SciPy는 과학·공학 계산을 위한 라이브러리입니다. 넘파이의 ndarray 위에 구축되어, 최적화·선형대수·적분·보간·신호 처리·통계 등 폭넓은 수치 계산 기능을 제공합니다. 싸이킷런을 비롯한 여러 데이터 과학 도구가 내부 연산에 SciPy를 활용합니다.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline1최적화¶
최적화는 어떤 기준(손실·오차)을 가장 작게 만드는 값을 찾거나, 방정식을 만족하는 해를 구하는 작업입니다. scipy.optimize 모듈은 이런 문제를 푸는 함수들을 제공합니다.
1.1데이터 피팅¶
데이터 피팅(curve fitting) 은 데이터에 어떤 함수 모형을 가장 잘 맞도록 매개변수를 추정하는 것입니다. curve_fit은 모형 함수와 데이터를 받아, 잔차의 제곱합을 최소화하는 매개변수를 돌려줍니다. 아래에서는 잡음이 섞인 데이터에 원래 함수를 다시 맞춰, 추정한 매개변수가 참값에 가까운지 확인합니다.
모델링 함수
def func(x, a, b):
return a*x + bx = np.linspace(0, 10, 100)y = func(x, 1, 2)# 노이즈 추가
yn = y + 0.9 * np.random.randn(len(x))선형회귀 최량적합 방식을 활용한 최적화 수행
from scipy.optimize import curve_fitpopt, pcov = curve_fit(func, x, y)a, b = popta, b(1.0, 2.0)pcovarray([[ 0., -0.],
[-0., 0.]])plt.figure(figsize=(12,10))
plt.scatter(x, yn, marker='o')
plt.plot(x, y, color='black')
subplots = plt.plot(x, func(x, a, b), color='red')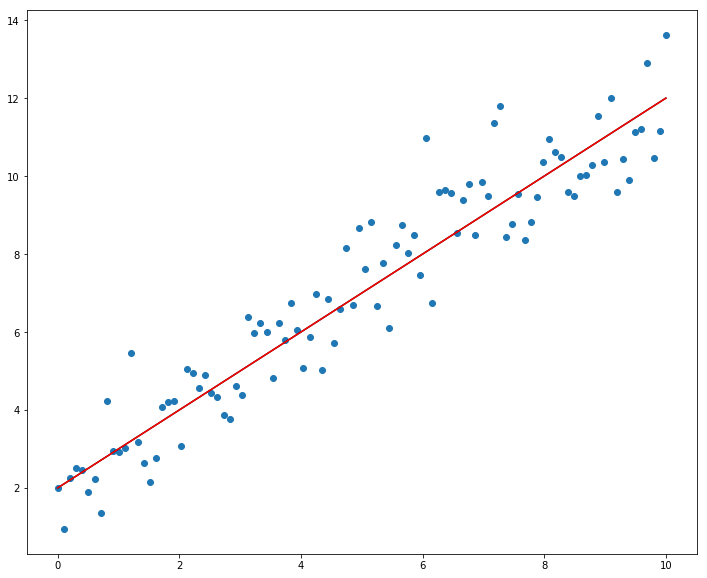
1.2함수 해 구하기¶
방정식 을 만족하는 해를 해석적으로 구하기 어려울 때, 수치적으로 근을 찾을 수 있습니다. fsolve는 함수와 초기 추정값 x0을 받아 근을 반환합니다. 두 함수가 만나는 점(교점)은 두 함수의 차가 0이 되는 해로 구할 수 있습니다.
from scipy.optimize import fsolvef = lambda x: x + 3x0: func(x) = 0 이 되는 x의 추정 시작값
fsolve(f, x0=-2)array([-3.])두 방정식 교차점 찾기
f1 = lambda x: np.cos(x/5) *np.sin(x/2)
f2 = lambda x: 0.01*x + -0.5x = np.linspace(0, 45, 10000)solutions = fsolve(lambda x: f1(x) - f2(x), x0=[15, 20, 30, 35, 40, 45])solutionsarray([ 13.40773078, 18.11366128, 31.78330863, 37.0799992 ,
39.84837786, 43.8258775 ])plt.figure(figsize=(12, 10))
plt.plot(x, f1(x))
plt.plot(x, f2(x))
plt.scatter(solutions, f1(solutions), marker='o', color='red')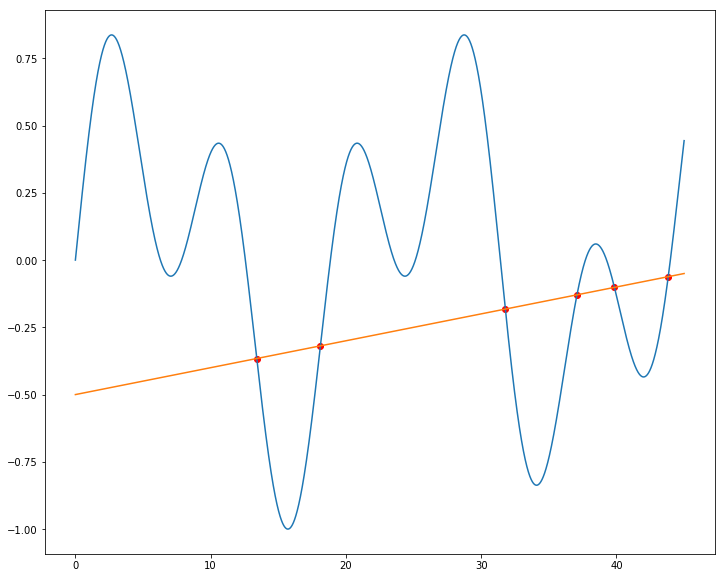
2희소행렬¶
희소행렬(sparse matrix) 은 대부분의 원소가 0인 행렬입니다. 0까지 모두 저장하면 메모리가 낭비되므로, 0이 아닌 값과 그 위치만 저장하는 방식으로 공간을 크게 절약합니다. scipy.sparse의 csr_matrix 등이 이런 표현을 제공합니다. 큰 행렬에서는 저장 공간뿐 아니라 연산 속도에서도 이점이 있어, 희소 전용 연산(eigsh 등)이 조밀 행렬 연산(eigh)보다 훨씬 빠를 수 있습니다.
import scipy.sparseeye = np.eye(4)eyearray([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])sm = scipy.sparse.csr_matrix(eye)print(sm) (0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
난수 희소 행렬 생성
sparse_matrix = scipy.sparse.rand(3000, 3000)type(sparse_matrix)scipy.sparse.coo.coo_matrixsparse_matrix.data.nbytes720000arr = sparse_matrix.toarray()arr.nbytes72000000from scipy.linalg import eigh%timeit eigh(arr)1 loop, best of 3: 3.21 s per loop
from scipy.sparse.linalg import eigsh%timeit eigsh(sparse_matrix)10 loops, best of 3: 59.1 ms per loop