로지스틱 회귀
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt0.1확률 모델링¶
로지스틱 회귀는 선형 회귀의 출력을 승산률(odd ratio)로 취급하여 확률 모델링을 수행합니다. 두 가지 사건 에 대해 어느 한 쪽의 확률 에 대해, 승산률은 다음과 같습니다.
승산률은 범위의 값이기 때문에 선형 회귀 출력에 대응하기 위해 로그 승산률로 모델링합니다. 로그 승산률은 종종 로짓(logit) 이라고 합니다.
위의 공식을 를 입력으로 하여 에 대해 정리하면 다음과 같습니다.
정리하면, 선형모형의 출력을 위와 같은 방식으로 처리하면 확률값으로 모델링할 수 있습니다. 이러한 함수를 로지스틱 시그모이드(logistic sigmoid), 종종 줄여서 시그모이드 함수라고 합니다.
random = np.random.default_rng(seed=0)
xs = np.linspace(0, 10, 100)
noise = random.normal(0, 1, size=xs.shape)
ys = 1.2 * xs + 3.4 + noise
Xs = np.stack([xs, ys], axis=1)
assert Xs.shape == (len(xs), 2)
labels = np.where(ys > ys - noise, 1, 0)
linear_model = lambda x, w, b: x @ w + b
params = random.normal(size=(3,))
sigmoid = lambda z: 1 / (1 + np.exp(-z))
outputs = linear_model(Xs, b=params[0], w=params[1:])
양성확률 = sigmoid(outputs)
예측 = np.where(양성확률 > 0.5, 1, 0)
정확도 = np.mean(예측 == labels)
print(f'b, w1, w2 = {params.round(3)} -> 정확도: {정확도:.1%}')
display(pd.DataFrame(Xs, columns=['x1', 'x2'])
.assign(정답=labels)
.assign(**{'p(y=1|x)': 양성확률})
.assign(예측=예측)
.head().round(3))
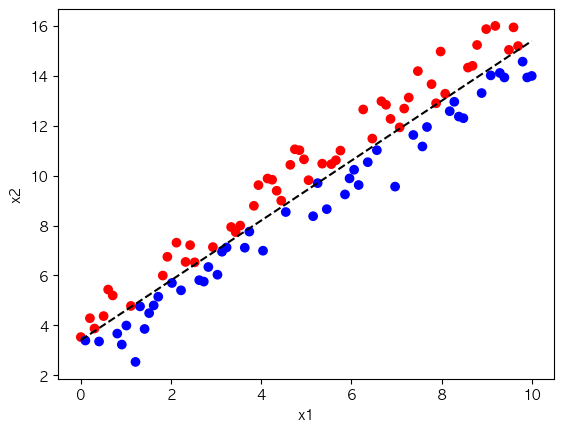
plt.scatter(Xs[:, 0], Xs[:, 1], c=labels, cmap='bwr')
plt.xlabel('x1'); plt.ylabel('x2')
plt.plot(xs, ys - noise, color='black', linestyle='--')
plt.show()b, w1, w2 = [ 0.503 0.99 -0.164] -> 정확도: 51.0%
0.1.1다항 분류¶
다항 분포 인 경우, 각 유형(class)별 선형 출력(logit)을 가정합니다. 일 때, 가중치 , 편향 에 대한 선형 출력은 다음과 같습니다.
다항 분포의 확률은 다음과 같습니다.
사건들의 확률은 다른 확률 분포에 영향을 받기 때문에 어떤 하나의 사건을 기준으로 승산률을 구합니다. 표기의 편의를 위해 마지막 사건 를 기준으로 하면 승산률은 다음과 같이 표기할 수 있습니다. 즉, 어떤 사건 의 승산률은 다음과 같습니다.
승산률을 실수 범위 에 대응하기 위해 로그를 취해 정리합니다.
에 대해 합을 구하면,
이 때, 확률의 합계는 모두 1임으로
에 대해 정리하면,
따라서,
기준 클래스 의 로짓을 0으로 가정하면
이는 기준 출력 일 때, 모든 출력에서 를 빼도, 다음과 같이 확률값은 동일하기 때문에 기준 출력값을 임의적으로 지정할 수 있기 때문입니다. 즉, 확률값은 상수 이동 불변성 (shift invariance)의 성질이 있습니다.
즉, 소프트맥스의 확률값은 로짓의 절대값이 아닌 비율로써 결정됩니다.
따라서, 다항 분류 출력의 로짓은 다음과 같은 소프트맥스(softmax) 함수로 확률 모델링이 가능합니다.
0.2손실 함수¶
출력이 베르누이 분포 이라고 가정한다면, 로지스틱 회귀는 선형 모델의 출력을 시그모이드 로 변환하여 양성 확률을 출력합니다.
따라서,
0.2.1최대우도추정¶
로지스틱 회귀의 손실을 최소화하는 매개변수를 찾기 위해서는 최대우도추정을 할 수 있습니다.
곱은 계산적으로 불안정하므로 로그를 취해 로그 우도를 계산합니다.
여기서 .
최대우도추정은 로그우도를 최대화하는 것이기 때문에 로지스틱 회귀의 손실함수는 음(negative)의 로그우도를 최소화한다고 할 수 있습니다.
1$$ \underset{w}{\arg\max} \log \mathcal{L}(w)¶
2\underset{w}{\arg\min} \mathcal{J}(w)¶
-\sum_{i=1}^{n} \left[ y_i \log p_i + (1-y_i)\log(1-p_i) \right]
$$
따라서, 음의 로그우도는 로지스틱 회귀의 손실함수 크로스엔트로피 손실(Binary Cross-Entropy)입니다.
2.2기울기 유도 (Gradient Derivation)¶
경사 하강법을 적용하기 위해 손실 함수를 매개변수 와 로 미분해야 합니다.
2.2.11. 시그모이드 함수의 미분¶
2.2.22. 손실 함수를 로 미분 (단일 샘플)¶
2.2.33. 연쇄 법칙을 적용하여 계산¶
2.2.44. 가중치와 편향에 대한 기울기¶
단일 샘플에 대해:
전체 배치에 대해:
2.2.55. 매개변수 업데이트 (Gradient Descent)¶
여기서 는 학습률(learning rate)입니다.
def 경사산출(X, y, p):
표본수 = len(y)
경사 = X.T @ (p - y)
return 경사 / 표본수
linear_model = lambda x, w, b: x @ w + b
def 손실산출(y, p):
delta = 1e-7
p = np.clip(p, delta, 1 - delta)
표본수 = len(y)
손실 = - (y * np.log(p ) + (1 - y) * np.log(1 - p)).sum()
return 손실 / 표본수
정확도평가 = lambda labels, z: (np.where(sigmoid(z) > 0.5, 1, 0) == labels).mean()
성능지표 = []
params = random.normal(size=(3,))
z = linear_model(Xs, b=params[0], w=params[1:])
성능지표.append({
'손실': 손실산출(labels, sigmoid(z)),
'정확도': 정확도평가(labels, z)
})
x0 = np.ones((len(Xs), 1))
경사 = [경사산출(np.hstack([x0, Xs]), labels, p=sigmoid(z))]
display(pd.DataFrame(
경사, columns=['dL/db'] + [f'dL/dw{k+1}' for k in range(Xs.shape[1])]).round(3))
# 경사하강
학습률 = 1.0; 학습횟수 = 2000
param_history = [params]
for epoch in range(학습횟수):
z = linear_model(Xs, b=params[0], w=params[1:])
경사 = 경사산출(np.hstack([x0, Xs]), labels, p=sigmoid(z))
params -= 학습률 * 경사
param_history.append(params.copy())
성능지표.append({
'손실': 손실산출(labels, sigmoid(z)),
'정확도': 정확도평가(labels, z)
})
display(
pd.concat([
pd.DataFrame(param_history, columns=['b', 'w1', 'w2']),
pd.DataFrame(성능지표),
], axis=1).round(3)
)2.3¶
2.4Newton 방법 (2차 미분 활용)¶
경사 하강법은 1차 미분(그래디언트)만 사용하지만, Newton 방법은 2차 미분(헤시안)을 활용하여 더 빠른 수렴을 달성합니다.
2.4.1로지스틱 회귀의 헤시안¶
여기서 는 대각 행렬입니다.
2.4.2Newton 업데이트 규칙¶
2.4.3수렴 성능¶
경사 하강법: 선형 수렴 (1차)
Newton 방법: 2차 수렴 (quadratic convergence)
결과: 일반적으로 훨씬 적은 반복 횟수
# Newton 방법 구현 (라인 서치 포함)
def hessian_계산(X, p):
"""
로지스틱 회귀의 헤시안 행렬 계산
H = (1/S) X^T D X, where D = diag(p(1-p))
"""
표본수 = len(p)
weights = p * (1 - p)
weights = np.clip(weights, 1e-10, 1-1e-10) # 수치 안정성
weighted_X = X.T * weights
hessian = weighted_X @ X
return hessian / 표본수
def bce_loss(p, y, eps=1e-12):
p = np.clip(p, eps, 1 - eps)
return -np.mean(y * np.log(p) + (1 - y) * np.log(1 - p))
# Newton 방법 (라인 서치 포함)
params_newton = random.normal(size=(3,))
params_history_newton = [params_newton.copy()]
loss_history_newton = []
x0 = np.ones((len(Xs), 1))
X_aug = np.hstack([x0, Xs])
print("=" * 60)
print("Newton 방법 (2차 미분 + 라인 서치)")
print("=" * 60)
for epoch in range(100):
# 현재 손실 및 그래디언트 계산
z = Xs @ params_newton[1:] + params_newton[0]
p = sigmoid(z)
loss = bce_loss(p, labels)
loss_history_newton.append(loss)
if epoch % 10 == 0:
print(f"에포크 {epoch:3d}: 손실 = {loss:.8f}")
# 그래디언트
gradient = 경사산출(X_aug, labels, p=p)
# 헤시안 (2차 미분)
hessian = hessian_계산(X_aug, p)
# Newton 스텝 계산
try:
# 정규화된 헤시안 (수치 안정성)
hessian_reg = hessian + 1e-6 * np.eye(hessian.shape[0])
step_direction = np.linalg.solve(hessian_reg, gradient)
# 라인 서치: step size α를 조정
alpha = 1.0
params_temp = params_newton - alpha * step_direction
z_temp = Xs @ params_temp[1:] + params_temp[0]
p_temp = sigmoid(z_temp)
loss_temp = bce_loss(p_temp, labels)
# 손실이 감소할 때까지 step size 감소
max_ls_iter = 20
for ls_iter in range(max_ls_iter):
if loss_temp < loss:
break
alpha *= 0.5
params_temp = params_newton - alpha * step_direction
z_temp = Xs @ params_temp[1:] + params_temp[0]
p_temp = sigmoid(z_temp)
loss_temp = bce_loss(p_temp, labels)
params_newton = params_temp
params_history_newton.append(params_newton.copy())
# 수렴 확인
if np.linalg.norm(alpha * step_direction) < 1e-7:
print(f"✓ 수렴 완료: {epoch}번 에포크")
break
except np.linalg.LinAlgError:
print(f"경고: 선형 시스템 풀이 실패 (에포크 {epoch})")
break
# 최종 정확도
z_newton = Xs @ params_newton[1:] + params_newton[0]
p_newton = sigmoid(z_newton)
정확도_newton = np.mean((p_newton > 0.5).astype(int) == labels)
print()
print("=" * 60)
print("수렴 방법 비교")
print("=" * 60)
비교_df = pd.DataFrame({
'방법': ['경사 하강법 (1차)', 'Newton 방법 (2차)'],
'에포크': [205, epoch + 1],
'b': [params_optimized[0], params_newton[0]],
'w1': [params_optimized[1], params_newton[1]],
'w2': [params_optimized[2], params_newton[2]],
'정확도': [정확도_개선, 정확도_newton]
})
display(비교_df.round(4))
print()
print(f"{'속도 향상':<30} {epoch+1 / 205 * 100:.1f}% (원래 경사하강 대비)")
# 손실 수렴 비교 시각화
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 손실 곡선 비교
epochs_gd = np.arange(len(loss_history))
epochs_newton = np.arange(len(loss_history_newton))
axes[0].plot(epochs_gd, loss_history, 'o-', label='경사 하강법 (1차)', linewidth=2, markersize=4, alpha=0.7)
axes[0].plot(epochs_newton, loss_history_newton, 's-', label='Newton 방법 (2차)', linewidth=2, markersize=5, alpha=0.7)
axes[0].set_xlabel('에포크', fontsize=12)
axes[0].set_ylabel('손실', fontsize=12)
axes[0].set_title('손실 수렴 비교', fontsize=13, fontweight='bold')
axes[0].legend(fontsize=11)
axes[0].grid(True, alpha=0.3)
axes[0].set_yscale('log')
# 에포크 수 비교
methods = ['경사 하강법\n(1차 미분)', 'Newton\n(2차 미분)']
epochs_list = [205, epoch + 1]
colors = ['skyblue', 'lightcoral']
bars = axes[1].bar(methods, epochs_list, color=colors, edgecolor='black', linewidth=2)
# 바에 숫자 표시
for bar, ep in zip(bars, epochs_list):
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width()/2., height,
f'{int(ep)}',
ha='center', va='bottom', fontsize=12, fontweight='bold')
axes[1].set_ylabel('필요한 에포크 수', fontsize=12)
axes[1].set_title('수렴 속도 비교', fontsize=13, fontweight='bold')
axes[1].grid(True, alpha=0.3, axis='y')
axes[1].set_ylim(0, 250)
plt.tight_layout()
plt.show()============================================================
Newton 방법 (2차 미분 + 라인 서치)
============================================================
에포크 0: 손실 = 10.83152355
에포크 10: 손실 = 0.04004784
에포크 20: 손실 = 0.00310213
에포크 30: 손실 = 0.00134285
에포크 40: 손실 = 0.00084255
에포크 50: 손실 = 0.00061099
에포크 60: 손실 = 0.00047838
에포크 70: 손실 = 0.00039270
에포크 80: 손실 = 0.00033288
에포크 90: 손실 = 0.00028879
============================================================
수렴 방법 비교
============================================================
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[4], line 95
89 print("수렴 방법 비교")
90 print("=" * 60)
92 비교_df = pd.DataFrame({
93 '방법': ['경사 하강법 (1차)', 'Newton 방법 (2차)'],
94 '에포크': [205, epoch + 1],
---> 95 'b': [params_optimized[0], params_newton[0]],
96 'w1': [params_optimized[1], params_newton[1]],
97 'w2': [params_optimized[2], params_newton[2]],
98 '정확도': [정확도_개선, 정확도_newton]
99 })
100 display(비교_df.round(4))
102 print()
NameError: name 'params_optimized' is not defined