해 살펴봅니다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
print('labels:', ', '.join(
f'{label} ({정수색인})' for label, 정수색인 in
zip(iris.target_names, np.unique(iris.target))))
iris.frame = pd.DataFrame(iris.data, columns=iris.feature_names)
iris.frame['class'] = pd.Series(iris.target).replace([0, 1, 2], iris.target_names)
iris.frame.rename(columns={
'sepal length (cm)': '꽃받침 길이 (cm)',
'sepal width (cm)': '꽃받침 너비 (cm)',
'petal length (cm)': '꽃잎 길이 (cm)',
'petal width (cm)': '꽃잎 너비 (cm)',
'class': '품종'
}).sample(6, random_state=7).sort_values('품종')labels: setosa (0), versicolor (1), virginica (2)
(0:36) 데이터셋을 읽어올 때 싸이킷런의 API로 읽어왔는데, 실제로는 파일 형식이나 데이터베이스 등에서 읽어와야 합니다. 현재 데이터프레임 형식으로 표현된 붓꽃 데이터 집합을 파일 형식으로 저장하겠습니다.
붓꽃표.to_csv('../data/iris.csv', index=False, encoding='utf8')(0:52) 저장된 파일을 열어보면, 각 항목이 쉼표로 구분된 값으로 기록된 것을 확인할 수 있습니다. 이런 형식을 보통 csv 형식이라고 합니다. 싸이킷런의 예시 데이터 집합이 아니라면, 원래는 이런 형태의 파일 등에서 데이터 집합을 읽어와야 합니다. 그런 경우, pandas read_csv API를 활용하면 텍스트 파일로 기록된 표 형식의 데이터를 편리하게 읽어올 수 있습니다. pandas는 텍스트, 엑셀 파일을 비롯해 SQL을 활용하는 데이터베이스 등에서 편리하게 표 형식의 자료를 읽어올 수 있는 다양한 API를 제공합니다.
iris = pd.read_csv('../data/iris.csv')
iris[:5](1:32) 기계학습의 데이터들은 많은 경우 표 형식으로 기록되어 있습니다. 그런 경우, pandas를 사용해 데이터를 읽어오는 것이 데이터 적재의 시작입니다. 이 점은 우리가 처음 데이터를 적재할 때와 조금 다릅니다. 우리는 처음에 붓꽃 데이터를 싸이킷런의 API로 읽어왔기 때문입니다. 싸이킷런에서 준비해 주었기 때문에 편리하게 읽어왔지만, 실제 데이터를 읽어오는 경우에 보다 가까운 방식으로 살펴보기 위해 pandas DataFrame으로 데이터를 표 형식으로 재현한 상태를 가정하여 살펴보겠습니다.
(2:11) ‘유형’ 열을 선택하여, 도수 집계 결과를 살펴보겠습니다. 세 가지 유형이 각각 50개 씩임을 확인할 수 있습니다.
iris['유형'].value_counts()setosa 50
versicolor 50
virginica 50
Name: 유형, dtype: int64iris[:5]5특징 벡터와 디자인 행렬¶
(0:00) 이제 붓꽃 데이터셋이 어떻게 측정되어 무엇을 표현하고자 했는지를 살펴보겠습니다. 1936년 농경학자이자 통계학자 피셔는 여러 붓꽃 유형 표본에서, 꽃잎과 꽃받침의 높이와 너비를 측정하여 기록했습니다. 무엇을 어떻게 왜 측정해야 하는지는 해당 분야의 전문가가 결정합니다. 만약 이것이 어떤 질병과 관계된 데이터라면 해당 질병의 전문가인 의사가 어떤 특징을 어떤 방식으로 수집해야 하는지 정하겠죠. 또한, 전문가들마다 의견이 다를 수도 있습니다. 그래서 어떤 데이터의 측정과 수집 방식이 절대적인 것은 아닙니다. 현재의 붓꽃 데이터는 피셔의 관점을 반영한 것입니다.
(0:47) 각각의 붓꽃은 표본입니다. 각 표본은 데이터이고, 그러한 데이터의 집합이기 때문에 이것을 데이터셋(Dataset)이라고 합니다. 표본의 여러 특징을 수치로 기록하면, 각 표본은 1차원 텐서 또는 벡터 형식으로 표현되었다고 할 수 있습니다. 그래서 각 데이터는 ‘특징 벡터’라고 합니다. 이러한 특징 벡터가 여러 표본에 대해 모여 있으면 2차원의 행렬 형식이 됩니다. 특징 벡터가 모여 구성된 행렬은 ‘디자인 행렬 ’이라고 합니다.
(1:23) 기계학습의 많은 알고리즘들은 디자인 행렬 형식을 입력으로 가정합니다. 붓꽃 데이터의 특징 벡터 집합이 입력이라면, 이에 대해 그러한 특징이 어떤 유형인지를 판별하는 문제를 가정할 수 있습니다. 그래서 붓꽃의 유형 정보는 기계학습 알고리즘이 목표로 하는 출력입니다. 그런 이유로, target이라고 부르기도 합니다. target은 예측의 목표, 곧 정답이라고 할 수 있습니다.
(1:54) 각 표본의 특징 벡터를 , 그것의 집합인 디자인 행렬은 라고 한다면, 임의의 알고리즘을 함수 라고 했을 때, 정답은 함수의 출력 라고 표기할 수 있습니다.
y = iris['유형']
X = iris.drop(columns='유형')
X.shape, y.shape((150, 4), (150,))(2:08) 데이터를 읽어왔을 때, 디자인 행렬에 해당하는 정보와 목표 값이 하나의 표 형식으로 작성된 경우, 이것을 나누어서 별도의 변수에 저장하는 것이 좋습니다. 각각을 X와 y라고 하겠습니다.
(2:25) 대체로, 데이터 적재와 탐색적 분석 및 그 이후 필요한 가공은 pandas 쪽에서 수행하고, 연산적인 측면은 numpy 자료구조 상태로 하는 것이 바람직합니다. 많은 기계학습 프레임워크에서는 데이터의 자료구조를 numpy.ndarray로 가정합니다.
(2:45) pandas 시리즈와 데이터프레임은 to_numpy API로 값을 ndarray로 변환할 수 있습니다. numpy와 pandas는 서로 유사한 구조이고, pandas는 numpy를 기반으로 하기 때문에 변환은 대체로 수월한 편입니다. ndarray로 만드는 것은 데이터에 대한 전처리 작업이 끝나고 난 다음 하는 것이 작업의 흐름상 대체로 편리합니다.
y.to_numpy()[:5]array(['setosa', 'setosa', 'setosa', 'setosa', 'setosa'], dtype=object)X.to_numpy()[:5]array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])6탐색적 데이터 분석¶
(0:00) 데이터를 적재한 다음, 데이터를 이모저모 살펴보는 과정이 필요하고 중요합니다. 이러한 작업은 탐색적 데이터 분석이라고 하며, Exploratory Data Analysis, 줄여서 EDA라고 종종 부릅니다.
(0:16) 데이터를 살펴보는 과정은 여러 가지 방식이 있습니다. 붓꽃 데이터 집합의 경우, 유형 집합의 통계적 분포를 살펴보는 것이 가장 기본적인 작업입니다.
y.value_counts()setosa 50
versicolor 50
virginica 50
Name: 유형, dtype: int64(0:28) 각 표본이 눈으로 살펴볼 수 있는 이미지 데이터가 아닌 경우, 전반적인 분포를 살펴보는 적절한 방식을 고려해야 합니다. 왜냐하면, 데이터 수집은 사람의 실수, 또는 수집 소프트웨어나 센서 오류 등으로 잘못된 데이터가 있을 수 있기 때문입니다. 예를 들어, 붓꽃의 높이와 너비를 기록하는 경우, 높이와 너비의 위치를 바꿔서 기입하거나, 높이 또는 너비만 두 번 기록하거나, 센티미터로 측정하다가 작업자가 바뀌어 인치 단위로 기록할 수도 있기 때문입니다. 실제 이런 일이 드물지 않게 발생합니다. 그래서 데이터를 전반적으로 살펴보면서 확인하는 것은 중요한 일입니다.
(1:11) 데이터 특징별 기본적인 통계를 살펴보는 것은 좋은 출발점이 될 수 있습니다. pandas.DataFrame.describe로 각 열별 평균, 편차, 최대, 최소, 백분위수 값을 한 눈에 확인할 수 있습니다.
X.describe()6.1시각화¶
6.1.1상자 그림 (Box plot)¶
(0:00) 통계 수치를 그래프로 표현하면, 직관과 통찰을 얻는데 도움이 됩니다. 데이터의 통계적 분포를 한눈에 살펴볼 때는 상자 그림(box plot) 형태가 좋습니다. 개별 열 값들의 범위가 상자로 표시됩니다.
(0:15) 상자의 위 아래는 각각 백분위수 75%와 25%, 즉 사분범위(Interquantile range; IQR)를 의미하고, 상자 안의 선은 백분위수 50인 중앙값을 표시합니다. 상자 밖 아래위로 뻗은 선은 각각 최대 최소 값입니다. 또한, 통계적 범위 상 이상치(outlier)는 개별 점으로 표시됩니다.
X.plot(kind='box')<AxesSubplot:>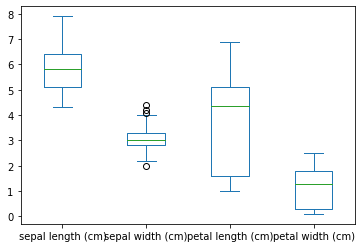
(0:35) 붓꽃 데이터에서, 꽃받침 길이 값의 분포 범위가 넓은 것을 확인할 수 있습니다. 또한 중앙값이 위쪽으로 치우쳐져 있기 때문에 중앙값 이하 값들의 범위가 넓다는 점도 살펴볼 수 있습니다. 비교해서, 꽃잎의 너비는 사분범위가 상대적으로 좁고, 중앙값이 상자의 중심 정도에 위치하기 때문에 대체로 분포가 고른 편입니다.
(1:01) 꽃잎의 너비는 사분범위가 매우 좁은데, 이런 범위의 형태를 벗어나는 이상치들이 점으로 표시됩니다. 이상치들은 통상적으로 사분범위의 하한과 상한에서 사분범위 구간 크기의 1.5배 이상 떨어진 데이터들입니다. 꽃잎 너비의 사분범위가 좁기 때문에, 다른 특성에 비해 여러 값들이 이상치로 간주됩니다.
(1:26) 꽃잎 너비의 각 백분위수를 다음과 같이 구할 수 있습니다. 이를 바탕으로, 이상치의 상한과 하한 경계값도 직접 구할 수 있습니다.
꽃잎너비 = X['sepal width (cm)']
Q3 = 사분상한 = 꽃잎너비.quantile(0.75)
Q1 = 사분하한 = 꽃잎너비.quantile(0.25)
IRQ = 사분범위크기 = Q3 - Q1
이상치_상한 = Q3 + 1.5 * IRQ
이상치_하한 = Q1 - 1.5 * IRQ
print(이상치_하한, '<= "정상" <=', 이상치_상한)2.05 <= "정상" <= 4.05
(1:37) 이상치 상한 경계를 넘는 표본들을 직접 살펴보려면 다음과 같이 선택할 수 있습니다.
꽃잎너비[꽃잎너비 > 이상치_상한]15 4.4
32 4.1
33 4.2
Name: sepal width (cm), dtype: float64(1:44) 마찬가지로, 이상치 하한 아래의 표본 선택은 다음과 같이 합니다.
꽃잎너비[꽃잎너비 < 이상치_하한]60 2.0
Name: sepal width (cm), dtype: float64(1:50) 이상치는 그야말로 정상적인 범위를 벗어난 것으로 간주하기 때문에, 이것을 통계에 포함시키면 전체적으로 왜곡이 심해질 수 있습니다. 상자 그림의 최대 최소값은 이러한 이상치를 제외한 값들을 기준으로 합니다.
정상꽃잎너비 = 꽃잎너비[np.logical_and(꽃잎너비 <= 이상치_상한, 꽃잎너비 >= 이상치_하한)]
print(꽃잎너비.min(), ' < ', 이상치_하한, ' < [', 정상꽃잎너비.min(), ' < ', 정상꽃잎너비.max(), '] < ', 이상치_상한, ' < ', 꽃잎너비.max())2.0 < 2.05 < [ 2.2 < 4.0 ] < 4.05 < 4.4
(2:06) 상자 그림의 이상치에 해당하는 표본을 사용할지 여부는 판단이 필요합니다. 혹시 기록이 잘못되었는지 등을 확인하는 근거로 활용하는 것이 적절합니다. 하지만 상자 그림의 이상치라고 해서 무조건 잘못된 것이라고 간주할 수는 없습니다. 다른 문제가 없다면, 이러한 값은 실제로 발생할 수 있는 것들이기 때문에 현재로서는 해당 특성의 사분범위가 좁아서 생기는 문제입니다. 문제없이 기록된 값이라고 확인된 경우, 이상치가 여러 개 발생한다는 것은 수집된 데이터의 규모가 너무 작다는 것을 시사할 수 있습니다. 실제로 붓꽃 데이터셋은 150개의 표본으로 구성된 아주 작은 규모입니다. 150개의 붓꽃이 세상의 모든 붓꽃을 대표한다고 간주하기는 어렵습니다. 피셔의 뒷마당 정원 정도를 대표하겠죠.
6.1.2산점도¶
(0:00) 특징 벡터 자체를 표본 공간(sample space)에서 표현하는 것도 좋은 방법이 될 수 있습니다. 특징 벡터는 1차원 텐서이지만, 이것을 표현하는 표본 공간은 벡터의 원소 개수만큼의 차원이 필요합니다. 예를 들어, 두 개의 특징으로 되어 있다면 2차원 평면에서 표현이 가능합니다. 특징이 3개라면 3차원, n개 수집했다면 n차원 공간에서 표현할 수 있습니다. 그래서 특징의 개수는 종종 차원이라고 표현할 수 있습니다. 즉, 2개의 특징이라고 하거나, 2차원 데이터라고 하는 것은 같은 표현입니다.
(0:37) 붓꽃 데이터의 특징 벡터는 4차원 표본 공간에서 표현할 수 있습니다. 4차원의 시각화는 비디오 영상과 같이 시간의 흐름이 네 번째 차원이 아닌 이상 시각화가 어렵거나 불가능합니다. 대체로 3차원 정도까지 2차원 평면에서 정적으로 표현할 수 있습니다. 기계학습이 상대하는 데이터들의 경우 대체로 4차원 이상이며, 수백 만 차원 이상인 경우도 있습니다. 그래서 어떤 표본들의 분포를 시각적으로 표현하는 것은 매우 제한적입니다.
(1:12) 그런데 붓꽃 데이터는 원칙적으로는 어렵지만 상대적으로 저차원 데이터라 제한적이지만 분포를 시각적으로 표현하는 것이 가능합니다. 네 가지 특징 중 두 가지를 임의로 선택하면, 전체의 50% 특성을 선택한 것이기 때문에 완벽할 수는 없지만 어느 정도는 대표성이 있는 시각적 표현이 가능합니다. 가능한 분별력을 높이는 방향으로 선택하려면, 분포가 강한 특성들을 선택하는 것이 좋습니다. 이전의 통계적 분포 확인 과정에서, 상자 그림을 통해 꽃잎과 꽃받침의 길이의 분포가 넓게 나타났습니다. 그래서 이 두 개의 특성을 선택해 산점도 그래프를 그려보겠습니다.
특성목록 = X.columns
유형별_색상 = y.replace(np.unique(y), ['red', 'green', 'blue'])
plt.scatter(X[특성목록[0]], X[특성목록[2]], c=유형별_색상)
# 유형 경계
plt.hlines(2.5, xmin=4, xmax=8, colors='magenta', linestyle='--')
plt.hlines(5.0, xmin=4, xmax=8, colors='cyan', linestyle='--')<matplotlib.collections.LineCollection at 0x178dc4190>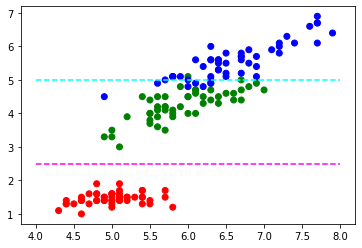
(1:58) 붓꽃 데이터의 특성 명칭이 길고 번잡하기 때문에, 특성목록을 획득한 다음, 특성목록의 위치 색인을 활용하면 특성 명칭을 문자열로 정확하게 입력해야 하는 부담을 덜 수 있습니다.
(2:11) 2차원 산포도 그래프는 x, y 값을 평면에 점으로 표현합니다. 그래서 각 표본의 특성 두 개를 각각 그래프의 x, y 값으로 설정하여 산점도 그래프를 그렸습니다. 이 때, 각 점은 2차원 벡터의 위치라고 할 수 있습니다. 산점도의 각 벡터는 유형을 식별할 수 있도록 색상을 할당하여, 산점도 그래프를 그릴 때 활용하도록 했습니다. 출력된 그래프에서는 유형별 표본 분포를 한 눈에 살펴볼 수 있습니다. 색상으로 구분된 유형들이 대체로 서로 모여 있어 유형별로 상당한 경향성이 있음을 확인할 수 있습니다. 특히 붉은색으로 표현된 setosa의 경우, 나머지 다른 두 가지 유형과 확연하게 다른 분포 경향을 보입니다. 전체적으로 x, y값이 나머지 다른 두 가지 값에 비해서 상당히 작고, 특히 y축으로 표현된 꽃받침 길이가 모든 표본에서 2 센티미터보다 작습니다. 대체로, y축인 꽃받침의 길이로 세 가지 유형을 대략적으로 구분하는 것이 가능해 보입니다.
(3:22) 이러한 표현은 거울에 비친 모습 같은 온전한 표현은 아니지만, 어떤 물체의 그림자가 사물을 식별하는데 어느 정도 도움이 되는 것에 비유할 수 있습니다. 실제 사물은 3차원 이상인데, 그림자는 그것의 윤곽선을 2차원 평면에 투영한 것이라고 할 수 있으니 고차원의 일부만을 선별한 표현이라고 할 수 있습니다. 이러한 표현이 적절한지 여부는 데이터의 원래 차원수와 분포, 그리고 응용 목표에 달려 있습니다.
(3:55) 붓꽃 데이터에 대해 시각화를 비롯한 여러 가지 기법을 적용해 데이터의 잠재적인 문제를 확인하고, 분포의 양상을 살펴본 결과 간단한 분류 알고리즘으로도 손쉽게 분리가 될 것 같다는 통찰을 얻을 수 있습니다.
6.1.2.1산점도 행렬¶
(4:11) 우리가 붓꽃 데이터에서 선택한 두 개의 특성은 통계적 분포를 기반으로 한 것이지만, 4차원의 원래 분포를 완벽하게 반영할 수는 없습니다. 4차원 그래프를 2차원 평면에 그리는 것은 여전히 어렵거나 불가능하지만, 서로 다른 특성 조합에 대해 산점도를 그려보면 좀더 종합적인 통찰을 얻는데 도움일 될 수 있습니다. 특성을 두 개씩 선택하는 방식으로 모든 조합에 대해 그래프를 그리는 것을 산점도 행렬 그래프라고 합니다.
유형별_색상 = y.replace(np.unique(y), ['red', 'green', 'blue'])
_ = pd.plotting.scatter_matrix(
X, c=유형별_색상, figsize=(15, 15), s=60, alpha=0.8)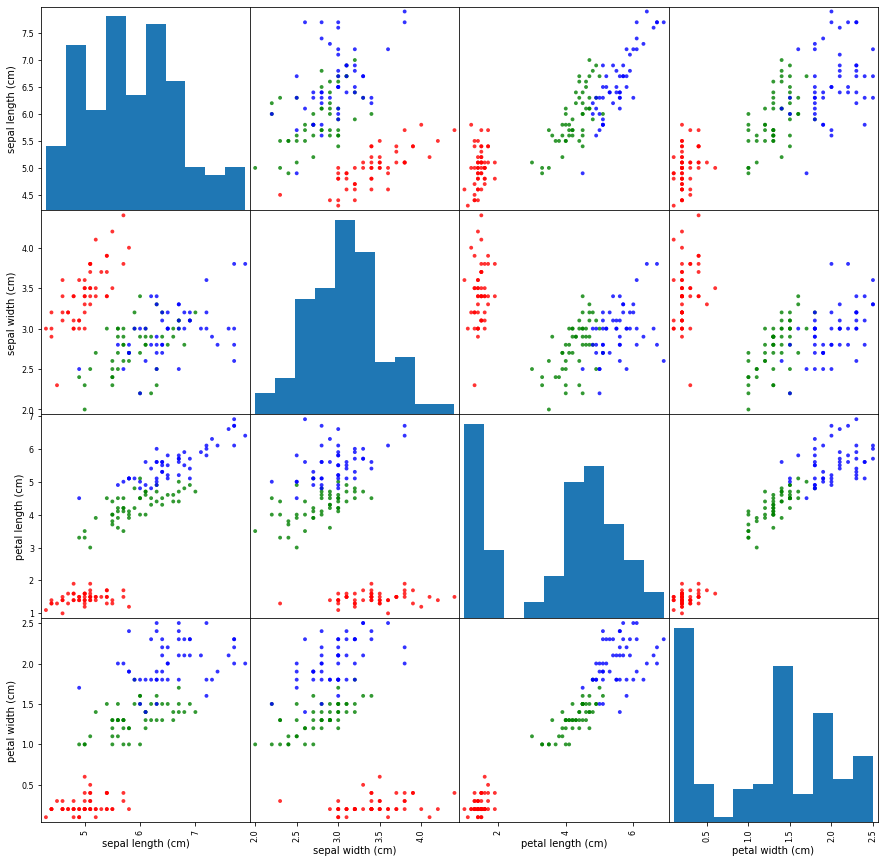
(4:44) pandas scatter_matrix API는 주어진 데이터프레임에 대해 산점도 행렬을 그려줍니다. 모든 열에 대해 한 번에 두 개씩을 선택하여 각각을 산점도의 x, y 축으로 하여 그래프를 생성합니다. 두 가지 조합 선택 시, 각 특성 자체가 두 번 선택될 수 있습니다. 이런 경우, 히스토그램 그래프가 그려집니다. 히스토그램 그래프는 특정한 값의 분포 양상을 살펴보는데 도움이 됩니다.
(5:16) 더불어 시각적인 스타일을 추가로 설정할 수 있습니다. 유형별 색상은 이전과 마찬가지로 마커의 컬러를 설정하는 c 인자로 설정합니다. figsize는 그림 크기, s는 점 크기, alpha는 투명도를 의미합니다. pandas의 그래프는 내부적으로 matplotlib 패키지를 활용합니다. 그래서 pandas API로 그래프를 생성할 때는 해당 그래프 API의 설정에 대해 상세하게 알아보기 위해 두 가지 문서를 동시에 참조해야 할 수 있습니다. 왜냐하면, pandas API 자체적으로 설정하는 인자도 있고, 스타일의 경우는 matplotlib의 해당 API 인자를 그대로 전달하는 경우가 있기 때문입니다.