신경망
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt1XOR¶
Xs = np.array([(0, 0), (0, 1), (1, 0), (1, 1)])
y_or = np.array([0, 1, 1, 1])
y_xor = np.array([0, 1, 1, 0])
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.title('OR')
plt.scatter(Xs[:, 0], Xs[:, 1], c=y_or, cmap='bwr')
plt.axline((0, 0.75), slope=-1, color='black', linestyle='--')
plt.subplot(1, 2, 2)
plt.title('XOR')
plt.scatter(Xs[:, 0], Xs[:, 1], c=y_xor, cmap='bwr')
plt.axline((0, 0.75), slope=-1, color='black', linestyle='--')
plt.show()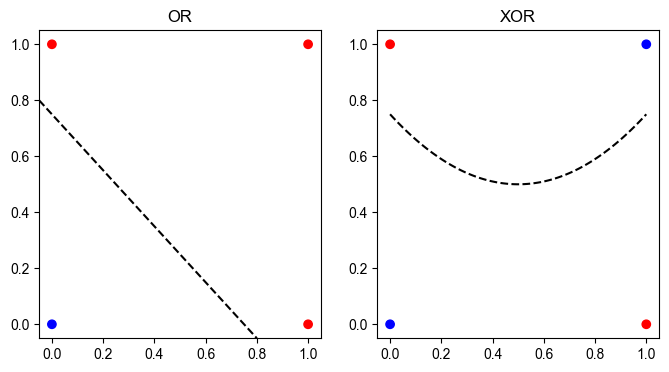
XOR의 진리표는 두 입력 중 어느 한쪽만 1일 때 출력이 1이 되고, 나머지 경우에는 0이 됩니다. 이러한 성질 때문에 배타적 논리합이라고 부릅니다. 진리표를 좌표 평면에 나타내면 위 그림의 오른쪽처럼 직선 하나로는 두 부류를 나눌 수 없는 비선형 분포가 됩니다. 단층 퍼셉트론은 선형 모델이므로 이 분포를 분리하지 못합니다.
XOR은 은닉층을 하나 갖는 2층 신경망으로 극복할 수 있습니다. 이때 은닉층의 활성화 함수로는 비선형 함수인 계단 함수를 사용하고, 출력은 0 또는 1로 둡니다. 이진 분류이므로 출력층은 하나의 노드만으로도 표현할 수 있습니다.
은닉층이 NAND와 OR로 동작하는 퍼셉트론으로 구성되면, 원래의 입력 는 새로운 분포 로 변환됩니다. 에 대한 출력 의 분포는 비선형이지만, 변환된 에 대한 의 분포는 선형이 됩니다. 그래서 마지막 출력층에서는 AND와 같은 단일 퍼셉트론만으로도 문제를 처리할 수 있습니다. 즉, 신경망의 은닉층은 일련의 비선형 변환을 거쳐, 출력층의 선형 모델이 다룰 수 있는 형태로 데이터를 바꾸어 문제를 해결합니다.
신경망은 입력과 출력 사이에 한 개 이상의 은닉층을 두어 입력과 출력을 간접적으로 연결합니다. 모든 입력이 모든 은닉 뉴런에 연결됩니다.
2은닉층 비선형 활성화¶
신경망의 각 노드는 퍼셉트론입니다. 여러 개의 퍼셉트론을 다층으로 쌓아 올린 구조이지만, 퍼셉트론 자체는 기본 단위로 그대로 사용됩니다. 퍼셉트론에서 출력을 결정하는 활성화 함수는 그 출력이 어디에 쓰이는지에 따라 다르게 적용합니다. 신경망에서는 은닉층의 활성화 함수로 반드시 비선형 함수를 사용해야 합니다. 은닉층 각 노드의 출력은 최종 출력과 구별해 활성화값이라고 부릅니다.
비선형이면서 계단 함수의 단점을 극복한 시그모이드는 2010년 무렵까지 신경망 은닉층의 기본 활성화 함수로 쓰여 왔습니다. 시그모이드는 1960년대 로지스틱 회귀의 활성화 함수로 채택된 이후 널리 활용되어 왔으며, 계단 함수의 단점은 이미 1960년대 선형 모델에서 논의되었습니다. 시그모이드는 학습 매개변수가 변함에 따라 출력이 연속적으로 변하므로, 그 변화의 효과를 평가해 매개변수 갱신에 활용할 수 있습니다.
def step(x):
return np.where(x > 0, 1, -1)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.where(x > 0, x, 0)x = np.arange(-5, 5, 0.1)
fig, subplots = plt.subplots(1, 3, figsize=(10, 3))
subplots[0].plot(x, step(x))
subplots[1].plot(x, sigmoid(x))
subplots[2].plot(x, relu(x))
plt.show()2.1활성화 함수는 왜 비선형이어야 하는가¶
은닉층의 활성화 함수는 반드시 비선형이어야 합니다. 만약 은닉층 활성화 함수를 선형 함수로 두면, 여러 층을 쌓아 올린 이점이 사라집니다. 여러 층을 구성하는 이유는 비선형성을 다루기 위함인데, 선형 함수로 활성화하면 층을 아무리 쌓아도 결국 하나의 퍼셉트론과 같아지기 때문입니다.
두 개의 층으로 이루어진 신경망을 생각해 봅시다. 첫 번째 층은 은닉층, 두 번째 층은 출력층이고, 각 층이 입력을 처리하는 함수를 , 라고 하겠습니다. 첫 번째 층은 입력 를 받아 를 출력하고, 이것이 다음 층의 입력이 되어 가 됩니다. 이때 은닉층 활성화 함수를 가장 단순한 선형 함수인 항등 함수로 두면, 각 층의 활성화값은 가중치와의 내적 결과 가 그대로 전달됩니다. 그러면 여러 층을 거쳐도 전체 식은 단일 퍼셉트론과 같아지고, 이는 선형 모델이므로 비선형 문제를 풀 수 없습니다.
데이터의 분포가 비선형이므로 그에 맞는 비선형 표현이 필요하고, 여러 층의 구성으로 그러한 표현을 만들 수 있습니다. 그러나 애써 여러 층을 만들어도 선형 함수로 활성화하면 그 효과가 완전히 상쇄됩니다.
이는 요리에 비유할 수 있습니다. 선형 함수만 활성화에 쓸 수 있는 상황은, 요리할 때 칼만 쓸 수 있는 것과 같습니다. 칼의 모양과 크기는 달라도 써는 동작만 가능하므로 재료의 근본 성질은 바꾸지 못하고, 만들 수 있는 요리는 샐러드나 회 정도로 제한됩니다. 재료의 성질을 바꾸려면 굽기, 끓이기, 튀기기처럼 열을 가해야 합니다. 열을 가하는 것은 재료의 상태를 완전히 변화시키므로 비선형 변환에 해당합니다.
계단 함수의 문제점
from matplotlib.image import imread
모찌 = imread('../data/mozzi.jpg')
픽셀모찌 = np.where(모찌 > 127, 255, 0)
fig, subplots = plt.subplots(1, 2)
subplots[0].imshow(모찌)
subplots[1].imshow(픽셀모찌)
plt.show()2.2ReLU¶
학계의 시간으로는 비교적 최근인 2011년 무렵까지도 1960년대부터 쓰이던 시그모이드가 은닉층 활성화의 기본이었습니다. 이후에는 ‘선형 정류’ 정도로 옮길 수 있는 Rectified Linear Unit, 줄여서 ReLU(렐루)가 시그모이드를 대체하고 있습니다. ReLU는 입력이 양수이면 항등 함수와 같아 최적화 연산에 훨씬 유리합니다. 완전한 항등 함수는 비선형이 아니지만, 양수가 아닌 입력을 모두 0으로 보내는 ReLU는 비선형 함수이므로 은닉층의 활성화 함수가 될 수 있습니다.
ReLU가 등장한 과정은 흥미롭습니다. 인공지능의 발전은 신경생물학의 발견에서 많은 통찰을 얻어 왔습니다. 생물학적 뉴런을 관찰하면 특정 입력에 대해서는 완전히 비활성화되는 것으로 보고되었는데, 이러한 성질을 ReLU와 같은 수학 모델로 옮겨 은닉층을 활성화했을 때 더 좋은 결과를 얻는 경우가 많았습니다. 이에 고무된 여러 연구가 이어졌고, 그 결과 ReLU는 2011년 이후 시그모이드를 대체하는 기본 은닉층 활성화 함수가 되었습니다.
3순전파¶
신경망은 입력과 출력 사이에 한 개 이상의 은닉층을 둡니다. 그래서 입력으로부터 출력이 만들어지는 과정은 여러 계층을 거쳐 값이 차례로 전달되는 방식이며, 이를 순전파라고 합니다. 각 계층의 출력은 다음 계층의 입력이 되고, 마지막 계층을 출력층이라고 합니다.
입력이 모든 출력 뉴런에 동시에 전달되는 구성을 완전 연결이라고 합니다. 모든 입력이 모든 출력에 연결되기 때문입니다. 복잡해 보이지만 개별 뉴런의 출력은 퍼셉트론과 동일합니다. 입력에 대응하는 가중치가 있어 입력에 가중치를 곱하고 편향을 더해 취합하며, 편향은 뉴런마다 하나씩 있습니다. 각 뉴런의 출력은 여전히 입력 벡터와 가중치의 내적입니다.
한 계층에 속한 모든 뉴런의 가중치를 하나의 행렬로 표현하면, 입력과 가중치 행렬의 내적만으로 그 계층 모든 뉴런의 값을 한 번에 취합할 수 있고, 편향은 그 결과에 더해 주면 됩니다. 즉, 단일 퍼셉트론의 출력을 구하는 것과 거의 같은 방식으로 완전 연결 계층의 출력을 계산할 수 있습니다.
은닉층의 출력은 비선형 활성화 함수를 거쳐 다음 계층으로 전달됩니다. 이 중간 출력을 최종 출력과 구별해 활성화값이라고 합니다. 활성화값은 다시 다음 계층의 입력이 되며, 이런 식으로 각 계층의 출력이 파도처럼 최종 출력을 향해 전달되는 과정이 순전파입니다.
순전파에서는 각 계층의 출력이 다음 계층의 입력이 되어 값이 차례로 전달됩니다. 모든 입력이 모든 출력 뉴런에 연결되는 구성을 완전 연결이라고 합니다.
sigmoid = lambda x: 1 / (1 + np.exp(-x))
x = np.array([1.0, 0.5])
W1 = np.random.randn(2, 3)
b1 = np.random.randn(3)
z1 = np.dot(x, W1) + b1
h1 = sigmoid(z1)
W2 = np.random.randn(3, 2)
b2 = np.random.randn(2)
z2 = np.dot(h1, W2) + b2
h2 = sigmoid(z2)
W3 = np.random.randn(2, 2)
b3 = np.random.randn(2)
z3 = np.dot(h2, W3) + b3
z3신경망을 어떻게 구성하느냐에 따라 각 계층의 가중치 형상이 결정됩니다. 위 예시를 살펴보겠습니다. 첫 번째 층은 두 개의 입력이 세 개의 출력에 연결된 완전 연결 계층이므로 가중치 형상은 이고, 편향은 출력 뉴런 수만큼 3개입니다. 2차원 특징을 갖는 개의 표본이 입력되면 첫 번째 은닉층의 출력 형상은 이 됩니다. 편향은 더해지는 연산이라 형상을 바꾸지 않고, 활성화 함수는 원소별로 적용되므로 역시 형상에 영향을 주지 않습니다.
두 번째 은닉층은 이전 계층의 출력을 입력으로 받습니다. 입력이 3개, 출력이 2개이므로 가중치 형상은 이고 편향은 2개입니다. 입력을 가중치와 내적하면 가 되고, 편향이 더해진 뒤 활성화 함수를 거칩니다.
세 번째 층은 출력층입니다. 입력 2개, 출력 2개이므로 가중치 형상은 , 편향은 2개입니다. 이전 계층에서 가 전달되면 최종적으로 형상의 출력이 발생합니다. 즉, 각 표본마다 두 개씩 출력이 만들어집니다.
위 예시의 신경망 구성. 각 계층의 입력과 출력 수에 따라 가중치 형상이 결정됩니다.
class 완전연결:
def __init__(self, 입력, 출력, 활성화=None):
self.W = np.random.randn(입력, 출력)
self.b = np.zeros(출력)
self.activation = 활성화
def forward(self, X):
Z = np.dot(X, self.W) + self.b
if self.activation:
return self.activation(Z)
return Z
class 신경망:
def __init__(self):
self.layers = []
def add(self, layer):
self.layers.append(layer)
def predict(self, X):
"""순전파 (feedforward)"""
output = X
for layer in self.layers:
output = layer.forward(output)
return output
def fit(self, X, y):
"""학습"""
raise NotImplementedError4비선형 극복¶
데이터 변환
알고리즘
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor
random = np.random.RandomState(123)
xs = np.arange(-5, 5, 0.1)
noise = random.randn(len(xs))
ys = xs ** 2 + noise
Xs = xs.reshape(-1, 1)
# 차원 확장
XX = np.hstack([Xs, Xs ** 2])
print(Xs.shape, '->', XX.shape)
model = LinearRegression()
model.fit(XX, ys)
print(f'y = {model.coef_[1]:.2f}x^2 + {model.coef_[0]:.2f}x + {model.intercept_:.2f}')
# 비선형 커널 (SVM): 2010년 이전까지 가장 인기있는 방법론 중에 하나였습니다
svm = SVR(kernel='poly', degree=2, C=1.0)
# 차원 확장 된 것이 아닌 기존의 1차원 데이터셋으로 훈련시킵니다.
# 비선형 커널을 통해 내부적으로 차원 확장 효과를 스스로 내는 방식입니다
svm.fit(Xs, ys)
# 신경망: 2010년 이후에는 비선형을 극복하는 가장 효과적인 방법으로 다시 주목 받고 있습니다.
mlp = MLPRegressor(
hidden_layer_sizes=[128,], activation='tanh',
learning_rate_init=0.1, random_state=0)
mlp.fit(Xs, ys)
plt.scatter(xs, ys)
plt.scatter(xs, ys, marker='+')
plt.plot(xs, ys - noise, 'r--')
# 선형 모형
plt.plot(xs, model.predict(XX), 'k', label='linear')
# SVM
plt.plot(xs, svm.predict(Xs), 'm', label='svm')
# 신경망
plt.plot(xs, mlp.predict(Xs), 'g', label='MLP')
plt.legend()
plt.show()5출력 처리¶
신경망은 분류와 회귀에 모두 사용할 수 있습니다. 회귀에서는 출력층의 뉴런을 하나로 둡니다. 분류에서는 출력층 뉴런을 분류 유형의 개수만큼 둡니다. 예를 들어 이진 분류는 두 개, 0부터 9까지 열 개의 숫자 중 하나를 예측하는 문제는 열 개로 설정합니다.
회귀 출력의 활성화 함수는 항등 함수입니다. 항등 함수는 입력값을 그대로 출력하므로, 별도의 처리 없이 출력값을 그대로 사용합니다.
분류 출력은 각 출력이 확률적 자신감으로 표현되어야 합니다. 이를 위해 분류 출력의 활성화 단계에서는 소프트맥스 함수를 사용합니다.
def softmax(z):
exp_z = np.exp(z - np.max(z))
y = exp_z / np.sum(exp_z)
return y
y = softmax(z3)
print(f'y: {y}, 합계: {np.sum(y):.3f}')6손글씨 숫자 데이터셋¶
여러 기계학습 기법을 비교하려면 기준이 되는 데이터셋이 필요합니다. MNIST는 손글씨 숫자 이미지의 모음으로, 0부터 9까지 여러 사람의 손글씨를 모은 것입니다. 훈련 이미지 6만 장과 시험 이미지 1만 장을 제공하며, 지도학습을 위해 각 이미지의 레이블도 함께 제공합니다. 훈련 데이터와 시험 데이터가 미리 나뉘어 제공되므로, 같은 훈련 데이터로 서로 다른 모델을 학습하고 같은 시험 데이터로 평가해 결과를 비교할 수 있습니다.
각 이미지는 의 회색조 이미지입니다. 흑백 이미지는 색상 채널이 하나이고 천연색 이미지는 R, G, B처럼 세 개 이상의 채널로 구성되므로, 각 이미지 데이터는 형상의 3차원 텐서입니다. 각 픽셀은 0부터 255 범위의 정수로 픽셀 강도를 나타냅니다. 음수가 없고 이라 0부터 255 범위를 8비트로 표현할 수 있으므로, 자료형은 부호 없는 8비트 정수(unsigned int 8비트)입니다.
import pickle
with open('../data/mnist/mnist_ndarray.pkl', 'rb') as f:
(X_train, y_train), (X_test, y_test) = pickle.load(f)6.1데이터 전처리¶
기계학습 모델에 데이터를 제공할 때는 일련의 전처리가 필요할 수 있습니다. 모델에 넣기 전에 데이터를 어떤 형태로든 가공하는 작업을 통칭해 전처리라고 하며, 전처리는 여러 단계로 이루어질 수 있습니다.
지금 구성하려는 신경망은 1차원 형상의 특징 벡터를 입력으로 기대합니다. 그런데 데이터셋의 각 표본은 의 3차원 텐서입니다. 모델의 입력이 되려면 먼저 형상을 조정해야 합니다. 각 픽셀 행을 일렬로 나열하면 개의 픽셀로 이루어진 벡터가 됩니다. 따라서 형상을 1차원으로 조정하면 신경망의 입력은 784로 설정됩니다.
이때 각 표본의 형상만 1차원으로 바꾸는 것이지, 데이터 전체를 1차원으로 펴는 것이 아님에 유의합니다. 원래 형상이 의 4차원 텐서라면, 조정 후에는 의 2차원 텐서가 되어야 합니다.
형상 조정은 필수 과정입니다. 그밖에 선택적이지만 권장되는 전처리도 있습니다. 퍼셉트론 기반 모델은 대체로 입력 벡터의 크기가 작은 편이 바람직하며, 신경망도 퍼셉트론 기반 모델입니다. 그래서 값들 사이의 상대적 차이는 보존하면서 크기만 작게 만드는 단위 조정을 종종 수행합니다. 원래 픽셀값은 0부터 255 범위이므로, 가능한 최대값인 255로 각 값을 나누면 범위가 0부터 1 사이로 줄어듭니다. 음수가 없으므로 이렇게 하면 픽셀 사이의 상대적 차이를 유지하면서도 훨씬 작은 범위의 값으로 바꿀 수 있습니다. 이러한 단위 조정을 정규화라고 부르며, 여기서 적용한 방식은 결과를 0과 1 사이로 만드는 최대최소 정규화입니다.
6.2분류 출력 인코딩¶
분류 출력은 범주형 변수이며, 기계학습에서 범주형 변수는 보통 원-핫 인코딩으로 변환합니다. 정답 가 분류 출력 신경망에서 쓰이려면 원-핫 인코딩이 필요합니다. 0부터 9까지 중 정답이 0이라면, 원-핫 인코딩을 거쳐 10차원 벡터로 표현되는데 0에 해당하는 첫 번째 값만 1이고 나머지는 모두 0으로 채워집니다. 하나만 1이고 나머지는 0이라는 점에서 '원-핫’이라는 이름이 붙었습니다.
원-핫 인코딩의 의미는 분류 출력의 예측 확률 관점에서 살펴볼 수 있습니다. 정답은 모호함이 없으므로 정답에 대응하는 값의 자신감이 100%입니다. 예측 확률의 합은 1이므로 어느 하나가 100%라면 나머지는 모두 0입니다.
모델의 예측이 완벽하지 않은 경우와 비교해 보겠습니다. 정답에 대응하는 값의 자신감이 70%라면, 합이 1이면서 그보다 큰 값은 있을 수 없으므로 완벽하지는 않아도 결과적으로 정답을 맞힙니다. 반면 정답에 대응하는 값의 예측 확률이 40%라면, 합 1의 범위 안에서 더 큰 값이 존재할 수 있고, 그런 값이 있으면 정답과 다른 답을 내놓게 됩니다. 이처럼 정답을 확률적 자신감의 관점에서 보면, 출력을 원-핫 인코딩으로 변환하는 일의 의미를 더 잘 이해할 수 있습니다.
def preprocess(X, y=None):
X = X.astype('float32') / 255
X = X.reshape(-1, 28 * 28)
if y is None:
return X
Y = np.eye(10)[y]
return X, Y
def evaluate(model, X, y):
Y_pred = model.predict(preprocess(X))
y_pred = np.argmax(Y_pred, axis=1)
accuracy = np.mean(y == y_pred)
print(f'정확도: {accuracy:.3f}')
return accuracy
layer1 = 완전연결(784, 50, sigmoid)
layer2 = 완전연결(50, 100, sigmoid)
layer3 = 완전연결(100, 10)
model = 신경망()
model.add(layer1)
model.add(layer2)
model.add(layer3)
evaluate(model, X_test, y_test)6.3신경망 구성 예시¶
신경망에서 입력과 출력은 데이터셋으로 결정됩니다. 각 표본 이미지는 원래 의 3차원 텐서이지만, 완전 연결 계층의 입력이 되려면 1차원 벡터여야 하므로 784차원 벡터가 됩니다. 따라서 첫 번째 층의 입력은 784로 정해집니다. 0부터 9까지 중 하나를 예측하는 분류 문제이므로 출력층은 열 개의 뉴런이 필요합니다.
입력과 출력 사이의 은닉층 구성에는 정해진 방법이 없습니다. 대체로 경험적, 실험적으로 구성하면서 평가하고 조정해 나갑니다. 여기서는 두 개의 은닉층을 사용하되 1층은 50개, 2층은 100개의 출력을 내도록 했습니다. 이 깊이와 뉴런 수에 특별한 공식이 있는 것은 아니며 임의로 정한 값입니다.
그 결과 1층의 가중치 형상은 , 편향은 50개, 2층은 에 편향 100개, 출력층은 에 편향 10개가 됩니다. 입력에 각 계층의 가중치와 편향이 반영되며 출력까지 순전파가 진행되고, 각 은닉층의 출력은 시그모이드와 같은 비선형 활성화 함수를 거쳐 다음 층으로 전달됩니다. 마지막 출력층은 완전 연결 계층이지만 분류 출력이므로 활성화 함수는 소프트맥스여야 합니다. 그 결과 최종 출력은 0부터 9까지에 대한 확률적 자신감이 되며, 성능을 측정하려면 각 표본의 예측값 중 가장 큰 값을 내는 레이블로 변환해 정답과 비교합니다.
학습된 가중치 적재
import pickle
with open('../data/mnist/mnist_weight.pkl', 'rb') as 파일:
params = pickle.load(파일)
for layer, (W, b) in zip(model.layers, params):
layer.W = W
layer.b = b
evaluate(model, X_test, y_test)7신경망 설계¶
신경망은 다른 기계학습 모델과 달리 은닉층을 직접 구성해야 합니다. 이 작업을 신경망 설계라고 합니다. 다른 모델은 대체로 하이퍼파라미터 튜닝으로 표현력을 조절하지만, 신경망은 은닉층의 구성이 큰 틀에서 표현력을 결정합니다. 계층을 추가하는 일은 한층 고도한 작업이라 튜닝보다는 설계라고 부릅니다. 은닉층 뉴런의 개수와 이들이 연결되는 방식이 주요 고려 사항입니다.
은닉층의 뉴런을 늘리면 표현력이 풍부해집니다. 사실 은닉층 하나만으로도 뉴런을 충분히 늘리면 어떤 데이터든 완전하게 표현할 수 있어, 훈련 데이터에 대해서는 100% 성능을 낼 수 있습니다. 그러나 기계학습에서는 훈련 데이터의 최적화뿐 아니라 새로운 데이터에 대한 일반화 성능도 그에 못지않게 중요합니다. 단일 은닉층에 많은 뉴런을 쓰면 훈련 데이터에 과적합되어 일반화가 나빠지기 쉽습니다.
이 문제는 은닉층을 더 쌓아 깊은 모델을 만드는 방식으로 풀어 갑니다. 깊은 모델은 각 은닉층의 뉴런 수가 비교적 적어도 복잡한 함수를 표현할 수 있습니다. 하나의 함수로 데이터를 한 번에 모델링하기보다, 전문화된 여러 표현을 찾아 조합하는 셈입니다. 전체적으로는 더 적은 학습 매개변수를 쓰므로 일반화 성능이 향상되지만, 계층이 많아지면 최적화는 더 어려워집니다. 그래서 신경망 설계는 최적화와 일반화의 균형점을 찾아 은닉층의 뉴런 수와 계층 수를 정하는 과정이며, 이는 실험적으로 여러 구성을 살펴보는 수밖에 없습니다.
7.1은닉층 뉴런 수와 표현력¶
은닉층의 뉴런을 늘리면 표현력이 풍부해지는 관계는 손가락에 비유해 볼 수 있습니다. 우리 한 손에는 다섯 손가락이 있습니다. 집게발 정도로는 표현력이 부족해 진화 과정에서 손가락이 하나씩 늘었을 것입니다. 그런데 손가락이 많을수록 유리하다면 왜 여섯, 일곱 개가 되지 않았을까요. 두세 개보다 다섯 개가 대부분의 사물을 다루는 데 유리하지만, 여섯 개 이상은 사물 조작에서 다섯 개에 비해 큰 이점이 없기 때문입니다. 오히려 손가락이 늘면 골격 구조가 복잡해지고 제어에 필요한 두뇌 자원도 늘어나 진화적으로 불리합니다.
은닉층 뉴런 수를 정하는 문제도 이와 비슷합니다. 뉴런을 늘려 가면 훈련 데이터에 대해서는 언젠가 만점을 받지만, 지나치게 복잡한 모델은 훈련 데이터와 조금만 달라진 새로운 데이터에는 제대로 적응하지 못합니다. 그래서 무작정 뉴런을 추가하는 것은 해법이 될 수 없습니다.
7.2전역 근사 이론 (1989)¶
신경망의 목표는 어떤 입력 에 대해 출력 를 내는 임의의 함수 표현을 찾아내는 것, 즉 입력의 특징을 출력으로 매핑하는 함수를 만드는 학습 매개변수를 찾는 것이라고 할 수 있습니다. 1989년 전역 근사 이론(universal approximation theorem)은, 적어도 하나의 은닉층을 두고 각 은닉층을 시그모이드 같은 비선형 함수로 활성화하면 보렐 측정 가능한 어떤 함수 표현도 찾아낼 수 있음을 보였습니다. 보렐 측정 가능 함수는 실수 공간에서 닫힌 연속 함수 정도로 이해하면 됩니다. 정리하면, 신경망의 구성은 어떤 입력과 출력도 매핑할 수 있는 잠재력을 지닙니다.
다만 이 이론은 그러한 잠재적 구성이 존재한다는 것만 보였을 뿐, 그 구성이 얼마나 큰 규모여야 하는지는 다루지 않았습니다.
7.3계층의 의미¶
정보가 복잡할수록 단계별로 정보를 취합하고 추상화하는 계층이 필요해집니다. 기업과 같은 조직은 지능적인 정보 처리 기관이라고 할 수 있습니다. 서로 다른 조직은 목표와 기능이 제각각이지만 한 가지 공통점이 있는데, 바로 계층적인 구조를 갖는다는 점입니다.
고객과 제품의 유형이 광범위하고 다양하면 여러 문제에 대한 정보 수집과 의사결정이 필요합니다. 이때 적절한 계층을 두어야 각 계층에서 처리된 정보가 정리, 요약되어 다음 계층으로 전달됩니다. 문제가 복잡해질 때 계층을 도입하지 않고 사람만 늘리면, 각자 성실히 일해도 그 업무를 전체적으로 취합하고 조정하기 어려워 조직 전체의 의사결정이 매우 힘들어집니다. 반대로 고객과 제품의 유형이 적으면 계층이 많이 필요하지 않고, 오히려 계층이 많으면 의사결정에 방해가 될 수 있습니다. 즉, 계층은 무조건 깊다고 좋은 것이 아니라 문제의 복잡도에 맞게 설정되어야 합니다. 신경망의 계층 구성도 이에 비유할 수 있습니다.
계층은 무조건 깊다고 좋은 것이 아니라 문제의 복잡도에 맞게 설정되어야 합니다. 얕은 계층과 깊은 계층의 대비.
7.4인지와 추상화¶
시각 자극을 추상적 개념으로 인지하는 과정도 여러 단계를 거치는 것으로 알려져 있습니다. 예를 들어 강아지를 보면, 강아지에서 반사된 빛이 먼저 망막을 자극합니다. 망막의 각 세포는 빛의 강도에 따른 자극의 정도를 전달하는데, 이는 이미지의 픽셀과 비슷합니다. 픽셀 정보만으로 곧바로 인지가 이루어지지는 않습니다. 픽셀들은 다음 단계로 전달되어 적절한 정보로 추출되고, 그 과정에서 대상의 형태가 배경으로부터 분리되어 결국 추상적 개념의 인지로 이어집니다. 추상화란 주요한 정보를 선택하고 불필요한 정보를 제거하며 적절한 표현을 고르는 과정이라고 할 수 있습니다.
추상적 개념의 구체적 사례들은 서로 비슷하지만 모두 다릅니다. 같은 개도 순간순간 모습이 다르고, 픽셀 단위로 보면 조금만 움직여도 픽셀들은 크게 달라집니다. 그럼에도 지능적 존재는 개별 픽셀의 차이 속에서 주요한 특징을 추출해 여러 변형 속에서도 대상의 추상적 개념과 연결합니다. 개별 픽셀이 여러 인지 단계를 거치며 인지에 도움이 되는 특징으로 잘 추상화되기 때문입니다.
인지의 가장 마지막에서 우리는 추상적 개념에 도달합니다. '개’라는 개념은 모든 개를 포함하면서도 각각의 개와는 정확히 일치하지 않습니다. 만약 이런 추상적 개념을 형성하지 못한다면, 여러 종류의 개를 공통적으로 인지하지 못해 개를 마주칠 때마다 새로운 존재를 보는 것처럼 느낄 것입니다. 실제로 두뇌의 특정 부위가 손상된 환자 중에는 보는 것과 인지가 연결되지 않는 경우가 있습니다. 환자는 눈앞의 대상을 온전히 그릴 수 있지만 그것이 무엇인지는 알지 못합니다. 개를 볼 수는 있어도 개라고 인지하지 못하고, 사랑하는 사람의 얼굴을 보면서도 누구인지 알아보지 못하기도 합니다. 이는 시각 정보가 들어오는 것은 시작에 불과하며, 일련의 추상화 과정이 제대로 진행되어야 인지에 도달함을 보여 줍니다. 보는 것을 넘어 알아보는 것이 인지입니다.