지금까지 다룬 알고리즘은 대부분 지도 학습(supervised learning) 이었습니다. 입력과 함께 정답(목표값)이 주어지고, 모델은 입력에서 정답으로의 관계를 학습합니다. 이와 달리 비지도 학습(unsupervised learning) 은 정답 없이 데이터 자체의 구조만으로 학습합니다.
군집(clustering) 은 대표적인 비지도 학습으로, 서로 비슷한 표본끼리 묶어 그룹(군집)을 형성합니다. 정답을 미리 경험하지 않고 데이터의 분포와 패턴만으로 스스로 그룹을 찾습니다.
1K-평균 군집¶
K-평균(K-Means) 은 데이터를 미리 정한 개수 의 군집으로 나누는 알고리즘입니다. 각 군집의 중심을 잡고, 각 표본을 가장 가까운 중심에 배정하는 과정을 반복하며 중심을 데이터에 맞춰 나갑니다.
붓꽃 데이터에 적용해 보겠습니다. 붓꽃은 세 품종이므로 군집 수를 3으로 설정합니다.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import pandas as pd
iris = load_iris()
model = KMeans(n_clusters=3, random_state=0)
model.fit(iris.data) # 입력만 전달 — 정답(target)은 주지 않는다
예측 = model.predict(iris.data)학습에서 가장 중요한 차이는 model.fit(iris.data) 에 정답을 주지 않습니다는 점입니다. 비지도 학습은 정답을 경험하지 않으므로, 지도 학습과 달리 훈련 데이터와 시험 데이터를 구분할 필요도 없습니다. 모델은 오직 입력 데이터의 구조만 보고 비슷한 표본끼리 묶습니다.
학습이 끝나면 model.predict() 로 각 표본이 어느 군집에 속하는지 얻습니다. 실제 품종 라벨과 모델이 만든 군집 라벨의 분포를 나란히 견주어 보겠습니다.
라벨분포측정 = lambda labels: pd.Series(labels).value_counts()
pd.DataFrame({
'실제 라벨': 라벨분포측정(iris.target),
'예측 라벨': 라벨분포측정(예측),
})여기서 주의할 점이 있습니다. 군집 번호(0, 1, 2)는 임의로 매겨진 것이라, 그 자체가 품종 번호와 일치하지 않습니다. 즉 '군집 0’이 '품종 0’을 뜻하지는 않습니다. 비지도 학습은 정답을 모르므로 그룹에 의미 있는 이름을 붙일 수 없고, 단지 '비슷한 것끼리 묶었다’는 사실만 압니다. 그래서 라벨 번호를 직접 맞춰 보는 대신, 각 그룹의 크기와 분포가 실제 품종 구조와 얼마나 닮았는지를 봅니다.
분포를 보면 한 그룹은 50개로 실제 한 품종(50개)과 정확히 일치하고, 나머지 두 그룹은 50개 부근에서 갈립니다. 정답 없이도 데이터의 잠재적 구조를 상당히 잘 잡아낸 것입니다. 이를 시각적으로 확인해 보겠습니다.
import matplotlib.pyplot as plt
x1 = iris.data[:, 0] # 꽃받침 길이
x3 = iris.data[:, 2] # 꽃잎 길이
plt.figure(figsize=(10, 4))
for i, (제목, 라벨) in enumerate({'실제 품종': iris.target, 'K-평균 군집': 예측}.items()):
plt.subplot(1, 2, i + 1)
plt.scatter(x1, x3, c=라벨, cmap='brg')
plt.title(제목)
plt.xlabel('꽃받침 길이'); plt.ylabel('꽃잎 길이')
plt.grid()
plt.tight_layout()
plt.show()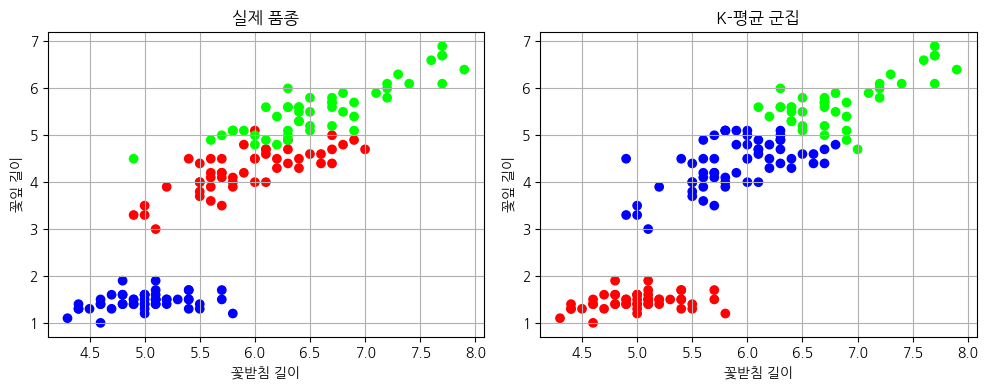
왼쪽은 실제 품종, 오른쪽은 K-평균이 정답 없이 찾아낸 군집입니다. 색의 구획이 거의 비슷하게 나뉘는데, 특히 왼쪽 아래에 뚜렷이 떨어진 한 품종은 완벽하게 분리됩니다. 나머지 두 품종은 경계가 겹쳐 일부 표본이 다르게 묶이지만, 전체적인 구조는 잘 드러납니다.
정리하면, 군집은 정답 없이 데이터의 구조만으로 비슷한 표본을 묶는 비지도 학습입니다. 정답이 없으므로 훈련/시험 구분이 필요 없고, 결과로 얻은 군집 번호는 임의이며, 그룹의 분포와 형태로 데이터의 잠재 구조를 해석합니다.