기계학습 알고리즘을 살펴보기 전에, 가장 단순한 접근인 규칙 기반(rule-based) 방법을 먼저 봅니다. 규칙 기반은 사람이 데이터를 관찰해 직접 규칙(if/else)을 작성하는 방식입니다. 데이터로부터 규칙을 스스로 찾는 학습 알고리즘과 대비됩니다.
붓꽃 데이터를 규칙 기반으로 분류해 보겠습니다. 세 품종을 가르는 규칙을 꽃잎 길이 하나로 직접 정해 봅니다.
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
def 붓꽃분류(데이터):
꽃잎길이 = 데이터[:, 2] # 세 번째 특성: 꽃잎 길이
return np.where(꽃잎길이 < 2.5, 0,
np.where(꽃잎길이 < 5.0, 1, 2))
예측 = 붓꽃분류(iris.data)
정확도 = np.mean(예측 == iris.target)
print(f'{np.sum(예측 == iris.target)}/{len(iris.target)} = {정확도:.1%}')142/150 = 94.7%
꽃잎 길이 하나만으로 작성한 간단한 규칙인데도 정확도가 꽤 높습니다. 왜 이 규칙이 통하는지 꽃잎 길이의 분포로 확인해 보겠습니다.
import matplotlib.pyplot as plt
꽃잎길이 = iris.data[:, 2]
for 유형, 색 in zip(np.unique(iris.target), ['red', 'green', 'blue']):
plt.hist(꽃잎길이[iris.target == 유형], bins=20, color=색, alpha=0.6,
label=iris.target_names[유형])
plt.axvline(2.5, color='gray', linestyle='--')
plt.axvline(5.0, color='gray', linestyle='--')
plt.xlabel('꽃잎 길이'); plt.ylabel('빈도'); plt.legend()
plt.show()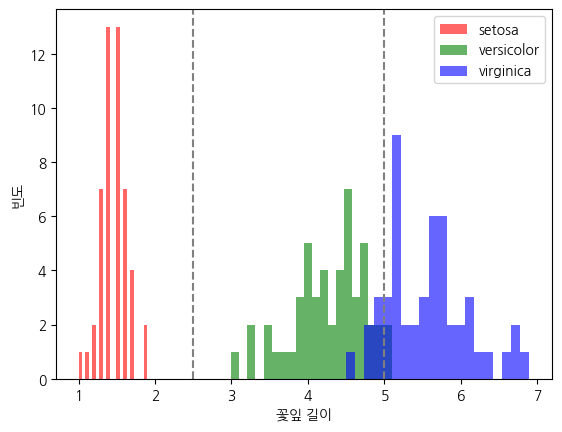
꽃잎 길이만으로도 세 품종이 비교적 잘 나뉩니다. 회색 점선(2.5, 5.0)이 우리가 정한 규칙의 경계입니다. 한 특성으로 이만큼 분리되기에, 사람이 눈으로 보고 규칙을 만들 수 있었습니다.
1규칙 기반의 한계¶
규칙 기반은 직관적이지만, 규칙을 사람이 모두 만들어야 합니다. 특성이 많거나 경계가 복잡한 데이터에서는 손으로 규칙을 작성하는 것이 사실상 불가능합니다. 그래서 데이터로부터 규칙을 스스로 학습하는 알고리즘이 필요합니다.
이어지는 장에서는 정답을 보고 배우는 지도 학습과, 정답 없이 데이터의 구조를 찾는 비지도 학습 알고리즘을 살펴봅니다.