넘파이(NumPy)는 Numerical Python 을 줄인 이름으로, 수치 연산을 위한 라이브러리입니다. 파이썬 기반 데이터 과학에서 널리 쓰이며, 기계학습의 근간이 되는 라이브러리입니다.
데이터 과학은 주로 숫자를 다룹니다. 숫자로 표현된 데이터는 수학적으로 텐서(tensor) 라고 합니다. 단일 값은 스칼라, 1차원은 벡터, 2차원은 행렬이라 하고, 3차원 이상은 3차원 텐서·4차원 텐서처럼 부릅니다. 넘파이는 이러한 다차원 텐서를 효과적으로 다루는 자료구조 ndarray(다차원 배열)를 제공합니다.
파이썬의 기본 자료구조인 리스트는 어떤 객체든 원소가 될 수 있어 유연하지만, 숫자 텐서를 표현하기에는 적합하지 않습니다. 원소가 숫자라는 보장이 없어 산술 연산을 가정하기 어렵기 때문입니다. 반면 ndarray는 원소의 자료형이 하나로 통일되어 있어(dtype 속성으로 확인), 이를 기반으로 다차원 텐서의 산술 연산을 원소별로 지원합니다. 텐서의 형상은 shape, 차원 수는 ndim 속성으로 확인합니다.
data = [[1,2,3], [4,5,6], [7,8,9]]data * 2[[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9]]산술연산 수행을 위해서는 제어 구문이 필요하다.
data2 = []
for row in data:
data2.append([n*2 for n in row])
data2[[2, 4, 6], [8, 10, 12], [14, 16, 18]]행 선택은 쉽지만, 열 선택은 어렵다.
data2[0][2, 4, 6]data2[0][0], data2[1][0], data2[2][0](2, 8, 14)import arrayx = array.array('d', [1, 2, 3])x.append(4.5)xarray('d', [1.0, 2.0, 3.0, 4.5])try:
x.append('오')
except TypeError as e:
print('TypeError:', e)TypeError: must be real number, not str
try:
x - x
except TypeError as e:
print('TypeError:', e)TypeError: unsupported operand type(s) for -: 'array.array' and 'array.array'
import numpy as nparr2d = np.array(data)type(arr2d)numpy.ndarrayarr2darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])데이터의 자료형
arr2d.dtypedtype('int64')NumPy 배열은 한 가지 자료형의 데이터만 저장할 수 있다.
np.array([1, '2', 3.14])array(['1', '2', '3.14'], dtype='<U32')파이썬의 표준 자료구조보다 훨씬 빠르게 연산을 수행한다.
arr = np.arange(1e7)
nums = arr.tolist()%timeit [n*1.1 for n in nums]398 ms ± 19.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit arr * 1.110.4 ms ± 76.3 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
1산술연산¶
원소의 자료형이 통일되어 있으므로, ndarray의 산술 연산은 기본적으로 원소별(element-wise) 로 수행됩니다. 같은 형상의 두 텐서를 더하거나 곱하면 같은 위치의 원소끼리 연산됩니다. 리스트와 달리 반복문 없이 텐서 전체에 대한 연산을 간결하게 표현할 수 있습니다.
연산되는 두 텐서의 형상이 서로 달라도 연산이 가능한 경우가 있습니다. 낮은 차원의 텐서가 높은 차원 텐서의 형상에 맞춰진 뒤 원소별 연산이 수행되는데, 이때 값이 필요한 만큼 복사되는 과정을 전파(broadcast) 라고 합니다. 전파는 연산을 위해 내부적으로 자동으로 일어나므로 보통은 직접 조작할 필요가 없습니다.
산술연산이 기본적으로 원소별로 수행된다.
arr2d * 2array([[ 2, 4, 6],
[ 8, 10, 12],
[14, 16, 18]])arr2d - arr2darray([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])2색인과 슬라이스¶
ndarray는 다차원 색인 시스템으로 원소를 선택합니다. 각 차원은 축(axis)으로 표현되어, 벡터는 한 개의 축, 행렬은 두 개의 직교하는 축을 가집니다. 대괄호 선택 연산자 안에서 각 축의 선택 조건을 쉼표로 구분해 나열합니다.
정수 색인은 파이썬 리스트처럼 0부터 시작해 하나씩 증가합니다. 다만 리스트는 중첩으로 다차원을 흉내 낼 뿐 자체적인 다차원 색인을 지원하지 않는 반면, ndarray는 각 축을 따라 색인이 부여되어 다차원 원소를 편리하게 선택할 수 있습니다. 슬라이스는 연속적인 범위를 선택할 때 사용합니다.
행열 단위 접근이 가능하다.
arr2d[0]array([1, 2, 3])arr2d[:, 0]array([1, 4, 7])arr2d[0:2]array([[1, 2, 3],
[4, 5, 6]])arr2d[:, 0:2]array([[1, 2],
[4, 5],
[7, 8]])arr2d[1:, 1:]array([[5, 6],
[8, 9]])3팬시 색인¶
팬시 색인(fancy indexing) 은 여러 개의 색인을 직접 지정해 선택하는 방법입니다. 슬라이스가 연속적인 범위를 선택하는 데 비해, 팬시 색인은 연속적이지 않은 색인들도 원하는 순서로 선택할 수 있습니다. 선택하려는 축에 대해 대상 색인 번호를 나열하면 됩니다.
data[[1, 2, 3], [4, 5, 6], [7, 8, 9]]data[0], data[2]([1, 2, 3], [7, 8, 9])arr2d[[0, 2]]array([[1, 2, 3],
[7, 8, 9]])arr2d[[2, 0]]array([[7, 8, 9],
[1, 2, 3]])arr2d[[-1, -2]]array([[7, 8, 9],
[4, 5, 6]])arr2d[:, [0,2]]array([[1, 3],
[4, 6],
[7, 9]])arr2d[:, [2, 0]]array([[3, 1],
[6, 4],
[9, 7]])4불리언 색인¶
원소가 참/거짓 값으로 된 ndarray를 부울 텐서라 합니다. 어떤 텐서와 같은 형상의 부울 텐서를 선택 연산자에 제공하면, 참인 위치의 원소만 선택됩니다. 이로써 조건에 따라 값을 선택할 수 있습니다.
부울 텐서는 주로 비교 연산으로 만듭니다. 산술 연산이 원소별로 수행되듯 비교 연산도 원소별로 실행되어, 같은 형상의 부울 텐서가 생성됩니다. 부울 색인이 없다면 반복문과 조건문으로 원소를 골라야 하지만, 부울 색인을 쓰면 이를 간결하게 대신할 수 있습니다. 2차원 이상 텐서에 부울 색인을 적용하면, 선택 결과는 원래 차원과 무관하게 1차원 벡터로 반환됩니다.
arr = np.array([0, 1, 2, 3, -4, -5])arr[[True, True, True, False, False, False]]array([0, 1, 2])arr > 0array([False, True, True, True, False, False])arr[arr > 0]array([1, 2, 3])원소별 논리연산
~(arr > 0)array([ True, False, False, False, True, True])(arr > 0) & (arr < 3)array([False, True, True, False, False, False])(arr < 0) | (arr > 1)array([False, False, True, True, True, True])5배열 전치¶
전치(transpose) 는 텐서의 축을 뒤바꾸는 연산입니다. 행렬에서는 행과 열이 서로 바뀌어, 형상 인 행렬이 이 됩니다. T 속성으로 간단히 전치를 얻을 수 있으며, 선형대수 연산에서 자주 사용됩니다.
arr2darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])arr2d.Tarray([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])6유니버설 함수¶
유니버설 함수(universal function, ufunc) 는 텐서의 각 원소에 일괄 적용되는 함수입니다. 예를 들어 제곱근이나 지수 함수를 텐서에 적용하면 모든 원소에 대해 한 번에 계산됩니다. 반복문 없이 원소별 변환을 표현할 수 있어 간결하고 빠릅니다.
data = list(range(1, 11))data[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]from math import sqrt[sqrt(n) for n in data][1.0,
1.4142135623730951,
1.7320508075688772,
2.0,
2.23606797749979,
2.449489742783178,
2.6457513110645907,
2.8284271247461903,
3.0,
3.1622776601683795]arr = np.array(data)np.sqrt(arr)array([1. , 1.41421356, 1.73205081, 2. , 2.23606798,
2.44948974, 2.64575131, 2.82842712, 3. , 3.16227766])이항 유니버설 함수
x = np.array([0, 1])x[::-1]array([1, 0])np.maximum(x, x[::-1])array([1, 1])7벡터 단위 연산¶
텐서 전체나 특정 축을 대상으로 값을 집계하는 연산입니다. 합계·평균 같은 연산을 텐서 전체에 적용하거나, axis 인자로 특정 축을 따라 수행할 수 있습니다. 축을 지정하면 해당 축이 집계되어 차원이 줄어듭니다.
data = [[1, -1], [-2, 2]]data2 = []
for row in data:
new_row = []
for n in row:
n2 = n if n > 0 else 0
new_row.append(n2)
data2.append(new_row)
data2[[1, 0], [0, 2]]arr = np.array(data)np.where(arr > 0, arr, 0)array([[1, 0],
[0, 2]])7.1산술통계¶
sum, mean, std, min, max 등으로 텐서의 기초 통계량을 구합니다. axis 인자로 집계 방향을 지정하며, 지정하지 않으면 전체 원소에 대해 계산합니다.
arr = np.random.randn(3,2)arrarray([[ 8.62888346e-01, 9.04353629e-04],
[ 8.00054408e-01, -1.14113726e+00],
[ 1.47138149e+00, 1.03833135e+00]])arr.mean()np.float64(0.5054037813635247)np.mean(arr)np.float64(0.5054037813635247)arr.sum()np.float64(3.032422688181148)arr.sum(axis=0)array([ 3.13432425, -0.10190156])arr.sum(axis=1)array([ 0.8637927 , -0.34108285, 2.50971284])7.2집합 함수¶
unique 로 중복을 제거한 고유값을 구하는 등, 집합 연산을 텐서에 적용합니다. 데이터에 어떤 값들이 들어 있는지 파악하거나 범주를 확인할 때 유용합니다.
arr = np.array([0, 1, 2, 3] * 2)arrarray([0, 1, 2, 3, 0, 1, 2, 3])np.unique(arr)array([0, 1, 2, 3])np.in1d(arr, [1, 2])/tmp/ipykernel_23/602466988.py:1: DeprecationWarning: `in1d` is deprecated. Use `np.isin` instead.
np.in1d(arr, [1, 2])
array([False, True, True, False, False, True, True, False])arr[np.in1d(arr, [1,2])]/tmp/ipykernel_23/1558456108.py:1: DeprecationWarning: `in1d` is deprecated. Use `np.isin` instead.
arr[np.in1d(arr, [1,2])]
array([1, 2, 1, 2])x = np.array([0,1,2,3])y = np.array([1,2,3,4])np.intersect1d(x, y)array([1, 2, 3])np.union1d(x, y)array([0, 1, 2, 3, 4])np.setdiff1d(x, y)array([0])np.setxor1d(x, y)array([0, 4])7.3선형대수¶
행렬 곱(@ 또는 dot), 역행렬, 행렬식 등 선형대수 연산을 제공합니다. 기계학습의 많은 알고리즘이 내적과 행렬 연산으로 표현되므로, 선형대수 연산은 넘파이 활용의 핵심입니다.
x = np.array([[1, 1], [2, 2]])xarray([[1, 1],
[2, 2]])y = np.array([[1, -1], [-1, 1]])yarray([[ 1, -1],
[-1, 1]])x*yarray([[ 1, -1],
[-2, 2]])np.dot(x, y)array([[0, 0],
[0, 0]])행렬로 방정식 해 구하기
A = np.array([[3, 6, -5], [1, -3, 2], [5, -1, 4]])
B = np.array([12, -2, 10])np.linalg.inv(A)array([[ 0.15625 , 0.296875, 0.046875],
[-0.09375 , -0.578125, 0.171875],
[-0.21875 , -0.515625, 0.234375]])np.dot(np.linalg.inv(A), B)array([1.75, 1.75, 0.75])8난수 생성¶
np.random 모듈로 난수 텐서를 생성합니다. 정규분포·균등분포 표본을 뽑거나, 배열을 섞고 무작위로 추출할 수 있습니다. 재현 가능한 결과가 필요할 때는 난수 초기값(seed)을 고정합니다.
import randomrandom.randint(0, 10)1np.random.seed(0)np.random.randint(0, 11, size=10)array([5, 0, 3, 3, 7, 9, 3, 5, 2, 4])np.random.randint(0, 11, size=(4,4))array([[ 7, 6, 8, 8],
[10, 1, 6, 7],
[ 7, 8, 1, 5],
[ 9, 8, 9, 4]])%timeit [random.randint(0, 10) for _ in range(10**6)]337 ms ± 11.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit np.random.randint(0, 11, size=10**6)6.91 ms ± 56.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
배열 섞기
x = np.arange(10)xarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])np.random.shuffle(x)xarray([5, 3, 8, 6, 7, 9, 0, 2, 1, 4])np.random.permutation(x)array([7, 4, 2, 8, 9, 5, 3, 0, 1, 6])xarray([5, 3, 8, 6, 7, 9, 0, 2, 1, 4])난수 생성 확률 모델
np.random.rand(5)array([0.86079851, 0.60918413, 0.10944664, 0.27065257, 0.4276277 ])np.random.randn(5)array([0.72036879, 1.54652269, 0.09647718, 0.29276941, 0.90802517])np.random.normal(0, 1, size=5)array([ 1.24693737, -0.64441689, 2.0483664 , 0.53681111, -0.18342861])from scipy.stats import norm, uniform
from pandas import Series%matplotlib inlinex = np.linspace(-3, 3, 100)
Series(norm.pdf(x), x).plot()<Axes: >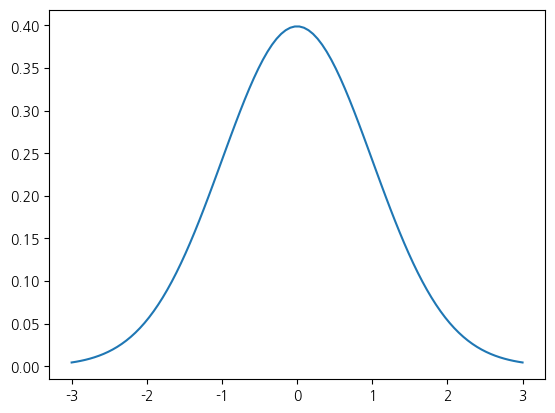
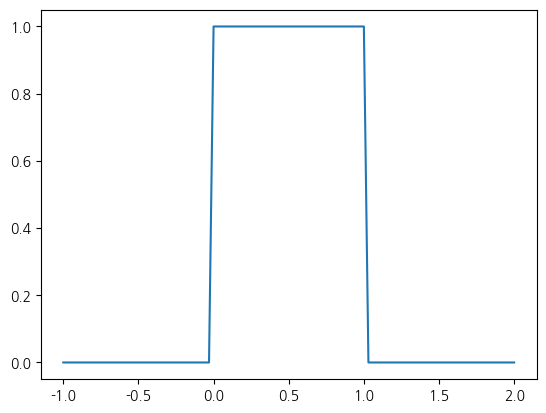
x = np.linspace(-1, 2, 100)
Series(uniform.pdf(x), x).plot()<Axes: >