UCI 머신러닝 저장소의 자동차 연비(auto-mpg) 데이터로 회귀를 실습합니다. 사이킷런 예시 데이터가 아니라 직접 내려받은 실제 데이터를 적재·전처리하고, 탐색적 분석을 거쳐 선형 회귀를 적용하며, 특성 공학으로 성능을 끌어올립니다. 끝에서는 여러 회귀 알고리즘을 같은 기준으로 비교합니다.
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
print(f'numpy: {np.__version__}')
print(f'pandas: {pd.__version__}')
print(f'scikit-learn: {sklearn.__version__}')
from sklearn.linear_model import LinearRegressionnumpy: 2.2.6
pandas: 2.3.3
scikit-learn: 1.7.2
from sklearn.model_selection import train_test_split
def 모델평가(model, X, y, return_split=False, print_scores=False, **설정):
if X.ndim == 1:
X = X.reshape(-1, 1)
assert X.ndim == 2
X_train, X_test, y_train, y_test = train_test_split(X, y, **설정)
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
if print_scores:
print(f'훈련: {train_score:.3f}, 시험: {test_score:.3f}')
if return_split:
return {'train': train_score, 'test': test_score}, (X_train, X_test, y_train, y_test)
return {'train': train_score, 'test': test_score}실제 예시 데이터를 가지고 응용하면서 살펴보겠습니다. 이번에는 사이킷런에서 기본적으로 제공하는 데이터 대신 새로운 데이터를 우리가 직접 획득해서 활용하겠습니다. 그것이 우리의 목표이기도 합니다. 미국 캘리포니아 대학 UCI 머신러닝 웹사이트에서 제공하는 공개된 데이터가 많이 활용됩니다. 사이킷런과 텐서플로우 등 여러 머신러닝 라이브러리에서 예시 데이터셋을 제공할 때 그 출처가 종종 이 웹사이트입니다. 여기서 제공하는 데이터 중 일부를 선별해서 필요에 따라 적절하게 가공해서 제공하고 있습니다.
연속적인 출력을 발생하는 회귀분석 데이터 예시는 사이킷런에서 많이 제공하지 않는 편입니다. 대체로 붓꽃과 같은 분류 예시가 많습니다. 기존에 많이 사용되는 보스턴 데이터셋 있기는 한데, 이 데이터셋은 그 수집된 방식과 활용의 목적이 윤리적인 문제가 있기 때문에 권장되지 않는 편입니다.
웹에서 직접 데이터를 획득하는 것이 전혀 어렵지는 않습니다. 그래서 이번에는 자동차의 연비를 회귀 분석하는 사례로 살펴보겠습니다. Auto MPG 데이터셋을 웹사이트에서 선택합니다. 해당 데이터 셋에 대한 설명 등이 표시가 되고, 다운로드 폴더에서 다운로드 받는 것이 가능합니다. 클릭하면 파일 형태로 다운로드 받을 수 있습니다. 데이터가 두 가지 준비되어 있습니다. .data와 .data-original이 있습니다. 파일명으로 짐작할 수 있다시피, 원본의 데이터는 오리지널인데, 해당 데이터에서 필수적인 값이 누락되어 있거나 해서 그런 값들을 제거하고 제공하는 것이 .data입니다. .names 파일은 데이터셋에 대한 문서입니다. 특성의 명칭 의미 등을 문서 형태로 제공하고 있습니다. 같이 다운로드 받아서 활용하겠습니다.
웹 브라우저에서 다운로드 받은 파일은 기본적으로 다운로드 폴더에 위치합니다. 그래서 주피터 노트북에서 다운로드 폴더를 찾아서 해당 파일들을 열어보겠습니다. 다운로드 받은 데이터는 일반 텍스트 파일 형식입니다. 주피터에서는 기본적으로 텍스트 파일을 열어 보는 것이 가능합니다.
표 형식으로 대부분 숫자 값들이 나열되어 있습니다. 마지막 열의 경우 차량의 이름으로 보입니다. 나머지는 그냥 짐작은 불가능하기 때문에 같이 다운로드 받은 문서 파일을 확인해보겠습니다. 아래쪽에 보면 398 건의 데이터 포인트와 아홉 가지의 특성 그리고 각 특성의 정보가 표시됩니다. 우리가 예측하고자 하는 연비는 첫 번째 열의 mpg입니다. 나머지는 엔진 실린더 개수, 마력, 중량 등과 같은 정보입니다. 그런데 마지막에 보면 마력에서 여섯 건의 정보가 누락되어 있다고 하는 부분을 확인할 수 있습니다. 그래서 그런 부분들을 실제 데이터에서 확인해보니, 해당 부분은 물음표로 표기를 한 것으로 보입니다. 나머지 부분은 정보가 있기 때문에 일단은 그대로 제공하는 것으로 보이는데, 활용 여부는 데이터를 사용하는 사람이 결정해야 합니다.
데이터에 대해서 살펴봤기 때문에 이제 이 데이터를 적재하겠습니다. 적재를 할 때 다운로드 받은 파일을 기준으로 해서 적재를 하는 것이 당연히 가능합니다. 그런데 파일의 경로가 서로 다르면 혼선이 있을 수 있기 때문에 웹 사이트의 해당 파일 URL을 직접 지정해서 파일 다운로드 절차 없이 바로 읽어오겠습니다. 웹사이트에서 해당 파일을 왼쪽 클릭하는 대신, 오른쪽 클릭으로 링크 주소 복사를 선택합니다. 이 방식과 명칭의 표기는 웹브라우저마다 약간씩 다를 수 있습니다. 현재 화면에서는 크롬 브라우저를 사용하고 있습니다.
1데이터 적재¶
다운로드 받은 파일을 확인해보니 각 열들이 띄어쓰기로 구분되어 있습니다. 데이터는 표 형식이기 때문에 우리가 활용해왔던 pandas 라이브러리를 여전히 사용하겠습니다. 이런 형식의 경우 pandas.read_fwf API로 읽어오면 편리합니다. 열 제목이 포함되어 있지 않기 때문에 “열 제목 없음”, header=None을 설정합니다.
다음과 같이 읽어온 것을 확인할 수 있습니다.
import os.path
DATA_DIR = '../data'
FILE_PATH = os.path.join(DATA_DIR, 'auto-mpg/auto-mpg.csv')
if not os.path.exists(FILE_PATH):
auto_mpg = pd.read_fwf('https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data', header=None)
else:
auto_mpg = pd.read_csv(FILE_PATH)아까 문서를 참조해서 열 제목을 직접 설정하겠습니다.
auto_mpg.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'car name']이렇게 정리한 데이터를 매번 읽어와서 같은 작업을 반복하는 것은 바람직하지 않기 때문에 이 상태를 파일로 내보내겠습니다.
auto_mpg.to_csv(FILE_PATH, index=False, encoding='utf8')지금부터는 우리가 정리한 파일로부터 바로 읽어 오면 편리합니다.
이러한 절차는 지금의 실습을 위해서 필요하기도 하고, 앞으로 다양한 데이터셋을 직접 활용하는 방식으로서 권장합니다.
auto_mpg = pd.read_csv(FILE_PATH)
auto_mpg데이터프레임을 출력해 보고, info API로 전반적인 정보를 확인할 수 있습니다.
표본 398건, 특성 9개임을 확인할 수 있습니다.
auto_mpg.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 398 non-null object
4 weight 398 non-null float64
5 acceleration 398 non-null float64
6 model year 398 non-null int64
7 origin 398 non-null int64
8 car name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
2누락 데이터¶
데이터의 문서에서, 마력 열에서 누락된 데이터가 있다고 했습니다. 그런 데이터는 물음표로 표기가 되어 있다고 했습니다. 그래서 해당 열에서 그런 것들을 확인해 보겠습니다.
스칼라 값과 비교하면, 기본적으로 열의 각각의 값들과 비교 연산이 수행됩니다. 그 결과 참 거짓 부울 값이 발생합니다. 이것을 합산하면 여섯 개의 값이 누락된 것을 확인할 수 있고, 이 부분은 문서와 일치합니다.
(auto_mpg['horsepower'] == '?').sum()np.int64(6)2.1누락 데이터 제거¶
누락된 데이터를 어떻게 처리해야 하는가는 여러 가지 방법이 있습니다. 경우에 따라서는 값을 평균값 등으로 짐작하는 방식을 사용할 수도 있는데, 지금의 경우에는 그런 방식이 적절하지 않을 것 같습니다. 그래서 지금은 누락된 값을 포함한 표본은 제외하는 것이 바람직할 것 같습니다.
아까의 비교 연산을 수행한 결과를 바탕으로, 물음표 값이 아닌 값들만 선별하겠습니다.
데이터 프레임에서 행을 제거할 때, 정수 색인이라도 색인이 자동으로 다시 부여되지 않습니다. 즉 우리가 전체 398 건에서 여섯 개를 제거해서 총 392 건이 됐지만 마지막 색인 번호는 여전히 397 인 것을 확인할 수 있습니다. 그 이유는 열을 제거하는 것에 대비해서 생각해보면 이런 방식이 자명합니다. 일부 열을 제거한다고 해서 열 제목이 다시 부여되지 않습니다. 그렇게 되어도 안 되겠죠. 같은 이유로 색인도 그렇습니다. 그런데 지금의 경우 열 제목과는 달리 색인이 순서를 의미하기 때문에 그 의미를 반영하기 위해서 현재 상태에서 빠진 번호없이 색인이 다시 부여되도록 하는 것이 바람직합니다. reset_index api 를 사용합니다. 그럼 이제 392 건의 표본이 있고 마지막 색인 번호는 391 번입니다.
auto_mpg = auto_mpg[auto_mpg['horsepower'] != '?']
auto_mpg = auto_mpg.reset_index(drop=True)
auto_mpg실제로 제거가 되었는지 확인하는 것도 중요합니다.
(auto_mpg['horsepower'] == '?').sum()np.int64(0)2.2자료형 조정¶
그런데 지금과 같이 누락된 값이 포함된 것을 제외할 때, 주의할 점이 있습니다. 대부분은 숫자 형인데 지금처럼 물음표 같은 일부 문자가 삽입된 경우 열의 자료형은 문자열을 포함하기 위해서 가장 일반적인 Object 형이 됩니다. 이런 기호를 제거했다고 해서 원래의 자료형이 자동으로 바뀌지는 않습니다.
확인해보면 horsepower 열의 자료형이 여전히 object 로 되어 있습니다.
auto_mpg.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 392 entries, 0 to 391
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 392 non-null float64
1 cylinders 392 non-null int64
2 displacement 392 non-null float64
3 horsepower 392 non-null object
4 weight 392 non-null float64
5 acceleration 392 non-null float64
6 model year 392 non-null int64
7 origin 392 non-null int64
8 car name 392 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 27.7+ KB
자료형 변환는 명시적으로 해야 합니다. horsepower 열을 선택하고, astype API에서 float32, 32비트 부동소수점으로 설정합니다. astype API는 변환된 결과를 새로운 객체로 반환하기 때문에 이것을 다시 데이터프레임의 원래 열에 할당하는 것이 필요합니다.
이제는 float32로 변환되었음을 확인할 수 있습니다. “car name”을 제외한 다른 속성들은 숫자 형이고 정수와 부동소수점 형이 섞여 있습니다. 또한 우리는 32 비트 정밀도를 설정했는데, 기본적으로 64 비트가 설정될 수도 있습니다. 지금은 데이터가 작기 때문에 무엇이든 큰 상관 없습니다. 하지만 데이터가 커지면 64 비트는 메모리를 많이 낭비할 수 있으니까 대체로 32 비트를 권장합니다.
auto_mpg['horsepower'] = auto_mpg['horsepower'].astype('float32')
auto_mpg.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 392 entries, 0 to 391
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 392 non-null float64
1 cylinders 392 non-null int64
2 displacement 392 non-null float64
3 horsepower 392 non-null float32
4 weight 392 non-null float64
5 acceleration 392 non-null float64
6 model year 392 non-null int64
7 origin 392 non-null int64
8 car name 392 non-null object
dtypes: float32(1), float64(4), int64(3), object(1)
memory usage: 26.2+ KB
3탐색적 데이터 분석¶
새로운 데이터를 획득했으니 탐색적 데이터 분석을 하는 것이 필요합니다. 탐색적 데이터 분석은 실제 기계학습 알고리즘을 적용하기 전에 데이터에 어떤 문제가 없는지, 혹은 다른 형태로 변형을 하는 것이 필요한지 등을 결정하기 위해서 필수적인 과정입니다. 그런데 통계에서 와는 다르게 이런 과정을 통해서 실제로 예측을 하려고 하는 것은 아닙니다. 실제 예측을 하기 위한 모형을 구성하는 것은 우리가 아닌 기계, 즉 알고리즘이 해야 합니다. 그래서 탐색적 데이터 분석은 필요한 만큼만 간단하게 하는 정도로써 시작하는 것이 바람직합니다. 기계학습 알고리즘 훈련에서 문제가 생기면 그때는 그 문제의 원인을 짐작해 보기 위해서 추가적으로 탐색적 데이터 분석을 시도할 수 있는데, 미리부터 너무 상세하게 할 필요는 없습니다. 그런 분석을 하지 않고도 그냥 좋은 결과를 얻을 수도 있기 때문입니다. 또한 그런 분석을 하는 것과 좋은 결과를 얻는 것은 다른 문제입니다. 그래서 일단은 가볍게 해보겠습니다.
모델 연도를 확인하면 70 년도에서 80 년도 초반 정도임을 확인할 수 있습니다.
auto_mpg['model year'].unique()array([70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82])각 특성의 상관관계 분석을 해 보겠습니다. 데이터 프레임에서 준비된 api 를 활용하면 편리하게 할 수 있습니다.
결과에서 mpg를 선택해 다른 값들과의 상관관계에 지표를 확인할 수 있습니다. 자기 자신과의 상관도는 1.0입니다. 값을 정렬해서 살펴보겠습니다. 기본적으로 오름차순으로 정렬이 됩니다. 음수 값은 반대 상관도를 가진다는 것을 의미합니다. 중량과 연비는 서로 반대의 경향이 있습니다. 중량이 클수록 연비는 안 좋아집니다. 대체로 상식에 부합합니다. Displacement, 즉 배기량 역시 크면 연비값과 반대 경향이 있습니다. 마력과 실린더 수가 증가하는 것도 연비에 부정적인 영향을 주는 것 같습니다. 가속력은 연비와 양의 상관관계가 있습니다. 가볍고 배기량이 작은 차가 상대적으로 가속력이 좋을테니 그런 차는 중량과 배기량이 대체로 작을 테니까 아마 그래서 연비와 양의 상관관계가 있지 않을까 생각합니다. origin은 제조 지역을 의미합니다. 이부분은 양의 상관관계인데, 어떤 값들이 있어서 그런지 확인이 필요해 보입니다. 지금은 왜 그런지 알기 어렵습니다. 제조 연도를 뜻하는 model year도 양의 상관관계가 있습니다. 아마 세월이 지나면서 기계들은 효율이 좋아지는 것을 반영하지 않나 싶습니다.
auto_mpg.corr(numeric_only=True)['mpg'].sort_values()weight -0.832244
displacement -0.805127
horsepower -0.778427
cylinders -0.777618
acceleration 0.423329
origin 0.565209
model year 0.580541
mpg 1.000000
Name: mpg, dtype: float64origin
미국
유럽
일본
origin 열은 문서에서 자세한 설명이 없습니다. 결론적으로 이것은 차량이 제조된 지역을 의미합니다. 도수 집계를 해보겠습니다.
1 미국, 2 유럽, 3은 일본입니다. 미국이 가장 많고 일본 유럽 순입니다. 미국에서 수집한 데이터니까 당연한 것 같습니다.
auto_mpg['origin'].value_counts()origin
1 245
3 79
2 68
Name: count, dtype: int643.1브랜드 분석¶
이번에는 브랜드 분석을 해보겠습니다. “car name” 특성은 문자열로 기록된 값입니다. 값들은 띄어쓰기로 구분되어 있고, 첫 번째 부분이 차량의 브랜드입니다. 브랜드를 추출하는 간단한 함수를 정의해서 활용하겠습니다. “car name” 특성열이 선택되어 발생한 시리즈 자료구조를 입력으로 합니다. 시리즈의 문자열 처리 api 를 활용해서 각각의 값을 공백으로 나눈 다음 그 결과 발생한 목록에서 첫 번째 값을 선택합니다. 브랜드명칭에 대해 도수 집계를 수행하여 반환합니다. “car name” 특성열을 정의된 함수의 입력으로 제공하여 도수 집계 결과를 확인해 보겠습니다.
시리즈 api 에서는 도수 집계 결과를 기본적으로 내림차순으로 정렬합니다. 미국 지역이 많으니까 당연히 미국 브랜드가 상위에 위치합니다. 포드가 가장 많습니다.
def 브랜드도수집계(차량명칭):
브랜드명칭 = 차량명칭.str.split().str[0]
브랜드도수 = 브랜드명칭.value_counts()
return 브랜드도수
브랜드도수집계(auto_mpg['car name'])[:5]car name
"ford 48
"chevrolet 43
"plymouth 31
"dodge 28
"amc 27
Name: count, dtype: int643.1.1지역별 상위 브랜드 분석¶
지역별 브랜드 분석도 가능합니다. 지금 정의한 함수를 지역별로 적용하도록 하면 됩니다. 데이터 프레임을 origin 값으로 그룹을 형성하고, 각 그룹에서 car name 열을 선택한 다음, 우리가 정의한 함수를 적용하여 그 결과에서 처음 다섯 개만 선택한 다음 그것의 색인을 추출하여 시리즈로 만드는 간단한 인라인 함수를 정의합니다. 각 그룹의 해당 함수가 적용된 다음 하나로 합쳐집니다. 그 결과를 보기 좋은 형식으로 출력합니다.
지역 1 미국에서는 포드, 쉐보레 등과 같은 미국 브랜드 명칭을 확인할 수 있습니다. 지역 2 유럽에서는 폭스바겐, 푸조, 피아트 순입니다. 지역 3일본에서는 토요타 등이 있습니다. 7, 80년대라서 지금과 순위가 많이 다를 수도 있고, 없어진 브랜드도 있는 것 같습니다.
auto_mpg.groupby(by='origin')['car name'].apply(lambda 차량명칭: pd.Series(브랜드도수집계(차량명칭)[:5].index)).unstack()3.2제조 지역별 비교¶
각 특성의 평균도 지역별로 살펴보겠습니다.
연비는 미국 차가 제일 안 좋고, 유럽 일본 순입니다. 엔진 기통수 평균값은 미국은 6개이고, 유럽과 일본은 4개입니다. 미국 차는 다른 지역과 대비해서 평균 배기량이 2배 이상입니다. 그에 따라 중량도 평균적으로 1.5배 정도 무겁습니다.
auto_mpg.drop(columns=['car name']).groupby('origin').mean()3.2.1지역별 실린더 수 비교¶
미국 차는 실린더 수 평균이 다른 지역에 비해서 높은데요, 왜 그런지 살펴보기 위해서 지역별 엔진 기통수 도수 집계를 해보겠습니다.
7,80년대 미국 차는 8기통이 가장 비중이 높습니다. 다른 지역은 8기통이 아예 없습니다. 대부분은 4기통 이고, 일본 차의 경우에는 특이하게도 3기통이 있습니다.
auto_mpg.groupby(by='origin')['cylinders'].value_counts().unstack()3.2.2지역별 기통수별 연비 비교¶
차가 크고 무거울수록 엔진 기통수도 높아지는 경향성이 있을 것 같습니다. 그러다보면 연비 효율도 안 좋아질 수 있는데요, 공정한 비교를 위해서는 같은 기통수에서 비교가 필요할 것 같습니다. 이번에는 지역별 기통수별 평균을 비교해 보겠습니다.
제조 지역과 기통 수 평균을 살펴보면 모든 국가에서 공통적으로 제조하는 실린더 수는 4기 통과 6기통 입니다. 4기통과 6기통해서 비교하면, 같은 기통 수에서 미국과 유럽은 거의 비슷하고 일본은 다른 지역에 비해서 같은 기통에서도 효율이 좋은 편입니다. 특이한 점은 미국의 경우만 8기통 엔진을 제작하고 예상대로 연비 효율은 매우 안 좋습니다. 8기통 엔진은 연비를 위해서 타는 차는 아닌 것 같습니다. 그런데 일본만 제공하는 3기통의 경우 연비가 4기통이나 6기통 보다 안 좋습니다. 그래서 실린더 수만으로 연비를 정확하게 예측하는 것은 어려울 것 같습니다.
auto_mpg.groupby(by=['origin', 'cylinders'])['mpg'].mean().unstack()3.3정리¶
이런 활동을 통해서, 현재 특성들이 우리가 예측하고자 하는 것과 어느 정도 상관관계가 있다는 짐작과 통찰 정도를 얻는 것이 필요합니다. 구체적인 것은 실제 기계학습 알고리즘이 이러한 관계를 알고리즘의 특성에 따라 적절하게 반영하는 것이 필요합니다.
4회귀 분석¶
탐색적 데이터 분석을 통해 데이터를 살펴 보았으니 이제는 선형 회귀를 적용해 보겠습니다. 지도 학습을 위해 디자인 행렬 X와 목표값 y형식으로 준비합니다.
예측 대상인 연비 정보 mpg 열은 y이기 때문에 X에서는 제외합니다. 그리고 차량의 명칭은 연비를 예상하는 것과는 상식적으로 관련이 없어 보입니다. 이름을 잘 짓는다고 연비가 좋아지는 건 아니니까요. 그래서 특성에서 제외하겠습니다. 나머지 특성들은 탐색적 데이터 분석을 했을 때 대체로 연관이 있다고 추정합니다. 이러한 추정은 정확할 필요는 없습니다. 정확하게 하는 것은 알고리즘이 해야 하는 일입니다.
마지막으로 입력은 모두 숫자값이어야 합니다. 표 형식의 데이터는 종종 열별 자료형이 서로 다를 수 있습니다. 그래서 최종적으로는 전체를 부동 소수점 형식으로 설정하겠습니다. 부동 소수점 정밀도는 32 비트를 권장합니다. 64 비트로 해도 상관은 없지만 데이터의 규모가 커지면 메모리를 낭비하게 됩니다. 만약 이런 변환 과정에서 문제가 있으면 어딘가에 우리가 확인하지 못한 숫자형으로 변화될 수 없는 값이 있다는 것을 의미합니다. 그래서 그런 값들을 확인하는 방법으로도 이런 변환을 명시적으로 하는 것을 권장합니다.
잘 실행이 되고 별다른 문제가 없었습니다. 데이터프레임의 정보를 확인해보면 모든 특성의 자료형이 우리가 지정한 부동 소수점 32 비트로 된 것을 확인할 수 있습니다.
y = auto_mpg['mpg']
X = auto_mpg.drop(columns=['mpg', 'car name'])
X = X.astype('float32')
X.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 392 entries, 0 to 391
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cylinders 392 non-null float32
1 displacement 392 non-null float32
2 horsepower 392 non-null float32
3 weight 392 non-null float32
4 acceleration 392 non-null float32
5 model year 392 non-null float32
6 origin 392 non-null float32
dtypes: float32(7)
memory usage: 10.8 KB
X 랑 y 개수는 항상 일치하는지 확인하는 것이 바람직하고, 최종적으로 형성된 디자인 행렬의 형상을 살펴보면 이제 일곱 개의 특성입니다.
assert len(X) == len(y)
X.shape(392, 7)데이터를 구성하고 나면 대략적으로 살펴보면서 구성이 올바른지 확인하는 것은 언제나 필요합니다.
잘 구성된 것을 확인할 수 있습니다. 한 가지 중요한 특성별 차이점은 우리가 분석의 대상으로 했던 엔진 기통 수, 제조 지역, 연도는 정수형 이산값이고, 나머지는 부동 소수점 연속형 변수입니다. 이산값의 경우, 연속형 변수와 다른 처리가 필요한 경우가 있습니다. 특히 제조 지역처럼 숫자 값이 서로 대소 관계로 해석되기 어려운 경우 그렇습니다. 미국 1, 유럽 2, 일본 3인데, 이 값들은 인위적인 구분을 위한 숫자 값이 뿐이지 미국이 일본보다 작다는 의미는 아닙니다. 비교해서 실린더 수도 이산값이지만, 8기통은 4기통보다 큽니다. 다만 4.32기통 같은 것은 없기 때문에 이산값입니다. 그래서origin 특성의 경우, 특별한 처리가 필요할 수 있지만 비교를 위해서 별다른 가공을 하지 않고 일단 먼저 알고리즘을 적용해 보겠습니다.
X데이터가 지도 학습용으로 준비가 되었다면 모델을 훈련하고 평가하는 방식은 표준적입니다. 모델 평가 함수를 활용해서 결과를 확인해 보겠습니다. 난수 초기 값을 설정해서 섞이는 순서를 고정하겠습니다.
훈련과 시험 점수가 거의 유사한 R2 0.82입니다. 나쁘지 않은 점수입니다. 우리가 탐색적 데이터 분석에서 대략적으로 추정할 수 있는 정도의 데이터이기 때문에 그다지 어려운 것이 아니라서 기계학습 알고리즘도 수월하게 수행합니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X, y, print_scores=True, random_state=0)훈련: 0.820, 시험: 0.821
일곱 개의 특성에 대해서 훈련이 수행 되었기 때문에, 각 특성에 대응하는 가중치도 7개 입니다.
linreg.coef_.shape(7,)훈련된 가중치 의미를 분석해 보겠습니다.
가중치 값을 확인하면, 어떤 숫자들이 설정된 것을 확인할 수 있습니다. 이 값은 이 문제에 대해서 최적화된 매개변수입니다. 막대그래프로 이 값들을 시각화해 보겠습니다. 각 가중치는 특성에 일대일로 대응하기 때문에 그래프를 그릴 때에 그것을 반영하면 의미를 분석하는 데 도움이 됩니다.
실린더 수의 경우 음의 값을 갖고, 지역과 연도는 양의 값을 갖습니다. 그 의미는 우리가 목표로 하는 출력인 연비와의 관계를 시사합니다. 음수 값이면 반대의 관계를 갖는다는 의미로 해석할 수 있고 양의 상관관계를 갖는다면 해당 특성과 출력이 대체로 비례하는 관계에 있다는 것을 뜻할 수 있습니다. 나머지 다른 특성들에서는 가중치 절대값이 아주 작습니다. 만약 어떤 특성의 가중치가 영 이라면, 그것은 해당 특성이 어떤 값을 갖든 가중치와 곱해지면 영이 되어 버리기 때문에 결과적으로 그 특성은 제외된다고 할 수 있습니다. 지금의 경우 완벽하게 영이 된 특성은 없습니다. 하지만 영에 무척 가까운 값이 설정된 경우도 있습니다. 대체로 가중치 절대값이 크면 해당 특성이 중요하다는 점을 시사합니다.
그런데 우리가 탐색적 데이터 분석을 수행했을 때, 중량과 배기량이 연비에 상당히 중요한 특성으로 보였는데 지금은 해당 특성들에 대한 가중치가 매우 작아서 조금 의아합니다.
print(f'w: {linreg.coef_}')
pd.Series(linreg.coef_, index=X.columns).plot(kind='barh')w: [-0.36507985 0.01198687 -0.0064181 -0.00641512 0.13142921 0.71865547
1.2071702 ]
<Axes: >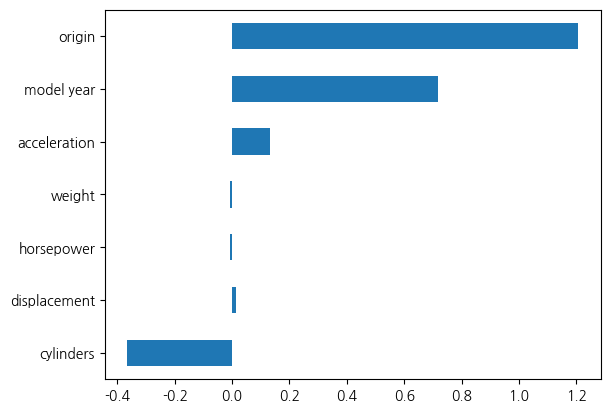
4.1단위 정규화¶
그 이유는 수치들이 단위가 서로 많이 달라서 그렇습니다. 실린더 수와 같은 값들은 일 단위인데 배기량이나 마력, 중량은 백 단위 또는 천 단위입니다. 그렇다면 이런 값들을 동시에 처리하기 위해서 작은 값들은 큰 값에 맞추기 위해 가중치가 커지고 큰 값들의 대해서는 작은 값에 맞추기 위해서 상대적으로 가중치가 작아져야 합니다. 이렇게 하다 보면, 작은 값의 변화에 대해서는 너무 민감하게 반응하고, 단위가 큰 값의 변화에 대해서는 너무 둔하게 반영될 수 있습니다. 그렇다면 모형이 효과적으로 구성되는데 방해가 됩니다.
이런 문제를 개선하기 위해서 단위 정규화를 하는 것이 바람직합니다. 가장 간단한 방식은 최대 최소 정규화입니다. 각 열별로, 값을 최소 값으로 빼준 다음 최대 최소의 차이로 나눠주는 변환입니다. 그 결과를 이전과 구분해서 X_scaled 변수에 할당하겠습니다.
X_scaled = (X - X.min()) / (X.max() - X.min())
X_scaled그 결과 각 열의 값은 0과 1 범위 값이 됩니다. 원래 값의 단위 의미에 대해서 고민할 필요는 없습니다.
X_scaled.apply(['min', 'max'])단위 정규화된 입력에 대해서 다시 한번 선형 회귀를 적용해 보겠습니다. 비교를 위해 항상 같은 설정을 사용합니다.
훈련과 시험결과는 완벽하게 동일합니다. 그래서 단위 정규화의 이익이 있는지 의구심이 들 수 있습니다. 지금은 차이가 없었는데 대체로 단위 정규화를 하지 않으면 선형 모델의 모형 형성에 부정적인 영향을 주는 편이고, 그로 인해 잠재적으로 달성할 수 있는 성능에 미달하는 경우가 많습니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X_scaled, y, print_scores=True, random_state=0)훈련: 0.820, 시험: 0.821
같은 방식으로 가중치 값도 시각화를 통해 살펴보겠습니다.
이전과 달리 중량에 대응하는 가중치 값이 상대적으로 아주 큰 것을 확인할 수 있습니다. 상대적으로 엔진 기통 수에 대응하는 가중치 값은 훨씬 작은 편입니다. 같은 성능이지만 가중치 분석에서 결과는 상당히 다릅니다. 대체로 단위 정규화를 했을 때 가중치 의미가 우리가 탐색적 데이터 분석을 통해서 살펴봤던 것과 좀 더 유사합니다. 그런데 배기량의 경우, 현재로서는 가중 치 값이 양수인데요, 이 부분은 올바로 된 것인가 조금 의아합니다. 이런 가중치를 완전히 신뢰할 수 없는 이유가 무엇이냐면, 훈련과 시험 점수가 괜찮은 편이긴 해도 80 점 초반대로 썩 좋지는 않기 때문입니다. 이런 가중치 분석을 할 때 유의할 점은, 성능이 상당히 좋은 경우에 비로서 가중치도 해석할 가치가 있는 것입니다. 비유하자면 어떤 문제에 대해서 전문가에게 의견을 구하는 것과 그렇지 않은 사람에게 의견을 구하는 것의 차이입니다. 잘 모르는 사람한테 물어보고 의견을 구하면 그 사람이 자신의 의견을 얘기해줄 수는 있겠지만 그것을 우리가 신뢰하기는 어렵겠죠. 마찬가지로 지금의 가중치가 어느 정도 성능을 냈기 때문에 완전히 틀린 것은 아니겠지만, 그렇다고 해서 완전히 좋은 성능도 아니기 때문에 모두 다 맞다고 할 수는 없습니다. 그렇다면 문제는 더 좋은 성능을 획득하는 것입니다.
pd.Series(linreg.coef_, index=X_scaled.columns).plot(kind='barh')<Axes: >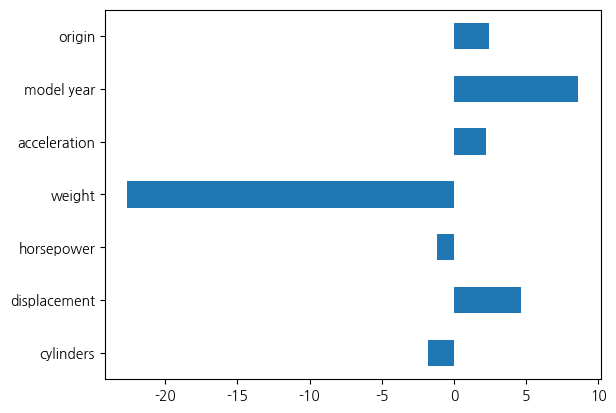
우리는 선형 회귀 모형의 기본 원리를 살펴보면서 새로운 데이터셋을 획득하여 살펴보기 시작했습니다. 다음으로는 선형 모형의 성능을 향상시키기 위해서 특성과 표현력이 어떤 관계에 있는지를 살펴보고, 그것들을 활용해서 선형 모형의 잠재력을 끌어내 목표를 달성하는 방법들을 살펴보겠습니다.
5특성 공학¶
더 좋은 성능의 비결은 종종 데이터에 있습니다. 데이터는 표본의 규모와 특성이 중요합니다. 표본이 많아도 특성이 부족하면 제대로 모형을 형성하기 어렵고 반대로 특성이 많은데 표본이 부족하면 과적합의 위험이 있습니다.
5.1특성 선별¶
가중치 값이 컸던 주요 특성들을 일부 선별해서 알고리즘을 훈련하고 결과를 평가해 보겠습니다. 먼저 weight, 중량 특성만을 사용한 결과를 보겠습니다. 이것을 먼저 선택한 이유는, 탐색적 데이터 분석에서 연비와 상관도가 높고, 선형 회귀에서도 가중치 값이 가장 컸기 때문입니다. 특성 하나만 사용하기 때문에 1차원 데이터가 되고, 이에 대해 선형 모델은 직선의 예측 모형을 형성하게 됩니다.
훈련 점수 0.7, 시험 점수 0.65 정도입니다. 특성 하나만을 사용했지만 전체 특성을 모두 사용했을 때 대비해서 90%의 성능을 달성하고 있습니다. 가중치 절대값이 큰 이유를 짐작할 수 있습니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X_scaled[['weight']], y, print_scores=True, random_state=0)훈련: 0.703, 시험: 0.659
현재로서는 가중치 절대값이 두 번째로 큰 것이 제조 연도를 뜻하는 “model year” 입니다. 그래서 이번에는 연도 정보를 추가해 보겠습니다.
이 두 가지 특성만으로도 훈련과 시험 점수 결과가 전체 특성을 모두 사용하는 경우에 근접한 점수를 얻었습니다. 실제로 가중치 절대값이 예측 모형에 기여하는 정도는 어느 정도 비례합니다. 가중치가 컸던 특성들만으로도 달성할 수 있는 성능의 대부분을 달성하고 있기 때문입니다. 하지만 모든 특성을 활용할 때와 비교하면 여전히 10% 정도 낮은 수치입니다. 그래서 가중치 절대값이 작게 형성된 특성들도 역할이 있기 때문에 선별적으로 제외하는 것은 신중해야 합니다. 요리에 비유하자면, 전체 요리에서 소금이나 간장이 들어가는 비율은 아주 적지만, 그것이 경우에 따라서는 큰 차이를 내는 것과 비슷합니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X_scaled[['weight', 'model year']], y, print_scores=True, random_state=0)훈련: 0.810, 시험: 0.802
5.2범주형 변수¶
origin 표기 변화
미국 1 -> 3
유럽 2 -> 1
일본 3 -> 2
지역과 관련해서, origin 특성값은 지역별 임의적인 숫자 값을 할당해서 표현했습니다. 그런데 지금으로서는 그 값이 클수록 연비에 긍정적인 영향을 미친다고 해석할 수 있는데, 그것은 공교롭게도 실제로 미국 유럽 일본 순으로 평균 연비가 좋기 때문입니다. 만약 일본을 2, 미국을 3, 유럽을 1로 한다면 어떻게 될까요? 어차피 인위적인 값이기 때문에 이렇게 할당하는 것도 당연히 가능합니다.
먼저 원래 X의 복사본을 만들어 그것을 X2라고 하겠습니다. 등호 기호는 기본적으로 객체 참조를 할당하기 때문에 참조가 아닌 복사를 하려면 .copy() API를 사용해야 합니다. 원래 데이터의 값을 바꾸는 것은 신중해야 합니다. 만약 변환이 마음에 들지 않으면, 처음에 데이터를 적재하는 부분부터 다시 해야할 수 있기 때문입니다.
origin 열을 선택하고, 시리즈 자료구조의 replace API를 활용하겠습니다. 원래 값들의 유형을 나열하고, 그 유형에 일대일로 대응하는 새로운 값을 나열하면 값들이 변환됩니다. 이렇게 변환된 값들은 새로운 객체에 담기기 때문에 이런 변환을 origin 열에 반영하려면 명시적으로 할당해야 합니다.
X2 = X.copy()
X2['origin'] = X2['origin'].replace([1, 2, 3], [3, 1, 2])
X2변화된 표기에서 지역별 연비 평균을 구해 보겠습니다.
연비 값은 y로 추출되었기 때문에 지역별 연비 통계를 구하기 위해서는 X2와 y를 임시적으로 합쳐야 합니다. 데이터프레임 또는 시리즈를 합치는 것은 pandas.concat API로 수행할 수 있습니다. y를 열 방향으로 합치기 위해 1축 방향으로 설정합니다. 이렇게 합쳐진 데이터프레임은 현재만 잠시 활용하는 것이라 변수에 할당하지 않겠습니다. 데이터프레임을 origin 값에 따라 분류하는 groupby 연산을 수행합니다. 각 그룹에서 “mpg” 열을 선택한 다음, 평균을 구하면 그룹별 평균이 구해진 결과가 최종적으로 합쳐져서 출력됩니다.
새로운 표기에서는 일본 1, 유럽 2, 미국 3이고, 이런 숫자값의 증가에 따라서 연비가 증가하지 않습니다.
pd.concat([X2, y], axis=1).groupby(by='origin')['mpg'].mean()origin
1.0 27.602941
2.0 30.450633
3.0 20.033469
Name: mpg, dtype: float64origin 표기에 따른 변화를 비교하기 위해 X2도 단위 정규화를 동일한 방식으로 합니다. 이전과 같은 최대최소 단위 변환입니다.
단위 정규화에 따라 origin 값들도 달라집니다. 1, 2, 3은 각각 0, 0.5, 1.0이 됩니다. 단위가 달라지는 것은 앞서 살펴본대로 가중치가 특성값에 따라 크기가 달라지지 않도록 하는 것이 목적입니다. 단위 정규화를 해도 원래 값의 순서는 보존됩니다.
변환된 디자인 행렬의 최대최소값을 확인하면 당연히 0, 1 범위입니다.
X2_scaled = (X2 - X2.min()) / (X2.max() - X2.min())
print(X2_scaled['origin'].unique())
X2_scaled.apply(['min', 'max'])[1. 0.5 0. ]
X2에 대해 선형 회귀를 훈련하고 결과를 비교해 보겠습니다.
이전과 비교해 시험 점수가 1% 정도 감소했습니다. 감소폭이 크지는 않습니다. 아까 우리가 특성을 선별해서 살펴봤을 때, origin 특성으로 성능이 증감폭이 크지 않았기 때문에 어떤 값으로 바꾼다고 해도 아주 큰 변화가 있지는 않을 것입니다. 하지만 성능이 감소한 것도 사실입니다. 왜냐하면 이제는 그 숫자 값이 연비와 비례하지 않기 때문에 모형의 입장에서는 헷갈린다고 할 수 있습니다. 그렇다면 이전의 표기가 좋았던 것일까요? 그것 역시 아닙니다. 이전의 표기가 공교롭게도 연비와 비례하도록 되어 있었는데 그것은 우연입니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X2_scaled, y, print_scores=True, random_state=0)훈련: 0.820, 시험: 0.814
가중치도 다시 한번 살펴보겠습니다.
아까와는 완전히 반대 방향으로 origin 특성에 대응하는 가중치 값이 음수로 형성된 것을 확인할 수 있습니다. 특성의 표현에 따라 실제로 모형이 다르게 구성된다는 것을 의미합니다. 그렇다면 보다 올바른 표현이 더 적합한 모형 형성에 중요하다는 것을 시사합니다.
pd.Series(linreg.coef_, index=X2.columns).plot(kind='barh')<Axes: >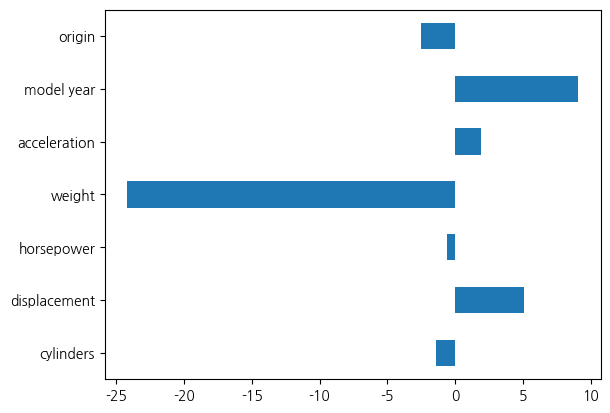
5.2.1One Hot encoding¶
지금과 같은 경우는 데이터의 표현 자체가 바람직하지 않다고 평가할 수 있습니다. 기계 학습의 모든 데이터는 숫자로 표현되어야 합니다. 그것은 사실이지만, 그러한 숫자가 의미를 올바르게 반영하는가에 유의해야 합니다. origin 특성은 유형들을 숫자로 표현하려고 했는데, 그 과정에서 대소 관계 같은 것이 설정되는 부작용이 있었습니다. 그런 부작용 없이 숫자형으로 표현하는 방법이 필요합니다. 그러한 방법 중 하나는 원-핫-인코딩입니다.
origin 열 값을 원-핫-인코딩으로 변환하겠습니다. DataFrame.pop API로 origin 열을 별도의 변수로 추출합니다. pop을 하면, 원래의 데이터프레임에서 대상 열이 제거됩니다.
pandas.get_dummies() API로 원-핫-인코딩 변환이 수행됩니다.값의 유형 개수에 따라 변환될 벡터의 크기가 결정됩니다. origin 열은 세 가지 유형의 값이 있어서 삼 차원 벡터로 변환됩니다. 원래의 열은 새로 변환된 열들로 대체됩니다. 원래 1이었던 값은 [1, 0, 0], 2는 [0, 1, 0], 3은 [0, 0, 1]로 변환됩니다.
새로운 벡터의 각 차원이 어떤 값에 대응하지 좀 더 용이하게 살펴보기 위해서 지역의 명칭을 열 제목으로 설정하겠습니다.
그런 다음 원래의 데이터프레임과 합칩니다.
이제 origin 열 대신 원-핫-인코딩 변환된 세 개의 열이 지역 정보로 추가된 것을 확인할 수 있습니다.
X_origin = X_scaled.pop('origin')
X_origin = pd.get_dummies(X_origin)
X_origin.columns = ['US', 'Europe', 'Japan']
X_onehot = pd.concat([X_scaled, X_origin], axis=1)
X_onehot이렇게 변환된 값을 가지고서 다시 알고리즘을 훈련하고 평가해 보겠습니다.
그 결과 훈련과 시험 점수가 약간 향상되는 것을 확인할 수 있습니다. 유의미한 정도라고 보기는 조금 어렵지만 어쨌든 지금까지 중에서는 가장 높은 수치입니다.
linreg = LinearRegression()
_ = 모델평가(linreg, X_onehot, y, print_scores=True, random_state=0)훈련: 0.823, 시험: 0.824
가중치 값도 그래프로 살펴보겠습니다.
지역별로 특성 값이 따로 생겼기 때문에 해석이 훨씬 용이합니다. 이제는 각 지역별로 가중치가 할당됩니다. 지역이 미국인 경우 음수이고, 다른 지역은 양수 값입니다. 미국 지역에서 생산된 차는 연비가 안 좋을 것이라는 인상을 알고리즘도 갖게 되었다고 평가할 수 있습니다. 분석은 보다 용이해 졌지만 성능에 미치는 영향은 그렇게 크지는 않았습니다. 그 이유는 제조된 지역만으로 연비를 예측하는 것은 상당한 한계가 있기 때문입니다. 하지만 올바르지 않은 표현에서는 성능이 감소하는 경우가 있다는 점을 염두에 둔다면 표현으로 인해 모델 형성이 잘못되는 경우를 방지한다고 평가할 수 있습니다. 만약 이런 값이 예측에서 보다 더 많은 기여를 하는 경우라면 표현의 형태가 성능에 많은 영향을 줄 가능성도 있습니다.
pd.Series(linreg.coef_, index=X_onehot.columns).plot(kind='barh')<Axes: >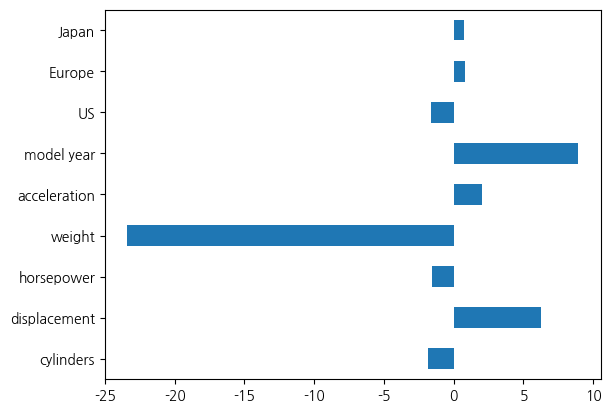
5.3차원 확장¶
성능이 나쁘지는 않지만 그렇다고 아주 좋지도 않습니다. 훈련 점수가 80점 초반이기 때문에 기술적으로 과소적합이라고 할 수 있습니다. 과소적합의 주요 원인 중 하나는 데이터에 비해 너무 단순한 모형입니다. 선형 모델은 특성이 많아질수록 더 복잡한 표현이 가능합니다. 특성을 증가 시키는 것은 차원 확장 입니다. 차원 확장 방법은 크게 두 가지 인데, 더 많은 특성을 수집하거나 아니면 특성 공학을 활용하는 것입니다. 수집은 무엇을 어떻게 왜 수집해야 하는지 전문적인 판단이 필요하고, 경우에 따라서는 추가 수집이 어렵거나 불가능할 수도 있습니다. 만약 과거 시점의 데이터라면 다시 시간을 돌아가서 수집할 수는 없기 때문입니다. 새로운 특성 수집이 어려운 경우라면, 산술 연산을 활용한 특성 공학을 활용하는 것을 고려할 수 있습니다. 선형 모델의 표현력 예시에서, 기존 특성을 제곱하여 새로운 특성으로 함으로써 포물선형으로 분포된 데이터에 대해서 보다 성공적으로 모형을 구성한 경우가 특성 공학을 통해 차원 확장을 활용한 경우입니다.
지금의 경우도 7,80년대 자동차에 대해서 추가적인 특성을 수집하는 것은 어려울 것 같습니다. 그래서 특성공학을 통해서 성능 향상을 위해 노력해 보겠습니다.
원래 디자인 행렬의 값을 제곱하고, 이것을 X2라고 하겠습니다.
원래 특성과 구분하기 위해 제곱한 특성 명칭도 적절한 표기를 하겠습니다.
직전에 원-핫 인코딩까지 마친 데이터를 합쳐서 차원 확장된 입력을 생성합니다.
특성 공학으로 확장된 디자인 행렬은 XX 라고 부르겠습니다. 결과적으로 형성된 데이터 프레임은 기존의 9개 특성에, 제곱한 여섯 개의 특성이 추가되어 총 15차원의 디자인 행렬이 됩니다.
X2 = X_scaled ** 2
X2 = X2.rename(columns=lambda name: f'{name}^2')
XX = pd.concat([X_onehot, X2], axis=1)
XX[:3]특성 공학으로 확장된 입력을 활용해서 모델을 평가해 보겠습니다.
훈련과 시험점수 모두 3, 4퍼센트 정도 점수가 향상됩니다. 이제까지 최고 기록을 경신 합니다.
linreg = LinearRegression()
_ = 모델평가(linreg, XX, y, print_scores=True, random_state=0)훈련: 0.880, 시험: 0.871
가중치도 살펴보겠습니다.
원래의 특성들에 특성 공학으로 추가된 특성에 대해서도 가중치가 부여됩니다. 그런데 특성 공학으로 추가된 것들은 원래와 의미가 달라지기 때문에 예전처럼 그 의미를 이해하는 것은 쉽지 않습니다. 한 가지 눈에 띄는 점은, 이전에 원래의 특성들만으로 모델을 훈련했을 때 배기량과 마력 등이 연비와 양의 상관관계가 있어서 의아했는데, 지금은 탐색적 데이터 분석 수행 결과에서 얻은 상관관계 지표와 가중치 값이 상당히 비슷한 양상을 보이고 있습니다. 엔진 기통 수에 대해서는 조금 다르긴 한데, 아마도 이것은 일본의 3기통의 연비가 4기통보다 오히려 안 좋으니까 그런 측면에서 모형의 구성될 때 선형적인 관계가 아니어서 그렇지 않을까 추측합니다. 현재 가중치는 적어도 원래 특성과 대응되는 부분에 있어서는 예전보다는 좀 더 신뢰할 수 있습니다. 왜냐하면 예전보다 성능이 많이 좋아졌기 때문입니다. 이제는 훈련 시험 점수 모두 80 점대 후반으로 구십점에 가깝습니다.
pd.Series(linreg.coef_, index=XX.columns).plot(kind='barh', figsize=(10, 8))<Axes: >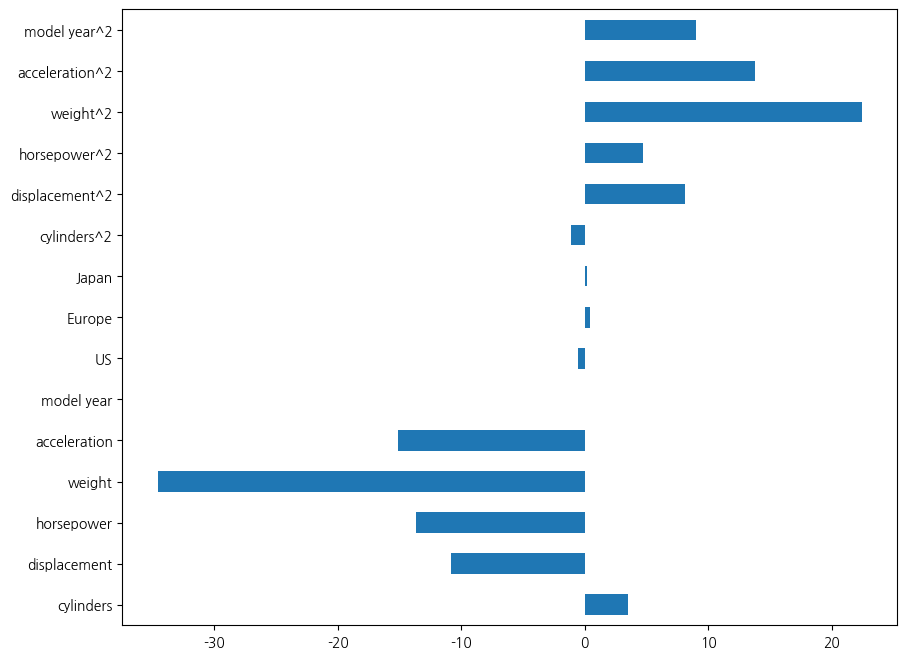
차원 확장을 통해서 선형 모델의 표현력을 증가시킬 수 있었고 그것을 활용해서 현재 연비 데이터셋에 대한 성능을 끌어올리고 있습니다. 그런데 이런 방식이 언제까지 효과적일까요? 3차수 또는 4차수 에서도계속 성능이 좋아질까요?
이번에는 세제곱 한 것을 특성으로 추가해 보겠습니다. 단위 정규화된 원래 값을 세제곱하여 X3으로 하겠습니다.
열 제목도 변경을 반영합니다.
제곱한 특성을 추가한 XX에 X3까지 추가하여 XXX 데이터프레임을 구성합니다.
이제 21 개의 특성, 21차원이 되었습니다.
X3 = X_scaled ** 3
X3 = X3.rename(columns=lambda name: f'{name}^3')
XXX = pd.concat([XX, X3], axis=1)
XXX[:3]추가된 특성에 대해 모델을 훈련하고 평가해 보겠습니다.
훈련 점수 0.9가 됩니다. 훈련 점수만 보면 특성을 더 추가한 것이 이익이 있습니다. 그런데 이런 이익은 시험 점수에는 없습니다. 오히려 시험 점수는 근소하게 감소했습니다. 그렇기 때문에 계속해서 더 복잡한 모델을 무조건 추구하는 것은 바람직하지 않습니다. 왜냐하면 모델의 표현력이 증가할수록 훈련 점수는 대체로 증가하는데, 모형이 복잡해질수록 일반화 성능은 좋지 않을 가능성이 점차 높아집니다.
linreg = LinearRegression()
_ = 모델평가(linreg, XXX, y, print_scores=True, random_state=0)훈련: 0.900, 시험: 0.869
6알고리즘 비교¶
같은 자동차 연비 데이터에 여러 회귀 알고리즘을 적용해 비교해 보겠습니다. 단위에 민감한 선형 모델과 kNN은 단위 변환을 함께 묶어 평가합니다.
from sklearn.linear_model import Ridge
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
모델들 = {
'선형(릿지)': make_pipeline(StandardScaler(), Ridge()),
'kNN': make_pipeline(StandardScaler(), KNeighborsRegressor()),
'랜덤 포레스트': RandomForestRegressor(random_state=0),
}
점수 = {이름: 모델평가(model, X, y, random_state=0) for 이름, model in 모델들.items()}
pd.DataFrame(점수).T.round(3)